
Fターム[5C164PA43]の内容
双方向TV、動画像配信等 (137,112) | サーバとクライアントで共通する処理 (3,526) | 音声信号に対する処理、変換 (520) | 音声認識、音声検出に関するもの (185)
Fターム[5C164PA43]の下位に属するFターム
音声←→テキスト (76)
音声←→画像(例;手話) (5)
Fターム[5C164PA43]に分類される特許
1 - 20 / 104
情報処理システム、サーバシステム、端末システム、情報処理プログラム、および、情報提示方法
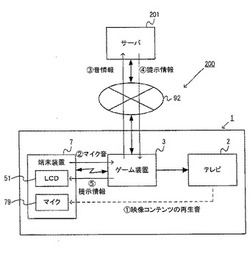
【課題】端末システムに含まれる端末装置において、ユーザにとって有益な情報を提示する。
【解決手段】情報処理システムは、端末装置を含む端末システムと、サーバシステムとを含む。端末システムにおいては、端末装置に設けられるマイクが、周囲の音声を検知する。マイクによって検知された音または当該音の特徴を表す音情報は、サーバシステムへ送信される。サーバシステムにおいては、音情報に基づいて、端末装置の周囲の音が特定される。さらに、端末装置において提示すべき提示情報が、特定された音に基づいて特定され、当該提示情報が情報処理装置へ送信される。端末システムは、サーバシステムから送信されてくる提示情報を受信し、端末装置の表示部に提示情報が表示される。
(もっと読む)
情報処理装置及び情報処理方法、情報提供装置、並びに、情報提供システム

【課題】コンテンツのオーディオ情報から抽出された特徴点情報に基づいてコンテンツの情報を好適に提供する。
【解決手段】クライアント装置140が、副音声を視聴中であっても、主音声からのみ特徴点情報を抽出して、情報提供サーバー150に問い合わせるので、副音声の特徴点情報を用意していない情報提供サーバー150によりACRサービスを実現できる。また、主音声と複数のオーディオ情報を持っているコンテンツが配信されても、情報提供サーバー150側では副音声の特徴点情報を用意する必要がなく、データベースの容量を増やさずに済む。
(もっと読む)
電子装置及びその制御方法
【課題】 本発明の目的は、ユーザの音声及びモーションを認識して効果的に電子装置のタスクを行うための電子装置の制御方法及びそれを適用した電子装置を提供することにある。
【解決手段】 電子装置及び電子装置のUI提供方法が開示される。より詳細には、音声タスクモードで表示される音声認識を通じて制御可能なアプリケーションの短縮アイコンは音声認識を通じて制御不可なアプリケーションの短縮アイコンと区別できるように表示する電子装置及び電子装置のUI提供方法を開示される。開示される実施形態の一部は、音声認識及びモーション認識が可能であり、音声タスクモードで表示される音声認識を通じて制御可能なアプリケーションの短縮アイコン及び短縮アイコンの名前は、音声認識を通じて制御不可なアプリケーションの短縮アイコン及び短縮アイコンの名前と区別できるように表示する電子装置及び電子装置のUI提供方法を提供する。
(もっと読む)
マスメディアのソーシャル及び相互作用的なアプリケーション
【課題】リアルタイム環境音及び/又はビデオ特定をベースとするソーシャル及び相互作用的なアプリケーションを提供する。
【解決手段】システム、方法、装置、ユーザインターフェース及びコンピュータプログラム製品は、リアルタイム環境音及び/又はビデオ特定をベースとするマスメディアのソーシャル及び相互作用的なアプリケーションを提供する。いくつかの実施では、方法は、メディア放送に関連付けられた環境音を特定する記述子を受信する段階と、前記記述子を1つ又は複数の基準記述子と比較する段階と、前記比較の結果を少なくとも部分的にベースとして、前記メディア放送のレーティングを決定する段階と、を具備する。
(もっと読む)
情報提供システムおよび携帯端末装置
【課題】音響による識別情報を用いて、ユーザが使用する携帯端末装置に放送に関連した情報を表示することで更なる情報の取得を容易にした情報提供システムを提供する。
【解決手段】放送再生装置は、識別情報が重畳された放送音声を放音する。識別情報解決サーバは、時間帯別にコンテンツのアドレス情報を記憶した識別情報/アドレス情報対応テーブルを有し、携帯端末装置から識別情報を受信した受信時の時刻情報を用いてテーブルを検索し、対応するコンテンツのアドレス情報を返信する。携帯端末装置は、放送再生装置が放音した放送音声を収音する収音部、収音した放送音声から識別情報を復調する復調部、ユーザによる操作を受け付ける操作部、操作部が操作されたとき識別情報を識別情報解決サーバに送信してアドレス情報を取得する識別情報解決部、および、取得したアドレス情報を用いてコンテンツにアクセスするコンテンツアクセス部を備える。
(もっと読む)
TV会議システム
【課題】顔領域の抽出や音場制御技術等を活用したTV会議システムを提供する。
【解決手段】自装置側の画像を撮影する撮影手段と、撮影手段により撮影した画像から、顔領域の位置、各顔領域の画面注視度および各顔領域の顔の向きを求める画像処理手段と、画像、顔領域の位置および各顔領域の画面注視度を対向装置側に送信する画像情報送信手段と、対向装置側から、対向装置側において撮影した画像、対向装置側の顔領域の位置および各顔領域の画面注視度を受信する画像情報受信手段と、受信した画面注視度の高い各顔領域について、自装置側の顔領域の顔の向きから、対向装置側の顔領域の位置のうち注視されている顔領域を推定し、画像を表示する際に、顔領域の位置のうち、注視されている顔領域以外で、かつ画面注視度が低い顔領域の位置にぼかし処理を施すぼかし手段と、ぼかし処理を施した表示するべき画像を表示する表示手段とを備えた。
(もっと読む)
ポータブル端末、ペアリングシステム、ペアリング方法
【課題】AV機器と、AV機器と連携・制御するコントローラとを紐付ける場合、コントローラを操作するユーザの位置に応じて、ユーザの近くにあるAV機器をユーザが選択する必要があった。
【解決手段】コントローラ2は、音声入力部(マイクロホン)により取得した音声から生成した音声特徴情報(音声指紋)もしくは音声特徴情報から特定したコンテンツ情報と、通信部により取得した各機器の音声特性情報もしくは音声特徴情報から特定したコンテンツ情報とから近接している機器を特定し、紐付けを行う。
(もっと読む)
テレビジョン装置及び遠隔操作装置
【課題】 音声認識で操作するテレビジョン装置において、音声認識中に出力音声をミュートする機会を必要最小限に抑える。
【解決手段】 ユーザによる音声認識開始の指示の入力を受けてから、音声認識処理が終わるまでの間、出力音量の設定値を一時的に閾値以下の値に変更する。
(もっと読む)
遠隔地間コミュニケーション装置、遠隔地間コミュニケーション方法、プログラム
【課題】プライバシーレベルの判別制御を、特殊なハードウェアを必要とせず低コストで実現できる遠隔地間コミュニケーション装置を提供する。
【解決手段】マイクロホン入力信号を取得して有音であるか無音であるかを判定する音レベル判定部と、マイクロホン入力信号を取得して物音であるか音声であるかを判定する音周期性判定部と、音レベル判定部の判定結果および音周期性判定部の判定結果を取得して、音レベル判定部の判定結果が無音である場合には無音と判定し、音レベル判定部の判定結果が有音であって音周期性判定部の判定結果が物音である場合には物音と判定し、音レベル判定部の判定結果が有音であって音周期性判定部の判定結果が音声である場合には音声と判定する結果判定処理部とを備える。
(もっと読む)
立体画像処理装置
【課題】3D映像の奥行き感に合わせて字幕を表示することができる。
【解決手段】デマルチプレクサ部11により映像ストリーム、字幕の符号化されたストリームを抽出し、映像デコード部12により映像ストリームを複合し、左右の映像データを生成し、字幕デコード部13により字幕ストリームを複合して文字列データや位置データを抽出し、映像視差抽出部14により左映像データと右映像データとの比較を行い、その映像の視差量データを抽出し、字幕視差設定部15により、映像の視差量データから映像中の人物像の奥行き方向の位置を判定し、該奥行き方向の位置に応じて字幕データの奥行き方向の位置を設定し、映像表示制御部16により左右の映像データと字幕データとの重ね合わせを行い、生成された左右の映像データから3D映像を生成する。
(もっと読む)
情報理装置および方法、プログラム、並びに情報処理システム
【課題】ユーザが、他の多くのユーザのコンテンツに対する反応をリアルタイムで知ることができるようにする。
【解決手段】クライアント11はコンテンツを取得して再生するとともに、コンテンツの各場面に対するユーザの反応として発せられた音声を収音し、サーバ12に送信する。サーバ12は、各クライアント11から受信した音声を、各ユーザの仮想会場における位置と音響特性に基づいて加工して加算し、反応音声を生成する。この反応音声は、サーバ12から各クライアント11に送信され、再生される。これにより、コンテンツを視聴するユーザは、他の多くのユーザのコンテンツに対する反応音声をリアルタイムで知ることができ、他のユーザと感動等の感情を共有することができる。本発明は、テレビジョン受像機に適用することができる。
(もっと読む)
自動番組送出装置
【課題】自動番組送出装置に於ける無音事故の際に、緊急放送の時間を最小限に留め、次の番組やコマーシャルを確実に放送する無音事故防止機能を有する自動番組送出装置を提供する。
【解決手段】自動番組送出装置に無音検出装置の無音検知出力を入力し、自動番組送出装置は無音状態が一定時間継続したら、音声切り替え器を制御して緊急放送音源を放送する。一定期間正常レベルが続いたら正常放送に戻す。但し無音状態でも次の番組やコマーシャルの放送時刻になったら正常放送に戻す。
(もっと読む)
音声通信システム、及び、音声通信装置
【課題】 遠隔会議システム等における音声通信装置において、話し手が、聞き手の受聴環境を理解し、話し手の音声が聞き手にどのように聞こえているかを認識することは困難であった。
【解決手段】 聞き手側の音声通信装置で環境音響特性を計測し、その環境音響特性の情報を話し手側の音声通信装置に送信し、話し手側の音声通信装置では、受信した環境音響特性の情報を利用して、マイク等の音声入力装置から入力された音声信号を変換し、話し手側の出力装置から音声出力を行う。
(もっと読む)
ビューイングシステム、携帯端末、サーバ、ビューイング方法
【課題】ユーザが文字入力をすることなく、他ユーザと番組の内容について簡易的(擬似的)に共感すること。
【解決手段】本発明のビューイングシステムにおいて、複数の携帯端末の各々は、表示部と、ワンセグ放送の番組を受信する番組受信部と、前記番組受信部で受信された番組を前記表示部の表示画面に表示する表示制御部と、前記表示画面への番組の表示中における自端末周辺の話者の音声を集音するマイクと、前記マイクで集音された話者の音声を文字データに変換する音声認識部と、前記音声認識部で変換された文字データを前記サーバに送信するとともに、他の携帯端末から前記サーバに送信された文字データを、前記サーバから受信する文字データ送受信部と、を有し、前記表示制御部は、前記表示画面への番組の表示中に、該表示画面に、前記サーバから受信した文字データを併せて表示する。
(もっと読む)
情報処理装置、情報処理方法、およびプログラム
【課題】コンテンツの視聴中に流れた曲の情報をより確実に検索することができるようにする。
【解決手段】TV1はリングバッファを有しており、番組のオーディオデータの常時記録を行っている。TV1は、番組の視聴中に流れている曲に関する情報の検索がユーザにより指示された場合、リングバッファに記録しているオーディオデータを解析し、特徴データを生成する。TV1は、生成した特徴データを検索サーバ2に送信して曲情報の検索を要求する。検索サーバ2は、TV1から送信されてきた特徴データと、予め管理しているそれぞれの曲の特徴データとをマッチングし、曲情報の検索が指示されたときに流れていた曲を特定する。検索サーバ2は、特定した曲の曲情報をTV1に送信する。TV1は、検索サーバ2から送信されてきた曲情報の内容を表示する。本発明はTVに適用することができる。
(もっと読む)
映像再生装置及び映像再生プログラム
【課題】映像情報に含まれる音声情報に関連する内容の資料情報を映像情報とともに再生する映像再生装置及び映像再生プログラムを提供する。
【解決手段】映像再生装置1Aは、映像情報に含まれる音声情報から語彙を抽出する語彙抽出手段102と、語彙抽出手段102が抽出した語彙に基づいて当該語彙に関連する内容を有する資料情報を読み出す資料情報読出手段104と、映像情報を再生することで表示される映像のうち、語彙が抽出された音声情報の再生時刻の映像と、資料情報読出手段104に読み出された資料情報を再生することで表示される資料とを合成して合成映像を生成する合成映像生成手段105とを有する。
(もっと読む)
携帯端末、情報処理方法及びコンピュータプログラム
【課題】非接触通信を行うシステムの内部に複数の装置が存在する場合に、適切な装置を自動的に選択することで非接触通信による返信を適切に行うことが可能な携帯端末を提供する。
【解決手段】外部の通信装置との間で非接触通信を行う非接触通信部と、通信装置との間で授受される情報を記憶する複数の記憶部と、通信装置との間の通信制御及び複数の記憶部から通信装置へ情報を送信する際の優先順位を設定する制御部と、を備え、制御部は、現在時刻に応じて複数の記憶部の優先順位を設定する、携帯端末が提供される。これにより、非接触通信を行うシステムの内部に複数の装置が存在する場合に、適切な装置を自動的に選択することで非接触通信による返信を適切に行うことが可能となる。
(もっと読む)
通話装置
【課題】聞き手の画面に映すアバターの位置を移動させたり、話し手が複数の場合に、話している人に対応してアバターのみ口パクをさせることを可能とする。
【解決手段】人物の映像をアバターを用いて送信する通信装置であって、音声を入力する複数の音声入力手段と、前記音声入力手段に入力される、音声の到達時間や音声のゲインに基づいて、音声が入力された位置を判別する音声解析手段と、アバターを生成する生成手段と、前記音声解析手段により判別した音声が入力された位置に対応して、前記生成手段により、音声が入力された位置にあわせてアバターを生成する。
(もっと読む)
番組コンテキストに基づくモバイルコンテンツの提示
【課題】クライアントデバイスで音声サンプルを取得することに対応して検索クエリを生成する方法、システム、及び装置をコンピュータ記憶メディア上の符号化されたコンピュータプログラムを含めて提供する。
【解決手段】一態様で、一方法は、i)クライアントデバイスから音声データを受取る挙動と、ii)受取られた音声データに基づいて、取込まれたメディアから特定のコンテンツを識別する挙動とを含み、識別された特定のコンテンツは受取られた音声データと関連付けられ、取込まれたメディアは音声メディア又は音声映像メディアのうちの少なくとも一方を含み、iii)識別されたコンテンツと関連する追加メタデータを取得する挙動と、iv)取得された追加メタデータに少なくとも一部は基づく検索クエリを生成する挙動と、v)検索クエリに対応する、かつ受取られた音声データと関連する1つ又は複数の検索結果をクライアントデバイスに返す挙動とを含む。
(もっと読む)
ビデオ会議に翻訳を追加するための方法及びシステム
【課題】会議参加者の発話を所望の1又は複数の言語にリアルタイム翻訳する多言語多地点ビデオ会議システムを提供する。
【解決手段】発話を含む音声ストリームがテキストに変換され(220,250)、ビデオストリームに字幕として挿入される(250,240)。発話は或る言語から別の言語に翻訳され(240)、翻訳された発話がビデオストリームに挿入され、字幕を選ぶか、又は、音声合成エンジンによって生成された別の言語の発話に、元の音声ストリームを置き換える(220,240,250)。種々の会議参加者は、それぞれ会議参加者により提供された所望の言語の情報に基づく同じ発話の種々の翻訳を受信する(210)。
(もっと読む)
1 - 20 / 104
[ Back to top ]