
Fターム[5D015AA03]の内容
Fターム[5D015AA03]に分類される特許
101 - 120 / 293
本人認証システム
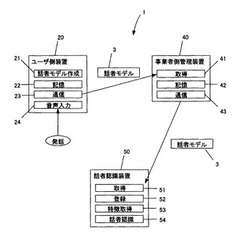
【課題】事業者が話者認識によりユーザの本人認証を行うシステムにおいて、取引先の事業者ごとにユーザが都度発話による話者モデルの登録を行う必要のないシステムを提供する。
【解決手段】ユーザ側装置20は音声入力手段24、話者モデル作成手段21、記憶手段22、話者モデルを転送する通信手段23を備え、事業者側の管理装置40は話者モデルの取得手段41、記憶手段42、通信手段43を備え、事業者側の話者認識装置50は話者モデルの取得手段51、話者モデル登録手段52、特徴取得手段53、話者認識手段54を備え、ユーザはユーザ側装置20を用いて話者認識に用いる話者モデルを作成して保持し、事業者はユーザを取引先として登録する際に、管理装置40を用いて取引に必要な個人情報とともに話者モデルをユーザから取得し、話者認識装置50において話者モデルを登録する。
(もっと読む)
音声認識装置

【課題】発話者を特定しながら音声認識性能を向上させる音声認識装置を提供すること。
【解決手段】発話者が発する音声を認識する音声認識装置100は、発話者を特定する発話者特定手段11と、特定した発話者に応じて音声認識特性を調整する音声認識特性調整手段12とを備える。音声認識特性調整手段12は、特定した発話者に応じて、マイク感度、声域フィルタで除去する周波数帯域、方言認識辞書、又は、頻出語彙認識辞書を切り換えるようにする。音声認識装置100は、音声から声紋データを取得する音声認識手段10を備え、発話者特定手段11は、予め登録された声紋データと音声認識手段10が取得した声紋データとを照合して発話者を特定する。
(もっと読む)
音声処理装置、音声処理システム及び音声処理プログラム
【課題】同時発話が発生しても、話者毎に発話内容を明確に再生すること。
【解決手段】信号処理部4は、複数の音声データより話者を特定する話者特定部42と、話者特定部42によって少なくとも第1及び第2の話者を特定した場合に、特定された第1及び第2の話者が発話した発話区間を特定し、第1及び第2の話者が同時に発話した区間を同時発話区間として判定する同時発話区間判定部43と、を備える。また、信号処理部4は、同時発話区間判定部43で判定された同時発話区間の第1の話者の音声データと第2の話者の音声データとを分離し、分離された各話者の音声データをそれぞれ時間的に異なるタイミングとして出力させる整列部45と、を備える。
(もっと読む)
情報管理装置、情報管理システム、及びプログラム
【課題】表示情報に対して、利用者が注目している情報と利用者の音声とを容易に対応付けて格納することができる装置を提供する。
【解決手段】文書データ又は画像データの少なくとも一方を含む表示情報を格納する格納部と、格納部が格納した表示情報を表示する表示部と、利用者の視線を検出する視線検出部と、利用者の視線に基づいて、表示部に表示された表示情報のうち、利用者が注目している注目情報を検出する注目情報検出部と、利用者の音声を検出し、音声を注目情報に対応付けて格納部に格納する音声検出部とを備える情報管理装置を提供する。
(もっと読む)
音声入出力装置
【課題】 ビデオカメラ等の音声入出力装置において、撮影者が音声入力装置に一番近い位置にいるため、被撮影者よりも音量が大きく記録・再生されるという問題があった。この問題をユーザーの手間やコストを掛けることなく解決すること。
【解決手段】 入力された音声データに対し、データベースとの音声認識を行い、音声認識の結果に応じてアナログアンプまたはデジタルアンプにより音量を制御する、または、音声認識の結果に応じてフィルタリング処理を行なう、または、音声認識された後、相関性算出の結果に応じて指向性制御を行なうことで音量が大きい撮影者の音声などの特定の音声に関して音量を下げることを可能とする。
(もっと読む)
話者認証の登録及び評価のための方法及び装置
【課題】話者認証の登録及び評価のための方法と装置、話者認証システムを提供すること。
【解決手段】話者認証の登録のための方法は、話者によって話された同一内容の複数の発話の各々に基づいて複数の音響特徴ベクトル系列を生成するステップと、前記複数の音響特徴ベクトル系列から参照テンプレートを生成するステップと、複数のコード及び前記複数のコードに対応する特徴ベクトルを含むコードブックに基づいて、前記複数の音響特徴ベクトル系列の各々に対応する擬似詐称者特徴ベクトル系列を生成するステップと、前記複数の音響特徴ベクトル系列、前記参照テンプレート及び前記複数の擬似詐称者特徴ベクトル系列に基づいて最適な音響特徴サブセットを選択するステップと、を含む。
(もっと読む)
オンライン話者逐次区別システム及びそのコンピュータプログラム
【課題】オンラインで動作可能でレイテンシの低い発話逐次区別システムを提供する。
【解決手段】話者区別システム30は、話者GMM74−78を記憶する記憶部42と、音声データをセグメント化する音声活動検出部30と、現セグメントが話者GMM74−78のいずれにも属していないかを判定する新規性判定部34と、現セグメントが話者GMM74−78のいずれにも属していないときに、新たな話者GMMを生成し、現セグメントを新たな話者GMMでラベル付けする新モデル生成部40と、現セグメントが話者GMM74−78の1つに属しているときに、話者を識別し、現セグメントをその話者でラベル付けする話者識別部44と、現セグメントを利用して話者GMMをトレーニングするトレーニング部48と、音声活動検出部30が出力したセグメントのシーケンスに従ってセグメントラベルをマージするマージ部46とを含む。
(もっと読む)
音声認識装置
【課題】処理負荷やコストの大幅な増大を招くことなく、制御機器をより適切に制御することが可能な音声認識装置を提供する。
【解決手段】音声認識装置10は、ユーザからの発話音声を入力し、入力した発話音声が予め登録された登録語彙に該当すると認識した場合に、その登録語彙に基づいて制御機器20を制御するもので、登録語彙を記憶した登録語彙記憶部12aと、登録語彙がどの話者によって発話されたかを識別するための複数の音声モデルを記憶した音声モデル記憶部12bと、ユーザによる登録語彙の発話音声が入力された場合に複数の音声モデルから登録語彙がどの話者によって発話されたかを識別する音声認識部13と、登録語彙が特定の話者によって発話された場合と他の話者によって発話された場合とで登録語彙に基づく制御機器20への制御内容を異ならせる制御機器制御部14と、を備えている。
(もっと読む)
画像形成装置
【課題】 ファクシミリを受信した際の処理を、送信者ごとに変更可能な電子メール機能を備える画像形成装置を提供する。
【解決手段】 この画像形成装置は、複数のユーザの声紋情報と各ユーザにつき登録された画情報ファイルの処理内容とを記憶する記憶手段44、46と、受信した電子メールに音声ファイルが添付されているか否かを識別する添付ファイル識別手段41と、音声ファイルに含まれる音声から声紋を抽出する声紋抽出手段42と、抽出された声紋を、記憶手段46に記憶された複数のユーザの声紋情報と照合する声紋照合手段43とを含み、抽出された声紋が複数のユーザのいずれかの声紋情報に一致する場合に、一致するユーザにつき登録された画情報ファイルの処理内容に基づき処理を実行する。
(もっと読む)
議事録作成装置、議事録作成システム、議事録作成方法および議事録作成プログラム
【課題】 参加者ごとに発話した内容を容易に関連付けること。
【解決手段】 MFPは、ユーザを識別するためのユーザ識別情報を、会議の参加者を示す参加者情報として取得する参加者情報取得部(S03)と、会議の参加者が発話する音声を取得する音声取得部(S04)と、取得された参加者情報で識別されるユーザのうちから取得された音声を発話したユーザを特定する話者特定部(S05)と、取得された音声を文字情報に変換する音声変換部(S06)と、変換された文字情報を判別されたユーザの参加者情報と関連付ける関連付部(S07)と、を備える。
(もっと読む)
音声処理装置およびプログラム
【課題】入力音が非人声を含む場合でも男声と女声とを適切に区別する。
【解決手段】記憶装置24は、複数の男性の発声音から生成された男性話者モデルMMと複数の女性の発声音から生成された女性話者モデルMFとを記憶する。男声指標算定部52は、入力音VIN(音声信号SIN)と男性話者モデルMMとの類否を示す男声指標値LM0を算定する。女声指標算定部54は、入力音VINと女性話者モデルMFとの類否を示す女声指標値LF0を算定する。判別部62は、入力音VINを人声と非人声とに判別し、人声と判別した場合には男声指標値LM0と女声指標値LF0とに基づいて入力音VINを男声と女声とに判別する。
(もっと読む)
音声処理装置及び方法
【課題】入力される音声を適切に処理し、音源認識、話者認識または音声認識を精度良く行う音声処理装置を提供する。
【解決手段】第1音源100より発生された音声を受信して複数チャネルの第1音声信号を出力する複数のマイクロホン101と;前記チャネル間の相関を示す第1特徴量を算出する算出部110と;第2音源より発生された音声を前記複数のマイクロホン101により受信して得られる複数チャネルの第2音声信号のチャネル間の相関を示す第2特徴量を予め記憶している記憶部120と;前記第1特徴量と前記第2特徴量を照合し、前記第1音源100が前記第2音源に一致するか否かを判定する照合部102と;を具備する。
(もっと読む)
情報処理装置、および情報処理方法、並びにコンピュータ・プログラム
【課題】不確実で非同期な入力情報に基づく情報解析により、精度の高いユーザ位置およびユーザ識別情報を効率的に生成する構成を実現する
【解決手段】カメラやマイクによって取得される画像情報や音声情報に基づいてユーザの推定位置および推定識別データを含むイベント情報を入力して、複数ターゲットを設定した複数パーティクルを適用したパーティクルフィルタリング処理を行い仮説の更新取捨選択によりユーザ位置および識別情報を生成する。また、カメラの画像フレーム外に仮想ターゲットを設定した暫定ターゲットとイベント検出部の生成するイベント情報との尤度を検証し、検証結果に応じて暫定ターゲットを各パーティクルに追加する。本構成により、フレーム外ユーザの音声入力に対応した処理が可能となり、ユーザ位置や識別の正確な推定処理が実現される。
(もっと読む)
営業支援システム、営業支援方法及び営業支援プログラム
【課題】顧客からの預かり物件を効率的に管理するための営業支援システム、営業支援方法及び営業支援プログラムを提供する。
【解決手段】携帯端末10から音声データを受信した営業支援サーバ20は、話者照合認証処理を実行する。認証ができた場合、営業支援サーバ20は、訪問情報を携帯端末10から取得する。そして、この訪問情報に応じて辞書を選択する。携帯端末10から音声データを受信した営業支援サーバ20は、この辞書を用いて、音声認識処理を実行する。そして、携帯端末10から預かり物件情報を取得して記録する。一方、帰店通知を受信した営業支援サーバ20は、ユーザ認証を行ない、預かり物件を抽出する。そして、顧客別預かり一覧及び回付用伝票の印刷データを生成し、プリンタ装置31において、顧客別預かり一覧及び回付用伝票の印刷を実行する。
(もっと読む)
音声処理装置およびプログラム
【課題】発声者の位置が変化した場合における音声認識の精度の低下を抑制する。
【解決手段】位置特定部14は、音声信号Sから各発声者の方向jを特定する。話者識別部16は、音声信号Sが表わす各音声の発声者を区別する。適応モデル生成部24は、位置特定部14が適応用の音声信号S1から特定した方向jと話者識別部16が音声信号S1から区別した発声者との組合せに対応した音響モデルMを音声信号S1に応じて生成する。音声認識部26は、位置特定部14が認識用の音声信号S1から特定した方向jと話者識別部16が音声信号S2から区別した発声者との組合せに対応した音響モデルMに基づいて、音声信号S2が表わす音声に対応した文字を特定する。
(もっと読む)
音声処理装置およびプログラム
【課題】音声信号を区分した複数の区間を正確に発声者ごとに分類する。
【解決手段】特徴抽出部41は、音声信号Sを時間軸上で区分したN個の区間Bの各々について特徴量を抽出する。指標算定部43は、N個の区間Bのなかから2個の区間Bを選択する総ての組合せについて、2個の区間Bにおける特徴量の類否を示す類否指標値を算定する。音声分類部45は、N個の区間Bの各々と当該区間Bに特徴量が最も類似する区間Bとが同じクラスタに属するように、各区間の類否指標値に基づいてN個の区間Bを複数の集合に分類する。
(もっと読む)
話者特定装置及び音声認識装置並びに話者特定用プログラム及び音声認識用プログラム
【課題】話者特定処理に必要な計算量や記憶容量等を最小限に抑制しつつ、且つ、話者特徴情報の更新の進行態様に柔軟に対応させて適切に類似度閾値を更新させることで、話者特定における正確性をより向上させることが可能な話者特定装置を提供する。
【解決手段】話者による発話の音響的特徴を示す話者モデルと、当該話者の発話に相当する特徴量信号Soと、を比較し、それらの間の類似度を検出すると共に、検出された類似度と、当該類似度の検出の際に比較された類似度閾値と、を比較して話者特定を行う話者認識部5と、特徴量信号Soを用いて話者モデルを更新するパラメータ更新部8と、類似度閾値を、検出された類似度を用いて更新する閾値設定部6と、を備える。
(もっと読む)
オーディオ信号記録装置、電子ファイル
【課題】オーディオ信号の記録方式に対してプライバシーを保護する仕組みを導入する。
【解決手段】オーディオ信号記録装置は、入力された元オーディオ信号の全区間から人の音声の信号成分を含む音声区間を検出して、前記音声区間における信号に対して暗号化処理を施すことにより、前記元オーディオ信号から暗号化オーディオ信号を生成する。そして、前記暗号化オーディオ信号と、前記暗号化オーディオ信号を復号するための復号用情報と、前記復号用情報に従った前記暗号化オーディオ信号の復号及び前記元オーディオ信号の再生出力に対する許可/禁止を再生装置側で切替制御させるための権限管理情報と、を互いに関連付けて電子ファイルに格納する。
(もっと読む)
相手認証機能を有するドアホンシステム及び相手判定方法
【課題】 来訪者の認証情報を取得した際、被来訪者にとって迎え入れたい来訪者の来訪の場合のみ、その来訪を被来訪者へ知らせることが出来る相手認証機能を有するドアホンシステムを提供する。
【解決手段】 ドアホン親機と連動する又はドアホン親機の機能を内蔵する主装置と、前記ドアホン親機又は前記主装置に帰属するドアホン子機と、玄関ドアの開閉を検出する玄関ドアセンサを含むドアホンシステムであって、前記主装置は、前記ドアホン子機から受信した来訪者認証情報が好ましくない来訪者の認証情報として前記来訪者認証情報蓄積手段に蓄積されていると共に、当該来訪者の来訪時の応答処理内容が来訪拒否であった場合、前記被来訪者への呼出動作を開始しないことを特徴とする。
(もっと読む)
操作システム及び操作システムの制御方法
【課題】操作端末と装置で構成された操作システムにおいて、音声認識した操作命令の内容をユーザが確実に確認できるようにする。
【解決手段】操作端末から入力した音声の操作命令で装置を動作させる操作システムにおいて、前記入力した音声を認識し、認識した音声が予め定めた操作命令に該当するか否かを識別する音声認識手段と、前記音声認識手段が予め定めた操作命令に該当すると識別した場合に、前記入力した音声に対応する操作命令の内容を示した命令実行確認画面を表示する表示制御手段とを備え、操作命令の実行前にユーザが視覚で確認できるようにした。
(もっと読む)
101 - 120 / 293
[ Back to top ]