
Fターム[5D015AA03]の内容
Fターム[5D015AA03]に分類される特許
41 - 60 / 293
歌声の特徴に基づいて顧客を特定して顧客の個人情報に基づくメッセージを出力する通信カラオケシステム
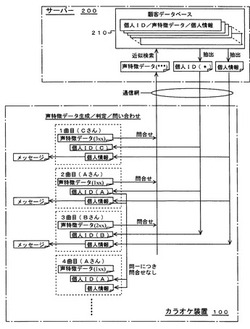
【課題】複数のカラオケ装置が通信網を介してデータベースサーバーに接続される通信カラオケシステムにあって、顧客の歌声の特徴に基づいて顧客を特定して顧客の個人情報に基づくメッセージを出力するというサービスを、システムの処理負担および通信負荷が過大にならないように効率良く実行させる。
く作成させる。
【解決手段】データベースサーバー200は、顧客の個人情報と、顧客の声特徴データを対応付けて集約した顧客データベース210を備え、カラオケ装置100は、歌声信号を分析して声特徴データを生成し、生成した声特徴データが、直近の所定期間に生成・記録されていない場合は、上記声特徴データベース210に問い合わせて対応する個人情報を取得し、この個人情報に基づいてメッセージを作成して顧客に向けて出力する。
(もっと読む)
歌声の特徴に基づいて顧客別の歌唱履歴を自動的に作成する通信カラオケシステム

【課題】顧客がカラオケ楽曲を歌唱する際に、その顧客が歌唱の度に個人ID等を入力する面倒を行わなくても、データとしての使い勝手が良好で、カラオケ利用者へのサービス提供に利用する情報としての利便性が高い顧客別歌唱履歴を、カラオケ装置ごとに自動的に効率良く作成させる。
【解決手段】データベースサーバー200は、顧客の個人IDと、顧客の声特徴データを対応付けて集約した声特徴データベース210を備え、カラオケ装置100は、歌声信号を分析して声特徴データを生成し、生成した声特徴データが、直近の所定期間に生成・記録されていない場合は、上記声特徴データベース210に問い合わせて対応する個人IDを取得し、この個人IDを楽曲IDと演奏日時に対応付けて顧客別演奏履歴を作成・記録する。
(もっと読む)
歌声の特徴に基づいて顧客別の歌唱履歴を自動的に作成する通信カラオケシステム
【課題】顧客がカラオケ楽曲を歌唱する際は、その顧客が歌唱の度に顧客IDを入力する面倒を行わなくても、その顧客の歌唱履歴を自動的に記録させることができる一方、そのデータベースの記録データを活用するサービスを提供する際には、そのデータベースに記録された歌唱履歴の検索を少ない処理負担で高速に行うことを可能にする。
【解決手段】データベースサーバー200は、カラオケ装置100から楽曲ID・歌唱日時・声特徴データの情報セットを受信し、受信した声特徴データに最も近似する声特徴データを声特徴データベース210から検索し、該当する顧客IDを抽出し、抽出した顧客IDに基づいて、顧客データベース220における該当の歌唱履歴に、受信した楽曲IDと歌唱日時の記録を追記する。
(もっと読む)
情報処理装置、情報漏洩防止方法およびプログラム
【課題】 他者の存在を検知し、情報漏洩を防止することができる情報処理装置を提供する。
【解決手段】 この情報処理装置は、入力された音声の音響分析を行い、その音声の特徴量を、各話者に対応してデータ記憶部42に格納された音響特徴を表現する音響モデルと照合して、指定された話者の音声であるかを識別する話者識別部40と、指定された話者の音声でないと識別された場合に、情報処理装置が行っている処理に対して制限を及ぼし、少なくとも表示部43の表示内容を変更させる制限部41とを備える。話者識別部40は、所定の周囲の騒音も識別することができ、制限部41は、その騒音を識別した場合に、制限を及ぼすことができる。
(もっと読む)
本人認証装置および本人認証方法
【課題】 少ないシステムの処理工数で本人認証結果の精度を高くできる本人認証装置を提供する。
【解決手段】 本人認証装置1は、入力されたユーザの音声認証用音声データとユーザの音声認識用音声データをそれぞれデジタル変換した第1音声データと第2音声データを含むテーブルを予め記憶する記憶装置と、端末および通信回線を介して入力されたユーザの認証用音声データをデジタル変換したデジタルデータと前記テーブル中の対応する第1音声データを比較し前記ユーザの認証用音声データを認証する音声認証サーバ3と、端末および通信回線を介して入力されたユーザの認証用音声データをデジタル変換したデジタルデータと前記テーブル中の対応する第2音声データを比較し前記ユーザの認証用音声データを音声認識する音声認識サーバ4とを備える。
(もっと読む)
話者照合装置、話者照合方法およびプログラム
【課題】高精度な話者照合を行うことができる話者照合装置を提供する。
【解決手段】話者照合装置1は、入力された音声データが分割された音声区間の音声の特徴量と、複数の話者の音声データに基づいて予め生成されている音声の特徴量との類似度を音声区間毎に算出する類似度算出部38と、前記算出された類似度が低い音声区間を照合用の区間として特定する照合区間特定部40とを有する。話者照合装置1は、入力された音声データのうち、話者性が含まれる可能性の高い音声区間を特定する。
(もっと読む)
音声メッセージシステムによる発呼者の認識
【課題】 従来技術の音声メッセージイング・システムの欠点を改良する。
【解決手段】 発呼者の真正な同一性を決定するために、加入者のグリーティングの音声分析を使用する。加入者によりグリーティングが録音された(例えば、加入者が、ボイスメール・システムの決まり文句のグリーティング若しくは習慣的グリーティングの一部としてその喋り声を発声する)場合、システムはグリーティングを分析し、そして、グリーティングの音声署名又は声紋を作成できる。この声紋分析はシステム内に記憶され、そして、加入者と関連づけられる。加入者が声紋を作成するために以前に分析したグリーティングを変更する場合、メッセージイング・システムは場合により、加入者の新たな声紋を作成するために、新たに録音されたグリーティングを分析することもできる。そして、システムは将来の認識タスクのためにシステム内に新たな声紋を記憶する。次いで、この声紋は音声メッセージを残した発呼者の同一性を識別するために使用される。
(もっと読む)
音声処理装置およびプログラム
【課題】高精度な話者認識を実現し得る特徴量を提案する。
【解決手段】特徴抽出部32は、音声信号Vのうち所定の周波数fcを上回る成分について自己相関数列AVを特徴量FVとして算定する。自己相関数列AVは、音声信号Vの自己相関値a(m)の系列(時系列)である。記憶装置24は、参照用の自己相関数列AREFを記憶する。話者認識部34は、音声信号Vの自己相関数列AVと参照用の自己相関数列AREFとの比較で話者認識を実行する。
(もっと読む)
生体情報認証装置
【課題】
決められた語句を用いる話者認識において、ノイズに対して堅牢性のある話者認識装置を提供する。
【解決手段】
生体情報を用いて認証を行う生体情報認証装置において、第1の生体情報を予め記憶した記憶部と、第2の生体情報を入力する入力部と、記憶部に記憶された第1の生体情報の特徴量と入力部により入力された第2の生体情報の特徴量とを比較し、比較結果に応じて認証結果を出力する演算部と、を備える。演算部は、第1の生体情報のフラクタル次元と第2の生体情報のフラクタル次元とを比較し、比較結果に応じて認証結果を出力する。
(もっと読む)
会話グループ把握装置、会話グループ把握方法、及びプログラム
【課題】どの構成員同士で会話を行っているのかを把握する会話グループ把握装置を提供する。
【解決手段】組織を構成する構成員の位置において取得された音データを、構成員ごとに受け付ける受付部11と、受付部11が受け付けた音データを蓄積する音データ蓄積部12と、音データ蓄積部12が蓄積した構成員ごとの音データ間の類似性に関する情報である類似情報を算出する類似情報算出部15と、類似情報算出部15が算出した類似情報を用い、類似性の高い複数の音データにそれぞれ対応する複数の構成員の構成員識別情報を有する会話グループ情報を蓄積する会話グループ情報蓄積部16と、を備える。
(もっと読む)
携帯端末、認証方法およびプログラム
【課題】受信者側の情報を守りながら、発信者を認証する。
【解決手段】通話中に受信部102が受信した通話相手の音声から音声の声紋データである認証声紋データを声紋データ作成部103が作成し、通話相手を識別可能な利用者識別情報と通話相手の声紋データである登録声紋データとをあらかじめ対応付けて記憶するメモリ101の中に、認証声紋データと一致する登録声紋データが記憶されている場合、登録声紋データと対応付けられている利用者識別情報をメモリ101から利用者識別情報読み出し部104が読み出し、読み出した利用者識別情報を表示部105が表示し、通話を開始してから利用者識別情報を表示するまでの間、集音制御部106が当該携帯端末に具備された集音機能を無効にする。
(もっと読む)
ハンズフリー通話装置、及び該装置の音声補正方法
【課題】発音者の音声の特徴を得て、発音者を特定するハンズフリー通話装置、及び該装置の音声補正方法を提供する。
【解決手段】発音者の音声から発音者の音量特徴及び音質特徴を予め抽出するサンプリング部(44)と、抽出した音量特徴及び音質特徴から発音者に応じた補正条件を予め設定する一方、抽出した音量特徴及び音質特徴と通話者の音声とを比較して当該通話者を特定し、補正条件に基づいて当該通話者の補正音声を出力する補正部(48)とを具備する。
(もっと読む)
認証装置
【課題】多様性の影響が小さくて認証精度が高い認証装置を提供する。
【解決手段】中央演算処理装置と、入力部と、形状主成分、テクスチャ主成分及び母音(あ、い、う、え、お)又は撥音(ん)の特徴量を表すパラメータが関係付けられたデータベース並びに第1の文字列を含む記憶装置と、出力部とを備え、中央演算処理装置は、顎と唇を含む顔の下半分形状を表す画像データ列から特徴量を表すパラメータ計算し、そのパラメータとデータベースを基に画像データを母音(あ、い、う、え、お)及び撥音(ん)のいずれか一つに対応付けすることにより第2の文字列を生成し、第1及び第2の文字列が一致する場合に認証を許可する結果を出力部に出力するステップを実行させるプログラムを備える。
(もっと読む)
音声認識システム
【課題】極力、認識語彙に含まれる不要語の数が少ない辞書を用いて音声認識を行なうことにより、音声認識性能の低下を抑制すること。
【解決手段】音声データに基づいて話者を識別し、その話者の発話音声における不要語の使用頻度を算出して、話者毎に不要語使用頻度として記憶しておく。この不要語使用頻度は、話者毎に、どの程度頻繁に不要語を使用するかの傾向を表すものとなる。従って、音声データに基づいて話者が識別されたとき、その話者に対して不要語使用頻度が記憶されている場合、音声認識部31において使用される不要語辞書313bを、記憶されている不要語使用頻度に応じた不要語の数の不要語辞書313bに切り替える。この結果、話者の不要語使用頻度に適した不要語の数の不要語辞書313bを用いて、音声認識を行なうことができる。
(もっと読む)
歌唱者がマイクロホンに発した音声により演奏を中止するカラオケ装置
【課題】マイクロホンを手にして歌唱体勢にある歌唱者本人が、音声特徴パラメータ登録といった面倒を意識することなく、そのマイクロホンへの音声指示だけでもって、伴奏音楽を円満かつ円滑に途中終了させられるようにする。
【解決手段】歌唱者のマイクロホン21から得た歌声信号と、歌詞文字データとに基づいて、歌唱者の音声を分析して特徴パラメータを抽出し、カラオケ伴奏音楽の間奏区間において、直前までに音声分析手段が分析した特徴パラメータと、メモリに記憶されている演奏中止指示用単語とに基づいて、直前まで歌っていた歌唱者が演奏中止指示用単語を発話したか否かを分析し、声認識手段が演奏指示用単語を発話したと分析した場合i、演奏中のカラオケ伴奏音楽を途中終了させる。
(もっと読む)
個人認証システム
【課題】携帯型機器によって操作可能な家電機器を使用する際に、個人認証により個人向け自動設定を低コストで簡易に行うことができる個人認証システムを提供する。
【解決手段】センサ部5を制御するCPU18と、センサ部5において検出された個人識別信号PSiを送信し、個人認証信号RSiを受信する送受信部20とを有するリモートコントローラ1と、認証部6を備える家電機器3と、リモートコントローラ1からの個人識別信号PSiを家電機器3に伝送し、家電機器3からの個人認証信号RSiをリモートコントローラ1に伝送する無線伝送部2とを備え、家電機器3は、ゲーム機やHDレコーダであっても良く、映像機器であっても良い。個人認証には、家電機器3の使用者の音声認証方式、リモートコントローラ1における静電認証方式、若しくは人体通信による静電認証方式を適用することができる。
(もっと読む)
応対装置、コンピュータを応対装置における各手段として機能させるためのプログラム、及び応対装置の応対処理方法。
【課題】来訪者を照合処理中の場合でも、居住者に迅速で防犯性の高い応対ができるよう音声を制御することが可能なインターホンシステムを提供する。
【解決手段】
子機10の呼出し信号を受信して来訪を検知した場合、応対者により親機20の通話信号を受信して、応対者の音声情報の入力が開始されたかどうか判断される(S13)。応対者から音声情報の入力が開始されたと判断された場合(S13:YES)、親機20のCPU201が、ステップS13で取得した応対者の音声情報から、周波数分布等を算出し、予め設定された設定値に変更して子機に音声情報を送信する。続いて、来訪者が登録済かどうか照合され、来訪者の評価結果に対応した音声情報に変更して、子機に送信する。
(もっと読む)
撮像装置および話し手認識方法
【課題】 本発明は、動画撮影時に、話し手となる人物(被写体)の認識を高精度に行うことのできる撮像装置および話し手認識方法を提供することを目的とする。
【解決手段】 本発明の撮像装置(11〜32)は、画像解析手段(11)と、音声解析手段(11)と、話し手認識手段(11)を備え、画像解析手段は、連続的に取得される画像から人物の顔領域中の口唇領域を検出すると共に、その口唇領域のデータから口唇動作の特徴を抽出する。また、音声解析手段は、画像と同期して取得される音声データから音声の特徴を抽出する。そして、話し手認識手段は、画像解析手段により抽出された口唇動作の特徴と、音声解析手段により抽出された音声の特徴とに基づき、画像に写る複数の人物から話し手となる人物を認識する。
(もっと読む)
情報処理装置、および情報処理方法、並びにプログラム
【課題】不確実で非同期な入力情報に基づく情報解析により、精度の高いユーザ識別処理を実行する構成を実現する。
【解決手段】カメラやマイクによって取得される画像情報や音声情報に基づいて実空間におけるユーザの存在と位置および識別情報を含む解析情報を生成する。仮想ユーザに対応する複数のターゲット各々について、(1)ターゲットの存在確率算出に適用するターゲット存在仮説情報、(2)ターゲットの存在位置の確率分布情報、(3)ターゲットが誰であるかを示すユーザ確信度情報を設定し、ターゲット存在仮説情報を適用して各ターゲットの存在確率を算出してターゲットの新規設定および削除を実行する構成としたので、例えば誤検出による誤生成ターゲットを削減し、高精度かつ高効率のユーザ識別処理を実行可能となる。
(もっと読む)
車載機器用制御装置
【課題】ユーザに対応して車載機器の動作の設定を自動的に行うにあたってコストを低減しつつユーザの負担を軽減する上で有利な車載機器用制御装置を提供する。
【解決手段】音質特徴量検出手段22は、音声入力部14から供給される運転者の音声データに基づいて、第1、第2特徴量を検出する。イントネーション特徴量検出手段24は、音声入力部14から供給される運転者の音声データに基づいて音声の第3特徴量を検出する。運転者類別手段26は、音質特徴量検出手段22およびイントネーション特徴量検出手段24によって検出された音声の第1、第2、第3特徴量に基づいて運転者を類別する。動作設定手段28は、運転者類別手段26により運転者が類別されると、該類別された運転者に対応する設定データをデータベース20から読み出すと共に、該読み出した設定データに基づいて車載機器200の動作を自動的に設定する。
(もっと読む)
41 - 60 / 293
[ Back to top ]