
Fターム[5D015KK02]の内容
Fターム[5D015KK02]の下位に属するFターム
電気計算機、タイプライタへの入力 (36)
Fターム[5D015KK02]に分類される特許
1 - 20 / 537
画像認識システムを備えた知識情報処理サーバシステム
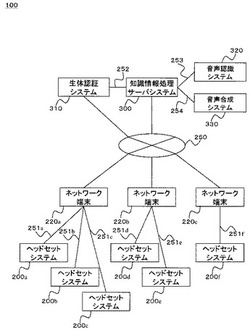
【課題】広範なソーシャル・コミュニケーションを喚起する。
【解決手段】インターネットに接続可能なネットワーク端末に接続され、ユーザの頭部に装着可能なヘッドセットシステムから得られるユーザの主観的な視野等を反映した画像、及び音声信号を、ネットワーク端末経由で知識情報処理サーバシステムにアップロードし、画像に内包されているユーザが着目した特定物体等に対し、音声認識システムとの協調動作により、ユーザ自身の音声による着目対象の指定、選択等を、サーバシステム上で可能にし、ユーザによる一連の画像認識プロセス及び画像認識結果を、音声合成システムとの協調動作により、サーバシステム側がインターネットを介し、ユーザのネットワーク端末経由で、画像認識結果及びその認識プロセスをユーザのヘッドセットシステムに組込まれたイヤフォンに対し音声情報として通知し、ユーザのメッセージやつぶやきを広範なユーザ間で共有可能にする。
(もっと読む)
証券向け顧客情報管理システム

【課題】従来、通話録音データと接触履歴情報を関連付けることは可能であったが、キーワードを指定して、接触履歴と関連する内容を検索することはできなかった。
本発明の目的は、キーワード等の検索条件に該当する通話録音内容を容易に検索できるようにすることにより、接触履歴に関連する通話録音内容の検索を効率的に行うことができる証券向け顧客情報管理システムを提供することにある。
【解決手段】本発明の顧客との接触情報である音声データを文字データに変換して管理する顧客情報管理システムは、顧客との接触履歴情報データを入力する接触履歴情報データ入力手段と、文字データを接触履歴情報データと関連付ける文字データ関連付手段と、接触履歴情報データと文字データを表示する表示手段とを有することを特徴とする。
(もっと読む)
音声制御システム及びプログラム
【課題】1つの自然文によって複数のコマンドを実行可能とした音声制御システムにおいて、従来よりも幅広い表現の自然文を受け入れることを可能とし、ユーザの利便性を向上する。
【解決手段】自然文から抽出される言葉と制御コマンドとを直接結びつけるコマンド変換辞書を記憶手段104に備えると共に、制御コマンドに直接結びつかない言葉を制御コマンド生成用のパラメータに変換するための変換補助情報を記憶手段106に記憶する。また、制御コマンドに直接結びつかない言葉については変換補助情報を参照して制御コマンド生成用のパラメータに変換し、制御コマンドを生成するコマンド変換手段103を備える。
(もっと読む)
情報端末、サーバー装置、検索システムおよびその検索方法
【課題】 本発明の目的は、より手軽に高い検索機能を利用できる情報端末の技術を提供することにある。
【解決手段】
本発明に係る情報端末は、音声の入力を受け付ける音声入力受付手段と、ネットワークを介して所定のサーバー装置と通信を行う通信手段と、出力手段と、前記音声入力受付手段により受け付けた音声の情報を前記サーバー装置へ送信して前記音声の情報に関係するPOI(Point Of Interest)の候補を特定する情報を受信するPOI特定手段と、前記POI特定手段により受信したPOIの候補を特定する情報を前記出力手段へ出力するPOI候補出力手段と、前記POIの候補を特定する情報の選択入力を受け付けて当該POIへ至る経路を探索する経路探索手段と、を備えることを特徴とする。
(もっと読む)
制御サーバ、制御方法、プログラム、および制御システム
【課題】複数のユーザ端末のうちのいずれに対するユーザ入力にも応答するための制御サーバ、制御方法、プログラム、および制御システムを提供する。
【解決手段】音声ガイダンスサーバによる電話端末に対する音声ガイダンスの提供を制御する音声ガイダンス制御部と、前記音声ガイダンスの内容に関連するWebコンテンツのWebクライアントに対する提供を制御するWebコンテンツ制御部と、前記電話端末に対するユーザによる入力内容を示す音声入力結果、および前記Webクライアントに対するユーザによる入力内容を示すWeb入力結果が通知され、前記音声入力結果または前記Web入力結果に基づく指示を前記音声ガイダンス制御部および前記Webコンテンツ制御部に出すマルチアクセス制御部と、を備える、制御サーバ。
(もっと読む)
入力支援装置、入力支援方法、および入力支援プログラム
【課題】高いセキュリティを求められる既存のアプリケーションに対して音声入力機能を簡単に追加することができる入力支援装置を提供すること。
【解決手段】本発明に係る入力支援装置を含む情報処理装置200は、情報を入力するための入力エリアを入力画面に表示するアプリケーションソフトウェアである電子カルテ部203に対して、音声入力機能を追加する装置であって、入力エリアの表示位置と、当該入力エリアを表す読みを特定する第1の情報と、を対応付けた画面構成テーブルを格納する画面構成テーブル格納部208と、発話音声に対する音声認識処理の結果を表す第2の情報を取得し、取得した前記第2の情報に対応する入力エリアの表示位置を、画面構成テーブルを参照して特定し、特定した前記表示位置を選択する操作情報を、電子カルテ部203に入力する入力情報生成部210とを有する。
(もっと読む)
オーダ端末およびオーダ端末のプログラム
【課題】客の注文の入力に誤りがあったとしても、簡単に訂正できるオーダ端末を提供する。
【解決手段】音を取り込むマイクと、あらかじめ記憶した複数の料理情報中から、前記マイクで取り込んだ音の中の音声により所定の料理情報を認識して呼び出す呼出手段と、前記呼出手段で呼び出した料理情報を記憶する注文記憶手段と、前記呼出手段で呼び出した注文情報を表示する表示手段と、前記マイクで取り込んだ音を記録する記録手段と、前記記録部で記録した音を再生する再生手段とを備えたオーダ端末とした。
(もっと読む)
書き起こし支援システムおよび書き起こし支援方法
【課題】音声データのうち書き起こしが完了した位置を特定可能な書き起こし支援システムを提供する。
【解決手段】実施形態の書き起こし支援システムは、音声データをテキスト化する書き起こし作業を支援する書き起こし支援システムであって、第1記憶部と、再生部と、第2記憶部と、テキスト作成部と、推定部とを備える。第1記憶部は、音声データを記憶する。再生部は、音声データを再生する。第2記憶部は、音声データに対して音声認識処理を実行することにより得られる音声テキストデータを構成する複数の文字列の各々と、音声データの位置を示す音声位置情報とを対応付けた音声インデックスを記憶する。テキスト作成部は、ユーザーの操作入力に応じてテキストを作成する。推定部は、音声インデックスに基づいて、前記音声データのうち、前記テキストの作成が完了した位置を示す作成済み音声位置情報を推定する。
(もっと読む)
医療用実習システム
【課題】同時に複数の医療用実習装置を用いて医療実習を実施するための技術を提供する。
【解決手段】医療用実習システム100は、それぞれで歯科実習が実施される複数の医療用実習装置10を備えている。複数の医療用実習装置10のそれぞれは、擬似患者体2および診療台3を備えている。また、医療用実習システム100は、擬似患者体2の動作を制御する中央制御部90と、擬似患者体2の頭部模型2aの表情を変化させる擬似患者体駆動部2Aと、医療実習において、擬似患者体2の動作内容を示す情報が記述されている複数の医療用実習シナリオの中から、特定の医療用実習シナリオを選択するための表示部92(シナリオ選択部)とを備えており、中央制御部90は、選択された医療用実習シナリオを実行する。
(もっと読む)
文章認識能力評価システム、文章認識能力評価プログラム、文章認識能力評価プログラムが記憶された記憶媒体及び文章認識能力評価方法
【課題】言葉の塊であるチャンクをパターン認識しながら読解する能力を評価する。
【解決手段】記憶部9は、判定基本文章を基本文字データとして記憶するとともに、判定表示文章を表示文字データとして記憶する。判定表示文章は、判定基本文章がチャンク毎に区別可能に仮名文字によって表されたものであり、且つ複数のチャンクのうち4文字以上の仮名文字から構成される所定の変換対象チャンクの最初の1文字と最後の1文字とを除く複数の中間文字の配列順序が入れ替えられている。計算部8は、判定表示文章を表示装置3に表示し、マイク7は、判定表示文章を音読する回答者の発話音声を音声データとして取得する。計算部8は、音声データを解析して音読文字データに変換し、音読文字データと基本文字データとを照合することによって、回答者の文章認識能力を評価する。
(もっと読む)
音認識装置
【課題】両手がふさがった状態でも、正解文字列と実際に記載されている文字列との照合作業を音声により行うことを可能とする音認識装置の提供。
【解決手段】装着者の音声を検出するマイクロフォンと、装着者に音声情報を伝達するスピーカと、正解文字列を読み取るための読取装置と、処理装置と、を備えるハンズフリー型の音声認識装置であって、処理装置が、装着者の読み上げた文字列を音声認識処理し、読取装置で読み取った正解文字列とのマッチングを行い、マッチングの判定結果を出力することを特徴とする音声認識装置。
(もっと読む)
情報処理装置、情報処理方法及びプログラム
【課題】例えば会議の議事録中における特定の箇所に関連する音声を、高い精度で特定する。
【解決手段】音声変換部201は、複数の発言の内容を複数の第1のテキストデータに変換するとともに、各発言の開始時間を特定する。発言者特定部202は、各発言の発言者を特定する。テキスト入力部206は、第2のテキストデータを入力する。入力時間特定部208は、第2のテキストデータの入力時間及び第2のテキストデータに対応する発言者を特定する。マッチング箇所特定部204は、複数の第1のテキストデータと第2のテキストデータとをマッチングする。音声区間特定部205は、音声変換部201、発言者特定部202、入力時間特定部208及びマッチング箇所特定部204の特定処理の結果に基づいて、複数の第1のテキストデータから第2のテキストデータに対応する第1のテキストデータを特定する。
(もっと読む)
会議システム、会議管理装置およびプログラム
【課題】会議に関する補足項目を容易に管理することが可能な会議システムおよびそれに関連する技術を提供する。
【解決手段】この会議システムは、各発言者の発言内容を音声認識して文字データに変換する音声認識手段と、文字データに変換された発言内容から所定のキーワード(例えば「「フォローアップ必要」)をトリガー情報として検出する検出手段とを備える。また、この会議システムは、トリガー情報の検出に応じて、或る発言者の発言に関連して補足処理(フォローアップ処理)を行うべき補足項目(フォローアップ項目)LM1,LM2,...を作成し、当該補足項目LM1,LM2,...を含む補足リスト(フォローアップリスト)FLを作成するリスト作成手段を備えるとともに、当該補足リストの表示用データを生成する表示制御手段をさらに備える。
(もっと読む)
アルバム作成装置、アルバム作成装置の制御方法、及びプログラム
【課題】 コンテンツを閲覧した複数のユーザの好みを考慮したアルバムやダイジェストを自動で作成する。
【解決手段】 再生された複数のコンテンツを閲覧した複数のユーザの反応を取得(S304、S306)し、この取得された複数のユーザの反応に基づき、前記再生された複数のコンテンツの優先度を決定し(S308)、決定された優先度に基づいてアルバムを作成する(S309)。
(もっと読む)
通信システム、通信装置、サーバ、情報通知方法およびプログラム
【課題】通話で送信されてきた音声信号に基づいた情報を容易に得る。
【解決手段】通信装置100−1が、通信装置100−2から送信されてきた音声信号から音声を認識し、認識した音声を示す音声情報をサーバ200へ送信し、サーバ200が、送信されてきた音声情報に基づいて表示情報を、音声情報と表示情報とをあらかじめ対応付けて記憶する記憶部から検索し、検索した表示情報を通信装置100−1へ送信し、通信装置100−1が、サーバ200から送信されてきた表示情報を表示する。
(もっと読む)
通信機器及び表示システム
【課題】本発明は、通話内容を把握することが容易な通信機器及び表示システムを提供する。
【解決手段】通信機器は、表示部21と、音声が入力され、入力された音声を音声データに変換して出力するマイク12と、外部通信機器との間での通話に利用され、その外部通信機器から音声データが入力される通信部32と、特定の単語に対応する登録単語データを記憶する記憶部33と、マイク12から出力された音声データと通信部32に入力された音声データとの少なくとも一方と、記憶部33に記憶された登録単語データとに基づいて、各音声データに基づく音声の中に含まれる特定の単語を抽出する抽出部41と、抽出部41によって抽出された特定の単語或いは当該特定の単語を含む文節又は文を表示部21に表示させる表示制御部42と、を備える。
(もっと読む)
携帯端末、情報通知方法およびプログラム
【課題】店舗などで買い物をする際、買う予定をしていた商品を買い忘れていることを容易に通知する。
【解決手段】携帯端末100の記憶部104に音声入力部あるいは文字入力部により購入予定品名を登録する。店舗などで買物をする場合、品名抽出部106が、撮影部105が撮影した画像から品名を抽出し、比較部107が、品名抽出部106が抽出した品名である購入済み品名と、記憶部104に記憶された購入予定品名とを比較し、表示部108が、比較の結果を表示する。
(もっと読む)
検索システム、端末、検索装置、及び検索方法
【課題】本願発明が解決しようとする課題は、検索システムの制御を簡素化することにある。
【解決手段】本願発明は、検索技術に関し、端末の現在の位置を示す現在地情報を取得し、目的地に関する情報である目的地情報を音声情報として取得し、この取得した音声情報に前記取得した現在地情報をデータハイディングにより付加して音声透かし情報を生成し、前記生成された音声透かし情報の音声情報から目的地情報を認識し、この認識した目的地情報と、前記生成された音声透かし情報の現在地情報とに基づいて、地図情報を検索することを特徴とする。
(もっと読む)
音声をテキストに変換する装置及び方法
【課題】音声をテキストに変換する装置及び方法を提供することを目的とする。
【解決手段】本発明の音声をテキストに変換する装置は、音声受信モジュール、音声識別モジュール、表示モジュール、入力モジュール及び制御モジュールを備え、前記音声受信モジュールは、外部の音声信号を受け取って前記音声識別モジュールに送信し、前記音声識別モジュールは、異なる所定の時間範囲における各々の所定の時間範囲内の音声信号をテキストデータに変換してから前記制御モジュールに送信し、前記入力モジュールは、ユーザーが入力した文字データを前記制御モジュールに送信し、前記制御モジュールは、同じ所定の時間範囲内のユーザーが入力した文字、音声から変換されたテキスト及び同じ前記所定の時間範囲を前記表示モジュールに表示させる。
(もっと読む)
字幕生成配信システム、字幕生成配信方法およびプログラム
【課題】映像の字幕を生成し、視聴端末で同期表示するように字幕と映像とを配信すること。
【解決手段】字幕生成配信システムは、音声を含む映像を取得する撮影装置10と、撮影装置10で取得された映像を所定時間遅延させる映像バッファ41と、編集端末20から受信した字幕情報とを視聴端末50に配信する配信部42を含む配信サーバ40と、撮影装置10で取得された映像に含まれる音声に対する音声認識結果を取得する音声認識サーバ30と、音声認識サーバ30で取得された音声認識結果をユーザが編集するための編集画面を表示し、編集画面から字幕を取得する編集部22と、映像バッファ41で映像を遅延させた所定時間と、音声認識サーバ30および編集部22での処理に要した時間とに応じて決定される時間、字幕を遅延させる字幕バッファ23とを含む編集端末20と、を備える。
(もっと読む)
1 - 20 / 537
[ Back to top ]