
国際特許分類[A63H3/33]の内容
生活必需品 (1,310,238) | スポーツ;ゲーム;娯楽 (86,983) | 玩具,例.こま,人形,フープ,積木 (4,067) | 人形 (737) | 人形内の発声手段の装置;音を出すための人形内の手段 (120) | 人形に特に適合したその他の発生手段 (104)
国際特許分類[A63H3/33]に分類される特許
51 - 60 / 104
組合せ玩具
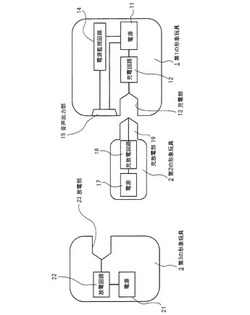
【課題】第1の形象玩具の電源に、第2の形象玩具の電源から容易かつ比較的短時間の充電を実現する。
【解決手段】第1の形象玩具1および第2の形象玩具2を備える。第1の形象玩具1は、電源11と、電源11に充電するための充電部13と、電源11から供給される電力で作動する音声出力部15と、電源11の電力の残量を監視する電源監視回路14とを有する。第2の形象玩具2は、電源17と、この電源17に充電するとともに電源17の電力を第1の形象玩具1の充電部13を介して放電するための充放電部19とを有する。そして、第2の形象玩具2の電源17は有機ラジカル二次電池を有する。
(もっと読む)
会話ロボットシステム

【課題】話し相手の感情に応じた会話等を行うことができるとともに、当該会話等を使用目的や状況に応じて容易に更新できる。
【解決手段】 音声入力器2、音声出力器3、表情出力器5、および動作出力器6を備えたロボット1と、当該ロボット1とは別体に設けられてこれに無線で接続されたコンピュータ4とを備える。コンピュータ4は、音声入力器2を介して入力した音声を分析して感情パラメータを算出するステップと予め各感情パラメータに応じて定められた発話シナリオ、表情シナリオおよび動作シナリオに基づいて音声出力器2を介して所定の音声を出力するステップ、表情出力器5を介して所定の表情を創出するステップ、および動作出力器6を介して所定の動作を実現するステップとをそれぞれ実行する。上記各シナリオはコンピュータ4のメモリ42に更新可能に記憶されている。
(もっと読む)
顔面変換型立体人形
【課題】顔画像を形成したお面部材を、立体人形の顔部分に脱着可能にした顔面変換型立体人形を提供する。
【解決手段】顔画像5を形成して成るお面部材2と、顔部分Pを備えた立体人形1と、立体人形1の顔部分Pに対し、前記お面部材2を脱着可能とする磁気吸着力、凹部の係合機構等の装着手段3とを備える。お面部材2は、表面に顔画像5を形成した略半球殻状の合成樹脂製のフィルム成形体6単独にて形成するか、または、このフィルム成形体6を顔基板部7に密着固定させて形成する。
(もっと読む)
会話ロボット
【課題】話し相手の感情に応じた会話等を行うことができる会話ロボットを提供する。
【解決手段】
音声入力器2、音声出力器3、表情出力器4、および動作出力器5、これらが接続され音声認識手段を構成する処理装置1を備えている。処理装置1は、音声入力器2を介して入力した音声を分析して複数の基本パラメータを算出するステップと、基本パラメータから複数種の感情パラメータを算出するステップと、予め各感情パラメータに応じて定められた発話シナリオに基づいて音声出力器3を介して所定の音声を出力するステップと、予め各感情パラメータに応じて定められた表情シナリオおよび動作シナリオに基づいて、表情出力器4を介して所定の表情を創出するステップと、動作出力器5を介して所定の動作を実現するステップとをそれぞれ実行する。
(もっと読む)
録音再生する模造口腔体
【課題】よりリアルに故人をしのぶことができる録音再生する模造口腔体を提供する。
【解決手段】故人の歯又は義歯と、録音再生装置を備える。上あご部と下あご部は再生する音声の音量に合わせて開閉する。汎用通信インターフェースを備え、パソコンなどの機器と通信可能であり、パソコンを使用して音声データを模造口腔体のメモリに格納したり読み出したりすることができる。模造口腔体は口腔部を模して形成されるが、仏像などの像に組み込んでも良い。
(もっと読む)
ロボット装置、音楽出力方法及び音楽出力プログラム
【課題】本発明は、ロボット装置の使い勝手を向上させる。
【解決手段】本発明は、可動部2を有するロボット装置1において、受信部3により音楽データを受信して出力部4により音楽として出力しながら、分析部5によりその音楽データを分析すると共に、設定部6により音楽データの分析結果に基づいて、音楽に対応する可動部動きパターンを設定して、駆動制御部7により、当該設定した可動部動きパターンに応じて可動部2を駆動することにより、ユーザに対し多数の音楽データを記憶するように操作させることなく、また何度も異なる音楽データを記憶し直すように操作させることもなく、容易に、より多くの音楽に合わせて可動部2を動かして見せることができ、ロボット装置1の使い勝手を向上させることができる。
(もっと読む)
情報提供ロボットおよびロボットを用いた情報提供方法
【課題】店舗などに来店した顧客に情報を提供する情報提供ロボットおよびロボットを用いた情報提供方法に関し、ロボットが店舗などに来店した顧客の身長や顔の高さで大人、小人、幼児などを検出および混雑度合いを検出してこれらをもとに顧客に最適な情報をテーブルから選択して表示、音声を発声、ジャスチャーで表現、更に移動して説明や案内を効率的に行う。
【解決手段】店舗などに来店した顧客の高さを検出する手段と、検出した顧客の高さをもとに大人、小人、幼児などに対応した複数のモードのうちいずれのモードかを決定する手段と、モードに対応づけて、ロボットの紹介内容、発声、ジェスチャー、移動を予め登録するテーブルと、決定したモードをもとにテーブルを参照して、ロボットの紹介内容、発声、ジェスチャー、移動に関する情報を読み出す手段と、読み出した情報をもとにロボットに実行させる手段とを備える。
(もっと読む)
ロボットアームおよびそれを備えるロボット
【課題】必要に応じてボディバルーンを収縮、膨張させ、ロボットの運搬作業を容易に行う。
【解決手段】ロボット10は、ロボットアーム12を含み、パソコン18等から送信される遠隔操作情報に基づいて、自身の動作を制御する。ロボットアーム12は、アームバルーン14および関節部材16を含み、たとえば関節部材16aを介してボディバルーン58に接続される。アームバルーン14およびボディバルーン58は、柔軟な気密シートによって形成され、かつ気体の出し入れを行う空気栓20を備える。この空気栓20から空気を出し入れすることによって、アームバルーン14等は、膨張および収縮が可能である。ロボット10を運搬するときには、アームバルーン14およびボディバルーン58内の気体は抜かれる。すなわち、ロボット10は、バルーンによって形成される部位を収縮させて折り畳む等した状態で運搬される。
(もっと読む)
玩具体制御システム、制御プログラム、玩具体
【課題】 管理しているスケジュールを多様な形態でもってユーザに告知することで、スケジュールの告知に遊技性を持たせることを提案する。
【解決手段】 スケジュールの種類を示すコード、コードが示す種類に関連した音声データ、コードが示す種類に関連した画像データ、を関連付けて第1のメモリに格納する。スケジュールを設定した日時情報とこのスケジュールの種類を示すコードとを関連付けて第2のメモリに格納する。現在日時が日時情報が示す日時から所定期間前に達した場合、この日時情報に関連付けて格納されている種類情報に関連付けて格納されている音声データと画像データとを取得する。取得した画像データに基づいた画像を表示し、取得した音声データを音声出力装置に出力する。音声データの出力後、上記特定したコードが第1の種類を示す場合、音声出力装置による音声出力を行った旨を表示する。
(もっと読む)
ロボット装置及びロボット装置の制御方法
【課題】音声認識率を向上させることができるロボット装置及びその動作制御方法を提供すること。
【解決手段】ロボット装置は、優先度が設定された音声入出力経路A1〜A4と、優先度に基づき音声入出力経路A1〜A4を切替選択する音声信号切替器11と、入力された音声を認識する音声認識モジュール12と、音声認識結果に基づき発話動作する音声発話モジュール13とを有する。音声認識モジュール12は、音声入出力経路からの音声のA/N比が所定の閾値以上であるか否かを判定するS/N比判定手段と、音声の音声認識率が所定の閾値以上であるか否かを判定する認識率判定手段を有し、音声信号切替器11は、音声入出力経路A1〜A4のうち、可変の優先度を有する音声入出力経路A2〜A4の優先度を、S/N比判定手段及び認識率判定手段の判定結果に基づき更新する優先度更新手段を有する。
(もっと読む)
51 - 60 / 104
[ Back to top ]