
国際特許分類[G06F19/22]の内容
物理学 (1,541,580) | 計算;計数 (381,677) | 電気的デジタルデータ処理 (228,215) | 特定の用途に特に適合したデジタル計算またはデータ処理の装置または方法[6,8,2011.01] (2,326) | バイオインフォマティクス,すなわち計算分子生物学において遺伝子または蛋白質関連データの処理を行うための方法またはシステム (90) | 核酸またはアミノ酸の配列比較に関するもの,例.ホモロジー検索,モチーフまたはSNP発見,配列アラインメント (12)
国際特許分類[G06F19/22]に分類される特許
1 - 10 / 12
アセンブリ誤り検出のための方法およびシステム(アセンブリ誤り検出)
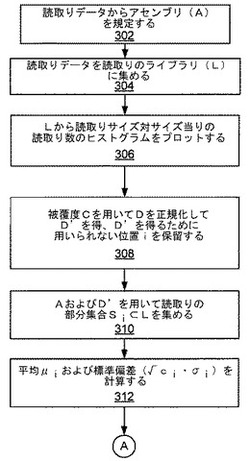
【課題】読取りデータの再アセンブリはアセンブリにおける配列誤りを含み得る。なぜならセグメントを正確な元の順序に戻すことは難しいことがあるからである。
【解決手段】遺伝子配列アセンブリの誤りを検出するための方法は、遺伝子データの配列のアセンブリ(A)を規定するステップと、読取りデータを読取りのライブラリ(L)に集めるステップと、読取りのサイズ対サイズ当りの読取り数のヒストグラムをプロットするステップと、分布(D)を被覆度Cで正規化することによって、平均(μ)および標準偏差(σ)を有するD’を得て、D’を得るために用いられない位置(i)を保留するステップと、AおよびD’を用いて読取りの部分集合(Si⊂L)を集めるステップと、Siを用いて平均(μi)および標準偏差(√ci・σi)を計算するステップと、ユーザに対してディスプレイ上に結果を出力するステップとを含む。
(もっと読む)
核酸情報処理装置およびその処理方法

【課題】DNAマイクロアレイに相当する再使用が容易なプローブセットを容易に設計・変更可能とする核酸情報の処理技術を提供する。
【解決手段】核酸情報処理装置であって、複数の塩基配列の情報を記憶する記憶部130と、類似度の閾値を特定する情報を受け付ける入力処理部111と、入力処理部111等で指定を受け付けたクラスタリングの対象となるターゲットフラグメントの塩基配列データ全てを、BLASTソフトウェアにて取り扱い可能な形式のデータへ変換するクラスター制御部118等、とを備える。
(もっと読む)
可溶性制御タグ設計装置およびその方法とプログラム
【課題】 タンパク質の可溶性をコントロールするタグを設計する方法を提案する。
【解決手段】
可溶性タンパク質および不溶性タンパク質のアミノ酸配列を記憶したデータベースから読み出したデータに基づいて、可溶性制御タグを設計する。この装置は、可溶性タンパク質と不溶性タンパク質のそれぞれのN末端における各アミノ酸類似群配列の出現回数をカウントし、可溶化タグを設計する場合には可溶性タンパク質のN末端における各アミノ酸類似群配列の出現頻度に基づいて頻出アミノ酸類似群配列として求め、可溶性タンパク質のN末端から読み出したアミノ酸配列の中から頻出アミノ酸類似群配列に対応するアミノ酸配列を求め、アミノ酸配列中の各場所におけるアミノ酸の種類ごとの出現回数をカウントアップする処理を順次行い、各場所において出現回数が最多のアミノ酸の組み合わせからなるアミノ酸配列を可溶化タグとして求める。
(もっと読む)
協業基盤の塩基配列データの管理、表示およびアップデート方法
【課題】協業基盤の塩基配列データの管理、表示およびアップデート方法を提供する。
【解決手段】協業基盤の塩基配列データの管理方法は塩基配列の少なくとも1つのベースに対応するアンカー(anchor)に対する注釈データを入力受けるステップおよび前記サービスサーバが注釈データに対する1つ以上のカラム(column)を含む注釈データテーブルに、前記受信した注釈データを格納するステップを含む。
(もっと読む)
ゲノム配列特定装置、ゲノム配列特定プログラムおよびゲノム配列特定装置のゲノム配列特定方法
【課題】解読された大量の断片配列からゲノム全体の塩基配列を復元できるようにすることを目的とする。
【解決手段】リファレンスマッピング部110は、リファレンス配列データ192を用いて断片配列データ191をリファレンスマッピングしてゲノム暫定配列データ101を生成し、残った断片配列データ191をレフトオーバー配列データ102として特定する。ギャップ近傍配列抽出部120は、リファレンスマッピングで特定できなかった部分(ギャップ)の前後に設定した断片配列データ191をゲノム暫定配列データ101から抽出する。デノボアセンブル部130は、ギャップ近傍配列データ103とレフトオーバー配列データ102とをデノボアセンブルしてアセンブル部分配列データ104を生成する。完全ゲノム復元部140は、ゲノム暫定配列データ101にアセンブル部分配列データ104を設定してゲノム配列データ105を生成する。
(もっと読む)
遺伝子絞り込み装置、遺伝子絞り込み方法、及びコンピュータプログラム
【課題】 ある特定の機能や関連性を持った候補遺伝子の中から、より可能性が高い遺伝子を絞り込むことができる遺伝子絞り込み装置、遺伝子絞り込み方法、及びプログラムを提供する。
【解決手段】 本発明の遺伝子絞り込み装置は、記憶手段と、入力手段と、処理手段とを備え、記憶手段は、複数の生物学的情報が格納され、一の遺伝子又はタンパク質に該情報から得られた複数のアノテーションが付与されたデータウェアハウスを記憶し、入力手段は、複数の候補遺伝子又は候補タンパク質が情報として入力され、処理手段は、(a)アノテーションを収集する収集処理と、(b)付与の頻度又は数が閾値より高いアノテーションを選択する第1選択処理と、(c)遺伝子を選択する第2選択処理と、を実行する。
(もっと読む)
最適アラインメント計算装置及びプログラム
【課題】リード長に制限を設けずに、計算機のワード演算のビット並列性を利用して、動的計画法(DP法)によるアラインメント処理を1プロセッサで並列化し高速化する。
【解決手段】DP行列を計算する範囲を、計算機のワード長に対応する幅をもつ対角線周辺領域に制限し、その領域内の情報を対角線と直行する方向のビットの並びに分割して表現し、それらの情報に対する計算をビット並列化する。
(もっと読む)
配列解析装置、配列解析方法およびコンピュータプログラム
【課題】大量のショートリードの中から、高速に、編集距離が所定の範囲内にあるショートリードのペアを探索することができる配列解析装置を提供する。
【解決手段】配列解析装置10は、複数の塩基配列を入力する配列入力部11と、編集距離dとブロック分割数を決定する数値nまたは分割数(d+n)を入力する条件入力部12と、複数の塩基配列の各々を(d+n)個に分割してブロックを生成し、その中から選んだn個のすべてのブロックについて、読み出した部分配列、または、前記編集距離dによって定まる最大オフセットの範囲内で、読出し範囲を特定する窓枠を当該ブロックからオフセットさせて読み出した部分配列が一致する条件を満たす塩基配列の集合を等価クラスとする等価クラス生成部13と、等価クラス生成部から、塩基配列のペアについて、編集距離を計算し、編集距離d以内であると計算されたペアを示すデータを出力する類似判定部14とを備えた。
(もっと読む)
リシークエンシング病原体マイクロアレイ
【課題】DNAリシークエンシングマイクロアレイの使用による病原体検出および同定に関し、生物学的サンプル中に存在する病原体の鑑別診断(differential diagnosis)および血清型決定のためのリシークエンシングマイクロアレイチップと、生物学的サンプル中に存在する病原体の存在およびアイデンティティーを検出する方法を提供する。
【解決手段】所定の生物学的配列の同定のためにクエリーへのインプットのための生物学的サブ配列を選択するためのコンピュータ実施方法で、メモリー中に記憶された生物学的配列データからサブ配列を、プロセッサ実行プロセスで選択するステップ、および該配列をクエリーへ供し、第1所定信頼水準で該所定の生物学的配列を同定するステップを含む、方法。
(もっと読む)
塩基配列集合算出装置、塩基配列集合算出方法およびコンピュータプログラム
【課題】動的計画法を用いて塩基配列の最小自由エネルギーを算出して配列集合を設計するにあたり、評価計算を高速化することのできる技術を提供する。
【解決手段】塩基配列集合算出装置100は、初期演算部21、テーブル記憶部33、近傍解生成部22、近傍解演算部23を備える。初期演算部21は、一対の塩基配列の局所的な部分エネルギーを動的計画法により積算して最小自由エネルギーを算出する。テーブル記憶部33は、初期演算部21による積算の過程の部分エネルギーと塩基とを対応づけた評価テーブルTBを記憶しておく。近傍解生成部22は、制約に違反する一対の塩基配列の一部の塩基を変更して近傍解NSを生成する。近傍解演算部23は、テーブル記憶部33に記憶された評価テーブルTBと、変更された塩基に対応する一部領域の部分エネルギーとに基づいて、近傍解NSにかかる最小自由エネルギーを動的計画法により算出する。
(もっと読む)
1 - 10 / 12
[ Back to top ]