
Fターム[5B042JJ03]の内容
デバッグ、監視 (27,428) | 動作監視、異常又は誤りの検出 (3,508) | 監視 (1,259) | 集中監視 (355)
Fターム[5B042JJ03]に分類される特許
341 - 355 / 355
情報処理システム
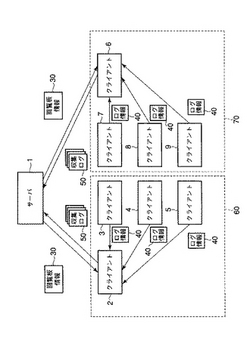
【課題】通信ネットワーク上の機器の処理動作の内容を示すログ情報を、大きな負荷を要すること無く収集する。
【解決手段】クライアント2は、クライアントグループ60に属するクライアント2〜5の識別情報が記録された回覧板情報30をサーバ1から受信した際に、自機の処理動作にかかる負荷の大小を判別し、この負荷が予め定めた基準より低い場合には、クライアントグループ60に属する他のクライアント3〜5が発行するログ情報40を取得し、この取得した情報を、自機が発行するログ情報40とあわせ、中間収集済みログ情報50として、サーバ1に送信する。また、クライアント6は、クライアントグループ70に属するクライアント2〜5の識別情報が記録された回覧板情報30をサーバ1から受信した際に、クライアント7〜9およびサーバ1との間で、クライアント3〜5およびサーバ1との間で行なわれた処理と同様の処理を行なう。
(もっと読む)
リモート保守システム及びリモート保守方法

【課題】 複数の顧客システムの監視、保守を行うリモート保守センタ及びリモート保守方法に関し、センタサーバの信頼性を向上すると共に、処理性能の低下を回避する。
【解決手段】 複数の顧客システム2からの情報を格納するデータベース14a,14bをそれぞれ有する複数のセンタサーバ12a,12bと、顧客システム2から受信した情報を、複数のセンタサーバ12a,12bに転送する中継サーバ11と、複数のセンタサーバ12a,12bのデータベース14a,14bにそれぞれ格納された情報を受信して照合し、同一の情報のメッセージ本文を、複数のセンタサーバをそれぞれ識別できる参照番号と共に格納するデータベース18と、このデータベース18に新規の情報が格納されたことを判定して保守端末4に通知する判定通知処理手段(判定通知処理部19)とを有するサポートシステム13とを備えている。
(もっと読む)
統合監視システム
【課題】 監視サーバの継続的な運用を実現し、運用者の負担を低減することができる統合監視システムの提供。
【解決手段】 複数の監視エージェント22等と該監視エージェント22等の障害を監視する監視サーバ21とを含む複数の被監視システム2に接続され、この複数の被監視システム2の障害を監視する統合監視システム1であって、前記監視サーバ21が、監視エージェントから受け取った障害情報を一元的な障害情報に変換して一次蓄積用監視情報データベース21bに記憶すると共に前記一元化した障害情報を前記統合監視システムに送信する監視情報通知プログラム21aと、前記統合監視システム1が、前記監視サーバ21からの障害情報を受信して監視情報データベース13に記憶すると共に監視サーバ21からの障害情報を基に障害発生時の顧客への通知条件を予め登録しておくための通知ルールデータベース15を参照して通知を行う障害通報プログラム14とを備えるもの。
(もっと読む)
ヘルス・モニタリング技術およびアプリケーション・サーバの制御
【課題】 アプリケーション・サーバの性能および可用性を改善する技術を提供する。
【解決手段】 一態様において、ひとつまたは複数のアプリケーション・サーバのヘルス・モニタリングを行う方法は、以下のステップを含む。まず、ひとつまたは複数のヘルス・クラスを指定する。このひとつまたは複数のヘルス・クラスはそれぞれ、上記ひとつまたは複数のアプリケーション・サーバのひとつまたは複数のヘルス・ポリシーを規定するものである。そして、このひとつまたは複数のヘルス・ポリシーのうちの少なくともひとつを監視する。ひとつまたは複数のヘルス・ポリシーの侵害があれば、これを検出する。
(もっと読む)
コンピュータ監視方法および管理装置
【課題】低コストで、コンピュータ装置の稼動状態を監視することができるようにする。
【解決手段】ハイパーテキストに記述されている、コンピュータ装置各々が備える所定のデータの位置情報を検出する検出ステップと、検出ステップで検出した位置情報に基づいて、コンピュータ装置各々に所定のデータを要求する要求ステップと、要求ステップで要求した所定のデータを取得できた場合、ハイパーテキストに従って、監視画面の所定の位置に所定のデータを表示するとともに、要求ステップで要求した所定のデータを取得できなかった場合、ハイパーテキストに従って、監視画面の所定の位置にあらかじめ定められた代替データを表示する表示ステップと、を行う。
(もっと読む)
サーバ間通信システム。
【課題】 アプリケーションサーバにおいて、メッセージを受信するだけで、接続サーバでのシステムダウン障害が発生していたことを自動的に認識でき、接続先サーバ個々のマシン再立上げを把握することができるサーバ間通信システムを提供すること。
【解決手段】 接続サーバ22との通信メッセージヘッダ23に、マシン立上げ時刻を付加することにより、アプリケーションサーバ21において、接続サーバ22個々のシステムダウン障害を認識でき、マシンの信頼性も把握することができるようにした。
(もっと読む)
部品別一元稼働管理システム
【課題】
大規模システムの保守を行うにあたり、個々の計算機を個別に操作して確認する必要や多くの手間や時間を減らし、より効率的な保守環境を実現する。
【解決手段】
大規模システムにおいて、各計算機101〜103内の部品稼働状態を一元管理するために、稼働管理サーバ104をTCP/IPにて接続する。各計算機の部品単位に識別番号を設け、さらに識別番号の先頭に計算機名をつける。これを部品識別番号とすることで稼働管理サーバ104にて一元管理を行う。稼働管理サーバ104より定期的な診断実施通知や部品個別診断実施通知を行い、各計算機の稼働状態が一括して把握できる。また、稼働管理サーバ104に各計算機の消耗品交換時期を記録することにより、一括した消耗品管理環境を提供し、各部品の確実な交換が可能となる。
(もっと読む)
運用管理支援システムおよび性能情報表示方法
【課題】 管理対象システムの性能情報を収集する運用管理支援システムにおいて、ある性能情報種類についての性能劣化を、その性能情報種類から影響を受ける他の性能情報種類についての性能情報の変化によって判断する。
【解決手段】 メトリック相関400は、性能情報種類間の依存関係について影響を与える性能情報種類と影響を受ける性能情報種類とを示す依存関係情報を格納する。性能情報収集部105は、性能情報種類全体のうち選択された性能情報種類について管理対象システムから周期的に性能情報を収集して性能情報履歴を記録する。検索部101は、選択されない性能情報種類の1つが指定されたとき、メトリック相関400を検索し、指定された性能情報種類から影響を受けかつ選択済の複数の性能情報種類を取得し、取得した性能情報種類について性能情報履歴を表示する。
(もっと読む)
情報管理システム、端末およびサーバ
【課題】簡易な構成で機器の状態に関する情報を取得することが可能な情報管理システム、端末およびサーバを得ること。
【解決手段】機器データを外部機器4から受信する通信IF部52と、外部機器4の状態値を含む実オブジェクトを生成するとともに、仮想オブジェクトを生成するための実オブジェクト情報を生成する実オブジェクト生成部53と、を有するネットワーク5上の端末1と、実オブジェクト生成部53で生成された実オブジェクト情報を記憶するデータベース30を有するネットワーク5上のオブジェクトディレクトリサーバ3と、データベース30の実オブジェクト情報に基づいて仮想オブジェクトを生成する仮想オブジェクト生成部63を有するネットワーク5上のサーバ2と、を備える情報管理システムであって、サーバ2は、仮想オブジェクトによって実オブジェクトから外部機器4の状態値を受信する。
(もっと読む)
HPCクラスタを管理するためのグラフィカル・ユーザ・インタフェース
高性能計算(HPC)環境においてグラフィカル・ユーザ・インタフェースを備える方法は、複数のHPCノードに関する情報の収集を含む。各ノードは統合ファブリックを備える。複数のグラフィカル・エレメントが、収集情報に少なくとも部分的に基づいて生成される。グラフィカル・エレメントの少なくとも一部分がユーザに提示される。
 (もっと読む)
(もっと読む)
マルチエージェントシステム用異常管理方式
複数のアプリケーションエージェントが通信ネットワーク上で互いに対話できるように構成されるマルチエージェントシステム(MAS)のために異常管理方法が提供される。MASは、照会側エージェントが、おそらく被照会側エージェントと関連する1つ又は複数の状態によって引き起こされた対話異常が発生したと判断するときに被照会側エージェントに関して、照会側エージェントからレポートを受信するように構成された複数の異常管理エージェントを有する。異常管理エージェントは、該対話異常を引き起こした被照会側エージェントと関連する1つ又は複数の状態を決定するように構成される。異常管理エージェントは該状態を矯正するようにも構成される。該方法は、照会側エージェントから被照会側エージェントとの対話に関係する情報を含むメッセージを受信する前記複数の異常管理エージェントの内の少なくとも1つを備える。該メッセージは被照会側エージェントを識別する情報、及び該対話障害に関連する他の情報を備える。該対話異常を引き起こした可能性のある被照会側エージェントと関連する1つ又は複数の考えられる状態は、照会側エージェントによって提供される情報から決定される。次に複数のテストが被照会側エージェントと関連する少なくとも1つの状態を決定するために実行される。最後に、被照会側エージェントと関連する状態が矯正される。それから照会側エージェントは、対話を再開又は続行できるようにするためにフィードバック情報を提供されてよい。 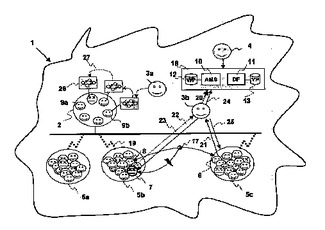 (もっと読む)
(もっと読む)
コンピュータ障害発生時に複数のコンピュータの配列を操作する方法
本発明は、ソフトウェアユニット(A1..A4,D1..D5)を実行するようにセットアップされた複数のコンピュータ(1,2,3,4)配列の操作方法と、コンピュータ(1,2,3,4)の間を仲介し、コンピュータ(1,2,3,4)を監視する付加的な監視用コンピュータ(5)と、定期的に監視を受けるコンピュータ(1,2,3,4)の状態、に関する。本発明は、ソフトウェアユニット(A1..A4,D1..D5)がその重要度に応じて重み(L2K,SL)を割り当てられ、コンピュータ(1,2,3,4)の障害において、監視時点に障害の起きたすべてのコンピュータ(1,2,3,4)と、それによって影響を受けたすべてのソフトウェアユニット(A1..A4,D1..D5)の、障害に関する情報を収集し、障害により影響を受けたソフトウェアユニット(A1..A4,D1..D5)を、他のコンピュータ(1,2,3,4)に転送する転送シナリオが、ソフトウェアユニット(A1..A4,D1..D5)の重み(L2K,SL)を利用して決定されることを特徴とする方法である。
 (もっと読む)
(もっと読む)
ウェブ高可用性の自律型監視
【課題】 ウェブ・サービスを利用するアプリケーション全体に対して高可用性処理環境を提供する。
【解決手段】 高可用性のデータ伝送及び処理環境を保持する方法である。クラスタのネットワークが提供される。ネットワークの各々のクラスタは、少なくとも2つの同一サーバを含む。ネットワークの各々のクラスタは、該ネットワークの少なくとも1つの他のクラスタに直接接続される。相互に直接接続されるクラスタ対の各々は、該クラスタ対の第1のクラスタにおける各々のサーバが、通信リンクを介して、該クラスタ対の第2のクラスタにおける少なくとも1つのサーバに直接接続されることを特徴とする。通信リンクの稼動状況(すなわち、通信リンクが稼動状態であること、又は非稼動状態であること)を監視するようになっている制御サーバが提供される。制御サーバは、各々のクラスタにおける少なくとも1つのサーバに、該制御サーバと該少なくとも1つのサーバとの間の通信チャネルを介して直接リンクされる。
(もっと読む)
マルチプロセッサシステムを整備する保守インターフェースユニット
保守インターフェースユニットを含む装置が説明される。1つの例示的な実施形態において、装置はマルチプロセッサシステムおよび保守インターフェースユニットを含む。マルチプロセッサシステムは、メモリにアクセスするのにキャッシュ一貫性を使用する。保守インターフェースユニットは、マルチプロセッサシステム内に組み入れられ、外部保守システムに代わってマルチプロセッサシステムへのバックドアによるアクセスを可能にするように構成される。また、保守インターフェースユニットは、マルチプロセッサシステム内の操作を実行すると同時にキャッシュ一貫性を維持するようにも構成される。
 (もっと読む)
(もっと読む)
クラスタ装置
【課題】少ない構成費用にて作動させることのできるクラスタ装置を提供する。
【解決手段】第1のネットワーク(NW1)と、アプリケーションノード(AK)を成しかつオペレーティングシステム(OS)を有する少なくとも2つのデータ処理システムと、各アプリケーションノード(AK)におけるアプリケーションエージェント(AA)とを有するクラスタ装置において、アプリケーションエージェント(AA)が次の機能を有する。すなわち、
− アプリケーションノード(AK)において実行されるインスタンス(I1,I2,I3)の監視(UB)および認識、
− 新たなインスタンス(I3)の始動またはアプリケーションノードにおいて予定よりも早く終了させられたインスタンスの再始動、
− アプリケーションノード(AK)における新たなインスタンス(I3)の実行が可能であるか否かの評価(BE)および判定、
− ネットワーク(NW1)に接続されているアプリケーションノードのアプリケーションエージェント(AA)へのインスタンス実行要求(AF)、
− ネットワーク(NW1)に接続されているアプリケーションノードのアプリケーションエージェント(AA)へのインスタンス実行要求(AF)引き受け後のメッセージ通知(ME)。  (もっと読む)
(もっと読む)
341 - 355 / 355
[ Back to top ]