
Fターム[5B042MC30]の内容
デバッグ、監視 (27,428) | 表示又は記録する内容 (5,146) | 計算値 (364) | 故障率 (31)
Fターム[5B042MC30]に分類される特許
1 - 20 / 31
情報処理装置、及び、情報処理方法
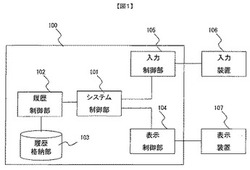
【課題】
過去のエラー情報を蓄積し、エラー情報を好適にユーザに提示する。
【解決手段】
情報処理装置であって、前記情報処理装置の内部の状態を管理し、エラーを検知するシステム制御部と、検知したエラーに関する情報を保存する履歴格納部とを備え、前記システム制御部は、前記エラーに関する情報に基づくユーザ提示情報を、エラーの分類と、過去の発生頻度とに応じて生成し、ユーザに対して提示する制御を行うことを特徴とする。
(もっと読む)
機器管理システム、障害管理装置、機器管理装置、障害管理プログラム、及び機器管理プログラム

【課題】電子機器の可用性を向上させる機器管理システム、障害管理装置、機器管理装置、障害管理プログラム、及び機器管理プログラムを提供する。
【解決手段】機器管理システム1は、機器管理装置200は、障害予測部131により、所定期間経過後の電子機器300における障害発生予測を障害管理装置100に要求する。これを受けて障害管理装置100は、障害履歴解析部21により、記録された障害履歴を解析し、障害予測部212により、解析結果に基づき、所定期間経過後に電子機器300で発生する可能性のある障害を予測し、予測結果を要求元の機器管理装置200に応答する。その結果、機器管理装置200は、通知部14により、予測結果に基づき、障害発生が予測された電子機器300の情報を障害対応元CEに通知するとともに、情報取得制御部11により、障害発生が予測された電子機器300からの情報取得の間隔を短くする。
(もっと読む)
運用管理装置、運用管理方法、及び運用管理プログラム
【課題】管理対象ノードの性能情報を収集することなく、異常を検知する。
【解決手段】運用管理装置21のメッセージ取得部201は、管理対象ノードが出力したメッセージを取得してメッセージDB202に記録する。学習情報生成部204が、指定した期間内における管理対象ノード毎、メッセージの識別情報毎、単位時間毎のメッセージの数の最大値、又は最小値を算出して学習結果情報DB205に記録する。分析情報生成部206が、対象ノード毎、メッセージの識別情報毎、単位時間毎のメッセージ出力数を算出して分析結果情報DB207に記録する。分析判定部208は、学習結果情報DB205に記録された最大最小値情報と、分析結果情報DB207から読み出した分析データ情報とに基づいて、分析対象の各管理対象ノードが正常であるか否かを判定し、判定結果を分析結果情報DB207に記録し、出力部209に出力する。
(もっと読む)
管理システム、処理装置、および管理方法
【課題】処理装置の使用上の不都合の発生を抑えつつ、ソフトウェアが更新されるまでの間、発生した問題を回避することのできる管理システムを提供する。
【解決手段】処理装置であるMFP100はファームウェアの実行上の問題の発生を回避するための回避情報を記憶するための回避情報リスト204を有し、MFP100のCPU10は、管理装置であるサーバから回避情報の入力を受け付ける入力部102と、回避情報を回避情報リスト204に書き込むための書込部104と、回避情報リスト204にある回避情報を適用させるための適用部106と、MFP100におけるファームウェアの実行上の問題の発生頻度に基づいて、受信した回避情報を取り込んで回避情報リスト204に書き込むか否かを判断するための取り込み判断部103とを含む。
(もっと読む)
保守運営システム
【課題】障害発生以前に得られる情報を利用して、保守サービスの効率化を図る。
【解決手段】保守運営システム100は、ユーザシステム200に接続されている遠隔監視装置201からの情報に基づきユーザシステム200での障害発生確率を計算するユーザ状況管理システム101から障害発生確率情報を入力し、障害発生確率に基づき、サービス員を割当てるユーザシステム200を選択し、サービス員の派遣スケジュールを参照し、割当て対象として選択したユーザシステム200にサービス員を割当てて、サービス員の派遣スケジュールを生成する。
(もっと読む)
情報処理装置並びに情報処理装置の管理方法及び管理プログラム
【課題】複数のプロセッサを備える情報処理装置において新規に追加したプロセッサの運用初期に発生する故障によってシステム全体に障害が発生することを防止する。
【解決手段】複数のプロセッサP0〜P6と、複数のプロセッサP0〜P6を監視し、監視結果から得られた情報を記録し、記録された情報から複数のプロセッサP0〜P6の障害発生確率を計算するサービスプロセッサ110とを備え、新規に追加されたプロセッサP7と、計算手段によって相対的に障害発生確率が低いと計算されたプロセッサP1とを多重化する情報処理装置100である。
(もっと読む)
仮想マシン管理装置、移行先決定方法および移行先決定プログラム
【課題】仮想化環境において仮想マシンの使用目的を好適に達成できるように仮想マシンを移行する。
【解決手段】管理サーバ100は、物理サーバ103に発生した障害の履歴を、例えば物理サーバ障害履歴情報テーブル125、物理サーバ障害発生回数情報テーブル126、仮想マシン稼働履歴情報テーブル127および障害時マシン構成履歴情報テーブル129として記憶し、各物理サーバ103において障害が発生した程度を示す障害率などを、仮想マシン131の使用目的に基づいて算出する。算出の結果、その障害率などで示される障害の程度が最も小さな物理サーバ103に仮想マシン131を移行する。
(もっと読む)
障害検知装置、情報処理方法、およびプログラム
【課題】異常検知のための分析処理にかかる時間を短縮するとともに、異常発生個所の誤検出を防止可能にした障害検知装置を提供する。
【解決手段】複数のシステムのそれぞれに対応する物理機器の情報を示す設定ファイルが予め登録され、物理機器の性能種目毎の時系列データである性能データを記憶する記憶部と、一定の時間間隔で設定ファイルを参照して性能データをシステム単位に分割する分析領域分割部と、分割された性能データ間に存在する相関関係を分析し、分析した相関関係毎に異常があるか否かを判定する分析部と、分析された相関関係のうち、異常があると判定された相関関係の割合を性能データ毎に算出し、割合の高い方が表示順の上位になるように、割合と物理機器の名称との組み合わせを記述したテーブルを複数のシステム毎に出力する分析結果出力部と、を有する。
(もっと読む)
評価装置および評価プログラム
【課題】製品が故障するか否かを高精度に評価する。
【解決手段】観測日時から指定時間以内に製品が故障した稼働データに対して故障ラベルを付与し、観測日時から指定時間以内に製品が故障していない稼働データに対して非故障ラベルを付与し、観測日時から指定時間以内に製品が故障したか否か不明である稼働データに対して故障ラベルおよび非故障ラベルのいずれも付与しないラベル付与部102と、ラベルが付与された稼働データとラベルが付与されていない稼働データとを用いて稼働データの分布を学習し、製品が故障する確率をモデル化した故障モデルを作成する学習部110と、故障モデルと稼働データとに基づいて、製品が故障する確率を評価する評価部120と、を備える。
(もっと読む)
遠隔デバイス管理システム及び方法
【課題】リモートデバイス(例えば携帯型データ端子、証印リーダまたはバーコード・スキャナ)の故障やパフォーマンスをモニタし、分析して、ダウンタイムを減らしまたは除去する。
【解決手段】プロセッサ260を包含するホストサーバ236と、システムバス258と、ユーザ入力デバイスと通信するように構成されたユーザ入力インターフェース254と、ディスプレイと通信するように構成されたディスプレイインターフェース252と、データベース246を包含するデータ格納手段242およびリモートデバイス200と通信するように構成されたネットワークインターフェース250と、パフォーマンス・ルックアップテーブル248と、プロセッサによって実装されるとき、リモートデバイスからパフォーマンスパラメータ値を受信し、パフォーマンスルックアップテーブルを照会するプログラム命令を包含するアナライザモジュール244と、を有する。
(もっと読む)
総テスト時間を最小にするようにテストシナリオを最適化するテスト支援装置、テスト装置、テスト支援方法及びコンピュータプログラム
【課題】全てのテストシナリオに沿ってテストを最小時間で完了させることができるよう、スナップショットを取得するテストノードを適切に選択することができるテスト支援装置、テスト装置、テスト支援方法及びコンピュータプログラムを提供する。
【解決手段】テストシナリオに関する情報、次に遷移するべきテストノードに関する情報等を記憶しておく。テストノードごとに分岐パスが存在するか否かを判断し、分岐パスが存在すると判断したテストノードにおいて、スナップショットを取得した場合にテストを完了するまでに要する実行予測時間を算出する。スナップショットを取得することなくテストを完了するまでに要する実行時間を算出し、実行時間と実行予測時間との差分を短縮時間として算出する。短縮時間が最も大きいテストノードを選択して、選択したテストノードを識別する情報を出力する。
(もっと読む)
情報システムの品質管理方法及び品質管理装置
【課題】品質評価対象となる情報システムの規模によらず、その情報システムの故障発生状況から品質を評価できるようにする。
【解決手段】故障率算出部130は、情報システム300に発生した故障発生情報が登録されるDB110を参照し、すべての情報システム300を対象とした装置種別ごとの平均故障率を算出する。平均故障実績算出部150及び管理限界値算出部160は、DB110の故障発生情報を参照し、各情報システム300ごとに、複数月の故障発生件数の移動平均、及び、各装置ごとにシステム規模及び平均故障率に基づいて補正した所定期間に亘る各月の故障発生件数の総和である管理限界値を夫々算出する。そして、品質評価部170は、各情報システム300ごとに、移動平均と管理限界値との比較に基づいて、情報システム300の品質を評価する。
(もっと読む)
情報処理装置及びそのプロセッサ管理方法
【課題】障害発生確率の最も小さいプロセッサをオペレーティングシステム用に設定することで、システムダウンの可能性をより低減することが可能な情報処理装置及びそのプロセッサ管理方法を提供する。
【解決手段】サービスプロセッサ110は、固有の識別子をキーとして各プロセッサの稼働時間及び障害履歴を管理し、稼働時間と障害履歴に基づいて各プロセッサの障害発生確率を計算する。また、各プロセッサの障害発生確率から最も障害発生確率の小さいプロセッサを選出する。そして、複数のプロセッサのうち障害発生確率の最も小さいプロセッサをオペレーティングシステム用に設定することで、以後のシステムダウンの確率を低減させる。
(もっと読む)
障害発生確率算出システム,障害発生確率算出方法及びプログラム
【課題】コンピュータシステムの障害のうち利用者の操作に起因する障害が発生する確率を算出し得る障害発生確率算出システム,障害発生確率算出方法及び障害発生確率算出用プログラムを提供する。
【解決手段】障害時操作特徴値算出手段16が、コンピュータシステムの障害発生時の実行コマンド履歴を複数のカテゴリに分類しこの分類結果に基づいて障害時操作特徴値を算出して障害時データ記憶部17に蓄積すると共に、操作特徴値算出手段20が、評価対象のコンピュータシステムの実行コマンド履歴から障害時操作特徴値算出手段16と同様にして評価対象操作特徴値を算出し、この評価対象操作特徴値と同一又は近似する障害時操作特徴値の個数を障害数算出手段21が障害時データ記憶部17に蓄積された情報を検索して算出し、この算出された個数に基づいて評価対象のコンピュータシステムの障害発生確率を障害発生確率算出手段25が算出する。
(もっと読む)
障害推定装置、方法及びプログラム
【課題】
個別の設計情報を参照せずに、個々の機器の故障率等を推定する。
【解決手段】
機器情報収集装置(22)は、ネットワークインターフェース(20)が接続するネットワークに接続する対象機器の機器情報を定期的に収集し、機器情報データベース(24)に保存する。機器情報加工装置(26)は、機器情報データベース(249に記録される機器情報を加工して特徴量を抽出する。故障率推定装置(28)は、機器情報加工装置(26)からの特徴量から故障率を推定する。障害発生率推定装置(30)は、故障率推定装置(28)の演算結果から障害発生率を推定する。故障要因推定装置(32)は、故障率推定装置(28)の演算結果から故障要因を推定する。
(もっと読む)
情報処理装置及びプログラム
【課題】アプリケーションにおいて発生するタイミング依存の不具合の再現率が高いスレッドのスケジュール方法を見出すことを可能とする。
【解決手段】調査プログラム11は、複数のスレッドのスケジュール方法を表すスレッド制御ポリシーを設定する。スレッド制御用スレッド141は、設定されたスレッド制御ポリシーによって表されるスケジュール方法で複数のスレッドが実行されるための制御を行う。調査プログラム11は、不具合発生プログラム12に不具合が発生したことが検出された場合に、不具合が発生したこと及び複数のスレッドが実行されてから不具合が発生するまでの時間を統計情報として実行結果統計情報記録DB13に記録する。調査プログラム11は、実行結果統計情報記録DB13に記録された統計情報に基づいて、不具合発生プログラム12に発生した不具合の発生頻度が高いスレッド制御ポリシーを特定する。
(もっと読む)
故障確率算出に用いられる生存曲線を生成する装置および方法
【課題】機器の故障において原因となる故障部品が特定されない場合であっても、そのようなケースを含む交換作業の情報に基づいて、故障確率算出に用いられる生存曲線を生成する。
【解決手段】交換記録テーブルEをメンテナンスログLから生成する第1の生成部2と、複数の部品のそれぞれについて部品故障テーブルTを生成する第2の生成部3と、複数の部品のそれぞれについて生存曲線およびハザード関数を生成する第3の生成部4と、ハザード関数を用いてハザード値を計算し、各部品のハザード値を用いて正規化を行うことにより第2の重みを計算し、第1の重みと第2の重みとを比較して収束判定を行う判定部5と、収束判定により生存曲線を出力して処理を終了するか、新たな生存曲線およびハザード関数を第3の生成部4から生成したのち、判定部5により収束判定が繰り返し行われるように制御を行う制御部1と、を具備する。
(もっと読む)
障害監視システムおよび障害監視方法
【目的】本発明は、顧客の装置の品質を評価して監視する障害監視システムおよび障害監視方法に関し、顧客毎に特徴のある動作環境、運用環境に個別に対応づけて当該顧客の装置・部品(ハードウェア)の品質監視を行い、顧客毎かつ当該顧客の装置・部品対応の早期障害検出を実現することを目的とする。
【構成】顧客に対応づけて顧客の装置および装置を構成する部品の障害データを登録するデータベースと、顧客についてデータベースを参照し、顧客の障害データを抽出して装置単位、あるいは更に装置の部品単位に、障害データを分類する分類手段と、分類手段で分類した顧客の装置単位あるいは装置・部品単位の障害データをもとに、製品寿命である劣化モード、修正未適用である修正未適用モード、新規に発生した障害である新規障害モード、顧客の環境による顧客扱いモードのいずれのモードであるかを少なくとも判定するモード判定手段とを備える。
(もっと読む)
ネットワーク障害検出プログラム、ネットワーク障害検出装置、およびネットワーク障害検出方法
【課題】アクセス先の障害と上流ネットワークの障害とを自動的に切り分けること。
【解決手段】各端末Siは、あらかじめ設定された上流ネットワーク103のキャリア101により、インターネット100に接続可能である。ネットワーク障害検出装置111は端末SiおよびサーバDj間のトラフィックを監視する。上流ネットワーク103は、インターネットプロバイダなどのキャリア101,102からなる。ネットワーク障害検出装置111がキャリア101の障害発生を検出することで、端末SiをサーバDjに接続させるキャリア101の障害とサーバDjの障害とを切り分ける。ネットワーク障害検出装置111は、上流ネットワーク103との接続を変更するなどの対処をネットワーク管理装置112に指示する。これにより、下流ネットワーク110をインターネット100に接続させるキャリアがキャリア101からキャリア102に切り替わる。
(もっと読む)
メールサーバ網、サーバ装置、メールシステム及びそれらに用いる障害箇所調査方法
【課題】 故障・遅延箇所の特定・切り分けに要する時間を短縮することが可能なメールサーバ網を提供する。
【解決手段】 複数のメールサーバ(第1メールサーバ群5、第2メールサーバ群6、第3メールサーバ群7)と、複数のメールサーバから一定時間間隔で送出される定期メールを受信する受信サーバ(受信サーバ群4)と、受信サーバで受信した定期メールの解析を行う解析サーバ1とを含むメールサーバ網は、解析サーバ1に、受信サーバで受信した定期メールの受信時間及びメール経路の情報を記録する記録手段と、記録手段に記録された情報の統計処理を行う統計手段とを設けている。解析サーバ1は、統計処理の結果を基にメールサーバにおけるメール遅延及びメール未着における故障箇所及び遅延箇所の調査用の情報を作成する。
(もっと読む)
1 - 20 / 31
[ Back to top ]