
Fターム[5B075ND34]の内容
検索装置 (67,127) | 検索対象情報 (11,868) | 検索対象情報の格納形態 (1,377) | 構造化 (1,335)
Fターム[5B075ND34]の下位に属するFターム
Fターム[5B075ND34]に分類される特許
81 - 100 / 151
ハイパーテキスト変換プログラム、方法及び装置

【課題】ハイパーテキストが直接または間接的にリンクしている他のハイパーテキスト群のアンカー情報がリンク元のアンカー情報から見て適切な場合にのみリンクを張る。
【解決手段】元ハイパーテキスト中の処理範囲に存在する元アンカー72のリンク先ハイパーテキストを取得し、リンク先ハイパーテキストからリンク先アンカーの文字列とリンク先URLとのペアから成るリンク先アンカー情報を抽出する。元ハイパーテキストに新規アンカーを追加する候補文字列範囲となる元アンカー影響範囲を決定し、元アンカー影響範囲に存在する文字列とリンク先アンカー情報に存在する文字列とを比較し、マッチ範囲文字列「製品情報」と新規リンク先URLとのペアから成る新規アンカー情報を生成し、元ハイパーテキストのマッチ範囲文字列に新アンカー102を付与して新ハイパーテキスト70−1に変換する。
(もっと読む)
情報検索システム及びその方法並びにそれに用いる放送受信機

【課題】 放送局が準備した情報以外に、広くインターネット上のWebサイトから関連情報を、視聴者が極めて簡単に得ることを可能にした情報検索方式を得る。
【解決手段】 テレビジョン放送を受信する受信部20と、この受信映像から特徴画像を抽出する特徴画像抽出部19とを有する放送受信機100と、予めサンプル画像とこのサンプル画像に対応したキーワードとを格納したデータベース23と、放送受信機100から送信された特徴画像とサンプル画像とを比較してキーワードを決定する情報処理部22とを有する画像検索サーバ200と、画像検索サーバ200から送信されたキーワードに関連する情報を検索する検索エンジン300とを含む。
(もっと読む)
コプロセッサを使った構造化データおよび非構造化データの高性能の統合、処理および探索の方法およびシステム
ユーザおよび企業体アプリケーションに、企業体の構造化データおよび非構造化データへの効率的で、インテリジェントなアクセスを提供するためにそれらのデータを統合する方法およびシステムが本明細書で開示される。SQLコマンドなどの標準化データベース問い合わせ形式を使って、企業体の構造化と非構造化データの両方に問い合わせを向けることができる。問い合わせを処理する必要に応じて、コプロセッサを使い、非構造化データに対する(全文検索などの)データ処理タスクをハードウェアアクセラレートすることができる。さらに、ハードウェアアクセラレートされたデータ処理のために企業体の非構造化データのどの部分がコプロセッサに送られるべきか判定するために、従来の関係データベース技術を使って、関係データベースによって格納されている構造化データにアクセスすることもできる。 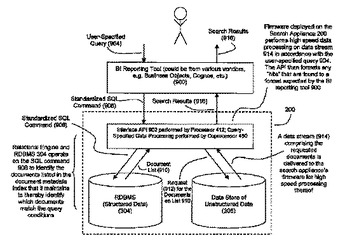 (もっと読む)
(もっと読む)
半構造化情報の照会および解釈を構造化する方法および装置
【課題】様々箇所にあるウエブサイトにある半構造化情報を照会してそれを構造化する。
【解決手段】語彙解析を使用してテキスト情報を含む半構造化情報に反復パターンがないか調べて求めるパターンを識別し、パターンを名前と位置によってネストされた構造体にカタログ化し、ネストされた構造体内のパターンを調べてリレーショナル・データベースのリレーショナル・スキーマのフィールドに対応する属性を識別し、ネストされた構造体内のパターンを調べてパターンを識別し、分解してネストされた構造体にカタログ化し、ネストされた構造体内のパターンを調べて他の半構造化情報へのリンクを識別し、検査してネストされた構造体にカタログ化し、該当するネストされた情報がすべてカタログ化されるまで上記を繰り返し、専用のプログラム・トランスレータが使用するように半構造化情報の正規表現を含む定義を得る。
(もっと読む)
情報検索用サーバ
【課題】 本発明は,関連サイトを簡単に検索できる情報検索用サーバなどを提供することを目的とする。
【解決手段】 本発明は,検索用サイトとして用いることができるサーバであって,前記サーバにアクセスしたクライアントを,ウェブページを表示端末に表示させるウェブページ表示手段と,前記ウェブページ表示手段により前記表示端末に表示されたウェブページに存在する文字列であって,前記クライアントのポインティングデバイスにより選択されたものを,前記サーバに送信させるための文字列送信手段と,して機能させ,前記クライアントの文字列送信手段が送信した文字列情報が前記サーバに入力された場合に,前記文字列情報に基づいて関連サイトを検索し,検索結果を前記クライアントに送信する,情報検索用サーバなどに関する。
(もっと読む)
文書検索装置、文書検索方法および文書検索プログラム
【課題】不完全な経路式に基づいて構造化文書ファイル中から所望のデータを効率的に検索する。
【解決手段】構造化文書ファイルから所望のデータを検索するための文書検索装置に関する。この装置は、構造化文書ファイルにおいて階層的に上下関係にあるタグセットと、経路式の一部にそのタグセットを含む1以上の位置とを対応づけたインデックス情報を保持する。この装置は、部分経路式の入力を受け付けると、インデックス情報を参照して、部分経路式に含まれるタグセットが経路式の一部としてあらわれる位置を検索対象位置の候補位置として特定する。
(もっと読む)
構造化文書管理システム及びプログラム
【課題】構造化文書内部に対する更新操作のうち、クライアントから予め通知することが要求されている更新操作をリアルタイムに検知して通知できるようにする。
【解決手段】テーブル記憶部109は、任意のクライアントから要求された通知対象とするノードを示すノード情報及び通知対象とする更新操作の種類を含む更新通知条件を記憶する。ドキュメント管理部102は、任意のクライアントからの更新要求に応じ、指定の構造化文書に対して要求された更新操作を行い、更新操作が行われたノードを示すノード情報及び更新操作の種類を更新通知管理部106に渡す。更新通知管理部106は、渡されたノード情報の示すノード及び更新操作の種類のテーブル記憶部109に記憶されている更新通知条件に対する一致性を世代関係を踏まえて検証し、一致性が認められた場合に、対応する更新通知条件の設定を要求したクライアント端末への更新通知を行う。
(もっと読む)
文書処理装置、文書処理方法および文書処理プログラム
【課題】構造化文書ファイルに含まれる情報の中からユーザに提供すべき情報を合理的に選択する。
【解決手段】本実施例に示す文書処理装置は、XMLやXHTML、HTMLなどによる構造化文書ファイルを処理対象とする。文書処理装置は、構造化文書ファイルから基準タグと比較タグを選択し、基準タグと比較タグの階層構造上における位置の近さをタグ隣接度として算出する。基準タグに対するタグ隣接度が所定の閾値以上となる比較タグを、近傍タグとして特定し、1以上の近傍タグによって特定されるデータを基準タグに対する近傍データとして出力する。
(もっと読む)
構造化文書管理システム
【課題】要素毎に、その要素に適した種別の索引を構築することにより、良好な更新検索性能を維持しながら検索の厳密性を維持することができるようにする。
【解決手段】データ検索部16内の検索式処理部は、外部から与えられる検索式を解析して検索条件を抽出し、その検索条件に合致する検索結果の候補の集合を取得する。索引管理部15内の値抽出部は、構造化文書DB21に格納された構造化文書に含まれる各要素毎に、当該要素に対して適用された検索条件の履歴を取得する。索引管理部15内の索引種別決定部は、索引を付与すべき、構造化文書に含まれる各要素毎に、当該要素に対して適用された検索条件の履歴において最も多い検索種別に基づいて索引種別を決定する。索引管理部15内の索引構築部は、索引種別決定部によって決定された索引種別の索引を構築して、Nグラム索引DB22、単語索引DB23またはB木索引DB24に格納する。
(もっと読む)
情報検索装置及びその制御方法、プログラム、記憶媒体
【課題】 検索条件をフォルダに対応づけて管理する構成において、所望とする検索条件をユーザが容易に選択することを可能にする技術を提供する。
【解決手段】 情報検索装置は、各ノードが検索条件に対応してなる、ツリーを示す登録情報を記憶する記憶手段と、1以上の検索条件を含む検索式の入力を受け付ける受付手段と、入力された前記検索式を解析し、当該検索式に対応する全てのツリーを作成する作成手段と、作成された前記ツリーの全てと、前記登録情報により示される前記ツリーとを比較して、追加すべきノードを決定する決定手段と、前記決定手段において決定された追加すべき前記ノードを、前記登録情報により示される前記ツリーに追加して、該登録情報を更新する更新手段と、更新された前記登録情報に基づいて、図形により、ノードが追加された前記ツリーを示す画面を表示手段に表示制御する表示制御手段と、を備える。
(もっと読む)
コミュニティによって生成されたウェブサイトをメタデータに用いる方法、機械読取可能な媒体、装置及びシステム
【課題】コミュニティによって生成されたウェブサイトをメタデータに用いる方法及びシステムを提供する。
【解決手段】カテゴリデータセットは、カテゴリと関係データの名前を含み、関係データは、カテゴリとコンテンツとの関係を定義する。コンテンツのためのカテゴリは、ウィキペディアウェブサイトのようにオンラインコミュニティによって生成され、特定のコンテンツに関連するウェブサイトからウェブページを検索し、コンテンツメタデータのためにウェブページを分析することにより生成される。そのコンテンツのためのカテゴリデータは、コンテンツメタデータから抽出される。さらに、カテゴリデータセット内の用語は、カテゴリ及び関係データに基づいて削減される。
(もっと読む)
動的RSSチャネル変更装置
【課題】ユーザがRSSリーダにサイト登録後に新規登場したRSSサイトを自動的にRSSリーダに追加登録する仕組みを提供すること。
【解決手段】ユーザ端末からユーザが指定したキーワードを受信し記憶するキーワード登録処理と、インターネット上で利用可能な複数のRSSサイトを登録したRSSサイト登録DBと、RSSサイト登録DBに登録されたRSSサイトのRSSデータに対してRSSタグ部を探索し、このRSSデータからRSSサイトのアクセス情報を抽出するRSSクローラ処理と、検出したRSSサイトのアクセス情報が、RSSリーダに登録されてない場合に、新規RSSチャネルとしてそのアクセス情報をRSSリーダ追加すべきことを判断する新規RSS追加処理と、RSSリーダにその新規RSSチャネルをRSSデータとして送信する処理とを含むことを特徴とする。
(もっと読む)
情報提供プログラム、該プログラムを記録した記録媒体、情報提供装置、および情報提供方法
【課題】文章の作成者および投稿者にとっては、より精度および有効性の高い位置情報を提供することができ、文章の閲覧者にとっては、文章中の場所をあらわすキーワードに関連付けられた、より確かな位置を示す地図データを容易に閲覧すること。
【解決手段】キーワード/位置情報選択欄1120において、文章情報(ブログ記事)200との関連付けを許可するキーワード/位置情報300が選択されている。このようにキーワード/位置情報300が選択された状態から、投稿ボタン1130が押下されることによって、上記関連付けの許可信号が情報提供装置100に対して送信される。そして、上記許可信号を受信した情報提供装置100においては、上記許可信号により特定されるキーワード/位置情報300と文章情報(ブログ記事)200との関連付け処理がおこなわれる。
(もっと読む)
会議情報処理装置、会議情報処理方法およびコンピュータ・プログラム
【課題】 会議情報を見る利用者が興味や関心のある重要な部分を効率よく知ることができる会議情報処理装置を提供する。
【解決手段】 会議情報に対して所定の処理を行う会議情報処理装置1であって、会議情報を記憶する記憶部3と、所定の規則に基づいて会議情報の属性を分類分けして構造化する属性構造化部6と、属性構造化部6によって構造化された会議情報の属性を可視化する属性可視化部7とを具備する。属性構造化部6は、所定の規則に基づいて、抽象と具体の関係、汎化ないし汎用化と特化ないし特別化の関係、全体と部分の関係、概要と詳細の関係のうちの少なくとも一つの関係になるよう会議情報の属性を分類分けして構造化する。これにより、会議情報の属性を利用者の関心のあるグループに分類分けして視覚化することで、会議情報を見る利用者が興味や関心のある重要な部分を効率よく知ることができる。
(もっと読む)
検索エンジンを利用した例文作成システムと言語に関する練習問題をコンテンツとするwebサイト構築方法
【課題】 漢字の書き取りや読みを記す問題など、字句に関する練習問題の作成には労力が掛かり、webページ上に無償で公開することは困難である。人手を介さず自動的に字句に関する練習問題を作成し、これを無償で公開するための仕組みを提供する。
【解決手段】 字句に関する例文となる文節を検索エンジンにより抽出し、さらに該文節が例文とするに妥当な表現であるかを確認するために、該文節をキーワードとして検索エンジンにより検索し、ヒット数が規定値以上であれば妥当な表現として例文に採用し、この例文を用いて字句に関する練習問題を作成する。さらに上記検索に学習者が興味を持つ分野として指定する興味キーワードを追加して設定し、学習者が興味を持つ分野に関連した内容の練習問題とする。また、該練習問題を提供するwebページにては、興味キーワードに関連したスポンサーリンクを設ける。
(もっと読む)
コンテンツ収集方法及びコンテンツ提供方法並びにコンテンツ表示方法
【課題】多数存在する雑多コンテンツ群の中から、ユーザにとって有益な情報を選別して提供する。
【解決手段】サービス提供サーバ200は、インターネットなどのネットワーク上に散在しているコンテンツ群を収集して蓄積し、蓄積されたコンテンツに記載されている情報を要約してコンテンツ要約情報を作成するとともに、そのコンテンツに関連する店舗の地理的な位置を特定するための店舗位置情報がコンテンツ内に含まれているか否かを解析する。コンテンツ内に店舗位置情報が発見された場合には店舗位置情報を抽出し、コンテンツに対応する情報として、コンテンツ要約情報及び店舗位置情報を情報要素とする構造化情報を作成する。一方、移動端末の現在位置情報を取得した場合には、上記の構造化情報を参照して、その現在位置の近隣に存在する店舗を特定し、特定された店舗に対応する構造化情報に基づいて、移動端末に提供する提供用コンテンツを作成する。
(もっと読む)
ラベルファイル
【課題】ラベルの印刷データを保存するラベルファイルであって、PCのOSの中のファイルシステムが備えるファイル検索機能や、無料で簡単に取得することができるフリーソフトである各種のファイル管理ソフトが有するファイル検索機能によって確実に検索することが可能なラベルファイルを提供する。
【解決手段】ラベルファイル150は、ヘッダ情報エリア151、キーワードエリア152、印刷データエリア153の3つの領域により構成されている。ヘッダ情報エリアは、キーワードエリア152の開始アドレスが4byte、印刷データエリアの開始アドレスが4byteの計8byteによって構成されている。キーワードエリアには、ラベルファイル150を検索するための各種のキーワードがテキストデータにより格納されている。印刷データエリアには、ラベル作成アプリケーション100に固有の形式で作成される印刷データが格納されている。
(もっと読む)
情報管理装置、情報管理方法、情報管理プログラム、記録媒体及び情報管理システム
【課題】文書データの各ページに含まれた領域を、当該領域のデータの種別によらず検索可能な形式で管理する。
【解決手段】文書データの各ページに含まれる領域のメタ情報と、該文書画像を示す文書画像ID及び該ページを示すページIDと、を対応付けた領域管理テーブルを記憶する記憶部と、文書画像の各ページの領域毎に異なるデータの種別の違いに基づいて、文書データの各ページを領域毎に抽出する領域抽出部と、抽出された領域に対応するページIDと文書IDとを、文書データと当該文書データの該当するページに基づいて抽出する関係抽出部と、抽出された領域のメタ情報と、抽出されたページID及び文書IDと、を対応付けて領域管理テーブルに登録する登録部と、を備える。
(もっと読む)
スキーマ統合支援装置、スキーマ統合支援方法およびスキーマ統合支援プログラム
【課題】2つのデータベースの統合処理において、“ドメイン情報”や“属性名”を使用せずにテーブルのマッピング情報を作成できるようにすることを目的とする。
【解決手段】スキーマ情報抽出部103は統合対象である第1のデータベース100と第2のデータベース101とからテーブルのデータ構造を示すスキーマ情報を取得してスキーマ情報記憶装置104に記憶する。各テーブルについて、特徴情報生成部105はスキーマ情報に基づいて各テーブルを構成する各データ項目の数を定義された属性の種類毎に算出して特徴情報として特徴情報記憶装置107に記憶する。類似度評価部108は第1のデータベース100のテーブルと第2のデータベース101のテーブルとで特徴情報を比較して類似度を算出し、比較したテーブルとその類似度を対応付けてマッピング情報としてマッピングモデル記憶装置110に記憶する。
(もっと読む)
Web電子申請書保管方法およびそのシステム
【課題】電子申請書を検索可能に保管する従来の方式について、利用者が二重にデータ入力する負担を軽減するとともに、システムの構築と運用のコストを削減する。
【解決手段】クライアント端末は、サーバ機から受信した電子申請書のHTMLデータから画面表示形式の電子申請書を生成して表示し、このHTMLデータに新たに入力されたデータを組み込んだ電子申請書のHTMLソースを生成し、画面情報中の画面項目とともにサーバ機へ送信する。サーバ機は、受信したHTMLソースをそのまま設定された保管場所に保存し、受信した画面項目から主として検索のキーとなり得るデータ項目値を抽出し、抽出されたデータ項目値に対応するHTMLソースファイルの保管場所情報を加えた検索用レコードを保存する。
(もっと読む)
81 - 100 / 151
[ Back to top ]