
Fターム[5B075NK32]の内容
検索装置 (67,127) | 検索キー情報 (8,147) | 検索キー情報の自動抽出 (2,419) | 自然言語解析による検索キーの抽出 (1,229)
Fターム[5B075NK32]の下位に属するFターム
不要語辞書 (35)
限定辞書 (43)
類義語拡張を伴うもの (357)
Fターム[5B075NK32]に分類される特許
161 - 180 / 794
画像表示装置及び方法並びにプログラム
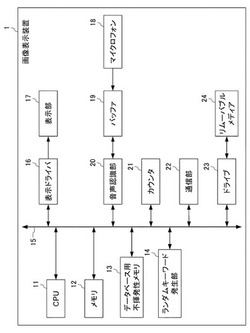
【課題】画像の鑑賞行為をインタラクティブでより豊かな行為にすること。
【解決手段】マイクロフォン18は、表示部17に表示された表示画像を鑑賞する鑑賞者が発した音声の音声信号を入力し、バッファ19に記憶させる。音声認識部20は、その音声信号に基づいて、鑑賞者が発した音声から1以上の単語を識別し、キーワードとして取得する。カウンタ21は、キーワードの出現回数を算出する。表示ドライバ16は、出現回数が閾値以上のキーワードを含む情報又はキーワードから導かれる情報を、表示画像とともに表示部17に表示させる。
(もっと読む)
情報処理装置、情報処理方法およびプログラム

【課題】精度のよい検索を実現する。
【解決手段】検索条件を受け付ける受付部と、少なくとも一つの記憶装置に格納されたコンテンツに含まれるエモチコンを抽出し、抽出されたエモチコンと自然言語との対応関係を解析する解析部と、解析部の解析結果に基づき、抽出されたエモチコンが対応する自然言語を有する場合には抽出されたエモチコンを対応する自然言語と認識し、抽出されたエモチコンが対応する自然言語を有しない場合には抽出されたエモチコンが装飾目的で用いられていると認識し、抽出されたエモチコンが検索条件に適合すると判断した場合に、コンテンツを検索結果として出力する検索部とを備える。
(もっと読む)
トピックワード抽出装置、トピックワード抽出システム、トピックワード抽出方法、及びプログラム
【課題】オフラインにおいて、少ない処理量でテキストからトピックワードを抽出する。
【解決手段】トピックワード抽出装置は、集計期間内に予め収集された複数のテキストで使用されている単語について、該集計期間内で該単語が汎用的に使用された頻度を示す汎用度を単語ごとに算出する汎用度算出手段と、入力テキストが入力されると、該入力テキストから単語を抽出し、該入力テキスト中で該単語が出現した出現頻度と、前記汎用度算出手段により算出された該単語の汎用度とに基づき、該出現頻度が高いほど高く、前記汎用度が低いほど高い値となるトピック重要度を算出するトピック重要度算出手段と、前記入力テキストから、前記トピック重要度算出手段により算出された前記トピック重要度が高い単語を優先してトピックワードとして抽出する抽出手段と、を有する。
(もっと読む)
文書解析システム
【課題】大量の文書が常に増加していくという特徴や、話題が多様で体験談や感想が書かれていることが多いという特徴を持つ文書データの集合において、より正確に話題の内容や筆者の意図を分析する。
【解決手段】文書解析システムは、文書データ124に含まれるキーワードをマッチング検索によって調べるマッチング検索処理部113と、各文書データ124からキーワードとユーザの印象や感想を示す評価語句を抜き出して文書データ124内のキーワードを評価する文書内分析処理部114と、文書内分析処理部114で得られたキーワードに対する評価に基づいて多数の文書データ124についてキーワードを評価する文書間分析処理部115を備える。この文書解析システムにより、ブログやSNSなどのCGMに蓄積されるユーザが発信した文書データ群について市場全体のニーズやその変化を解析し、ユーザの嗜好や市場ニーズに関する情報を得ることができる。
(もっと読む)
情報処理装置、そのデータ処理方法、およびプログラム
【課題】適切なクエリを効率よく生成する情報処理装置、そのデータ処理方法、およびプログラム、ならびに、文書検索システム、コールセンターオペレータ支援システム、および会議支援システムを提供する。
【解決手段】情報処理装置は、文書検索に用いるクエリを蓄積するクエリ蓄積部104と、随時入力される文章データを受け付ける受付部110と、受け付けた文章データに、所定のキーワードが含まれているとき、そのキーワードを抽出する抽出部112と、抽出部112でキーワードが抽出される毎に、クエリ蓄積部104を参照し、いずれのクエリにキーワードを追加するか否かを所定の判断基準で判断し、キーワードを追加するクエリを選択またはキーワードを含む新たなクエリを生成する生成部114と、キーワードを追加したクエリまたは生成された新たなクエリを、クエリ蓄積部104に蓄積する更新部116と、を備える。
(もっと読む)
データ処理装置、データ名生成方法及びコンピュータプログラム
【課題】文書原稿をスキャンして生成した任意の画像データに対し、文書の内容を推測し易いデータ名を生成することができるデータ処理装置、データ名生成方法及びコンピュータプログラムを提供する。
【解決手段】データ処理装置1は、文字列を含む領域の画像中での位置が、タイトル等の文書の内容を表す語句が文書中で配置されている位置を示す位置条件に該当するか否かを判定し、位置条件に該当する領域に含まれる文字列が意味する語句を抽出し、抽出した語句を含むデータ名を生成する。またデータ処理装置1は、文書の形態素解析を行い、文書中のキーワードに連接した文字列、又は文書中で使用頻度の低い形態素を含む文字列が、文字列が名詞句であるための条件を定めた文字列条件に該当する場合に、該当する文字列が意味する語句を抽出し、抽出した語句を含むデータ名を生成する。
(もっと読む)
フレーズ自動挿入装置およびプログラム
【課題】基本文に詳細文の文字列を挿入する場合、係り受け構造に変化が生じない要約文を生成するフレーズ自動挿入装置を提供する。
【解決手段】係り受け整合度記憶部は、表現同士の係り受けの整合度を記憶する。フレーズ挿入位置候補検出部は、挿入先の文のフレーズ間および文先頭等を、挿入位置候補として検出する。フレーズ挿入位置決定部は、係り受け構造データと係り受け整合度記憶部から取得する係りやすさの整合度とに基づき、フレーズ挿入位置候補に挿入フレーズを挿入したときに第1の文データの係り受け構造を壊すか否かを判定し、係り受け構造を壊さないフレーズ挿入位置候補を検出した場合に当該フレーズ挿入位置候補に挿入フレーズを挿入する。
(もっと読む)
共起行列生成装置、共起行列生成方法、共起行列生成プログラムおよびそのプログラムを記録した記録媒体
【課題】単語・成分番号間共起に基づく手法において、対応する単語の間の意味的な類似性と識別性をより緻密に反映できる共起ベクトルまたは概念ベクトルを生成することを可能とする共起行列生成装置を提供する。
【解決手段】各行が単語に対応し、各列がN個の成分番号に対応している第1共起行列14を入力とし、該第1共起行列14の行ベクトルの集合をN´個のクラスタにクラスタリングして、単語とクラスタの成分番号を対応付ける第1クラスタリング手段11と、各行が、形態素解析されたテキストの単語に対応し、各列がN´個の成分番号に対応している第2共起行列17を生成する第2共起行列生成手段12と、任意の単語と任意の成分番号に対し、前記第1共起行列14と前記第2共起行列17の対応する要素を、線形結合した値を、対応する要素とする第3共起行列18を生成する第3共起行列生成手段13とを備える。
(もっと読む)
複合名詞抽出装置
【課題】 事前に複合名詞リストや詳細なルールを記述することなく、適切な複合名詞を抽出することが可能な複合名詞抽出装置を提供する。
【解決手段】 文書データを形態素解析した後、形態素の品詞情報で品詞結合規則を参照し、連続する形態素が結合規則に適合する場合に、その連続する形態素を複合名詞候補として、複合名詞候補データ150を得る。そして、複合名詞候補を構成する先頭の形態素、末尾の形態素それぞれについて、文字列頻度データを参照して先頭の形態素の前方スコア、末尾の形態素の後方スコアを取得し、両スコアがともにスコア設定値より大きい場合に、先頭の形態素から末尾の形態素までの文字列を複合名詞として抽出する。
(もっと読む)
設計チェック知識構築方法及びシステム
【課題】チェック知識内容自体の品質を充分に向上させ、最終的なチェック対象である製品自体の品質を存分に向上させ得る設計チェック知識構築システムを提供する。
【解決手段】このシステム中のチェック対象知識定義手段11は、ユーザ入出力手段10により入力される技術基礎情報に関する技術オントロジーについて、チェックする対象分野となるチェック対象知識(チェック知識)を単語群とそれらの単語群における単語との間の関係により定義したチェック対象知識定義データを生成し、関連用語対応付け手段14は、文書データ用DB13に格納された技術履歴情報に関する知識コンテンツによる複数の文書データから成る文書データ群に基づいて、チェック対象知識定義データ中の単語群に関連する文書データ群中の単語群を抽出して単語群における単語間の関連付けを行う。
(もっと読む)
文書群処理装置、文書群処理方法および文書群処理プログラム
【課題】文書群を代表する単語を抽出すること。
【解決手段】前処理部11は、文書群の各文書を単語に分割し、重要度付与部12は、単語それぞれに対して重要度を付与する。スコア算出部13aは、上位階層の単語として選出された上位語との同時共起度の高低に応じて値が増減するランキングスコアを、上位語以外の単語それぞれに対して算出する。また、階層別キーワード決定部13bは、スコア算出部13aによって上位語以外の単語群それぞれに対して算出されたランキングスコアに基づく順位により、上位語に対する下位語を決定する。階層情報生成制御部13cは、スコア算出部13aによるランキングスコア算出処理および階層別キーワード決定部13bによる下位語決定処理を所定の階層に渡って繰り返して実行させることで、上位語に対する下位語が複数の階層に渡って対応付けられた階層情報を生成するように制御する。
(もっと読む)
文書作成装置および文書作成方法およびプログラムおよび情報処理装置および通信機器
【課題】 文書の用途に応じたタイトルを自動的に行う。
【解決手段】
本発明の文書作成装置は、所定の件名対象の語句と、文書の所定の属性と、所定の件名情報との対応関係の情報が保存されている記憶部と、解析対象の文書から前記件名対象の語句を抽出する文書解析部と、前記解析対象の文書の前記用途情報に対応する前記属性登録情報と、前記抽出された語句との組み合わせに応じた前記件名情報を、前記記憶部から読み出し、当該件名情報に基づいて、前記抽出された語句を件名に入力する件名生成部と、
を備えている。
(もっと読む)
単語対取得装置、単語対取得方法、およびプログラム
【課題】従来、所定の関係にある単語対を適切に取得できなかった。
【解決手段】単語のクラスを特定する単語クラス情報を格納し得る単語クラス情報格納部と、2つのクラスの良さを示すクラス対良好度を格納し得るクラス対良好度格納部と、所定の関係を有する2つの単語対を取得するために利用するシードパターンを1以上格納し得るシードパターン格納部と、1以上の文章群から、シードパターンと共起する1以上の単語対を取得する単語対取得部と、1以上の単語対に対応するクラス対良好度を取得するクラス対良好度取得部と、クラス対良好度を用いて、各単語対のスコアを決定するスコア決定部と、スコアが予め決められた条件を満たすほど高い1以上の単語対を取得する単語対選択部と、単語対選択部が取得した1以上の単語対を出力する単語対出力部とを具備する単語対取得装置により、単語対を適切に取得できる。
(もっと読む)
単語情報収集装置、単語情報収集方法および単語情報収集プログラム
【課題】任意の単語が最初に登場したウェブページに関する情報を収集し、収集した情報を用いてウェブページのコンテンツの充実化を図ることのできる単語情報収集装置、単語情報収集方法および単語情報収集プログラムを提供すること。
【解決手段】単語情報収集装置100は、インデックスデータベース101と、初出ワードデータベース102と、ネットワーク上のウェブページから単語情報を収集する単語情報収集手段110と、指定された検索語に応じた検索結果を提供するウェブ検索手段120と、を備えている。単語情報収集手段110は、ネットワークから単語情報を収集して検索用インデックスを生成するとともに単語の初出情報を収集する。ウェブ検索手段120は、検索結果の一覧を表示するとともに収集した初出情報を表示させる。
(もっと読む)
文書データ分析プログラム及びコンピュータによる文書データ分析方法並びに文書データ分析システム
【課題】文書データに含まれている内容を正しく抽出する。
【解決手段】文書データ分析プログラム17は、コンピュータに、データベースに記憶されており文書を構成する文書要素のうち使用期間が所定の基準より短い文書要素とその性質を示すマスクデータとを関連付けた第1の定義辞書15を参照し、コンピュータによって取得された分析対象の文書データに含まれている文書要素のうち第1の定義辞書15に含まれている文書要素をその文書要素に関連するマスクデータに変換するマスク概念抽出機能14と、データベースに記憶されており使用期間が所定の基準より長い文書要素とその属性データとを関連付けた第2の定義辞書16を参照し、マスク概念抽出機能14によって変換された後の文書データに含まれておりかつ第2の定義辞書16に含まれている複数の文書要素とその属性データとを抽出する概念抽出機能3とを実現させる。
(もっと読む)
画像のキーワード決定システム
【目的】画像のキーワード候補を決定する。
【構成】クライアント・コンピュータ1から検索サーバ2にキーワード付与対象画像データが送信される。その画像データによって表されるキーワード付与対象画像の特徴と似た特徴をもつ画像を含むhtmlページがウェブ・サーバ11〜1Nから見つけられる。見つけられたhtmlページに記述されている説明文から名詞が抽出される。抽出された名詞の出現頻度が高いものがキーワード候補としてクライアント・コンピュータ1に送信される。
(もっと読む)
感性情報抽出装置、感性検索装置、その方法およびプログラム
【課題】検索対象のイメージを表す感性表現を用いて情報検索を行う際に、品質、外見的特長、性格等の検索対象が有する様々な側面について考慮した検索を可能とすること。
【解決手段】検索対象情報抽出部31により、入力されたテキストの集合から感性表現を抽出し、抽出した感性表現を検索対象に結び付け、感性情報生成部32により、結び付けられた検索対象と感性表現とを入力とし、感性表現に対する感性情報および当該感性表現が属する側面情報を少なくとも格納した感性表現DB1を用いて検索対象に対する側面情報毎の感性情報を生成し、検索対象DB2に格納することで、検索条件として入力された感性表現が属する側面についての感性検索を可能とし、全く異なる側面に関するイメージがノイズとなることを避け、検索精度を向上できる。
(もっと読む)
電子辞書及びプログラム
【課題】複数の単語を容易に単語帳登録する。
【解決手段】電子辞書1は、各見出し語と、当該見出し語の説明情報とを対応付けた辞書データベース820を少なくとも1種類記憶するフラッシュROM80と、テキストデータ830を読み込むインターフェース50と、テキストデータ830から複数の単語を抽出するCPU20と、CPU20によって抽出された単語を、当該単語に対応する見出し語を含む辞書データベース820に対応付けて蓄積記憶する単語帳テーブル84と、を備える。
(もっと読む)
検索装置、検索方法、及びプログラム
【課題】利用者が自身のファイルへのアクセス時期についての記憶を利用して目的のファイルを見つけることができるようにする検索装置、検索方法、及びプログラムを提供する。
【解決手段】検索装置1は、利用者が対象ファイルにアクセスしたアクセス時刻及び格納場所をアクセス履歴として収集する履歴収集部2と、対象ファイルからを抽出したキーワードの対象ファイルでの出現頻度を求め、キーワード及び出現頻度を含み、これらが抽出元の対象ファイルに紐付けられたキーワードデータを作成するキーワード抽出部3と、アクセス履歴とキーワードデータとを用いて、キーワードに、対象ファイルのアクセス時刻及び当該キーワードの出現頻度によって値が変動する重みを付加し、キーワード及び重みを含むインデックスデータを作成するインデックス作成部4と、検索を実行し、検索結果に、インデックスデータの内容を反映させる検索実行部5とを備えている。
(もっと読む)
感性情報付与装置、その方法およびプログラム
【課題】テキストから感性表現と感性空間上の極表現との特定の共起パタンを抽出することにより、数百〜数千の感性表現に対する感性情報の付与を可能とすること。
【解決手段】テキスト解析部1において、入力されたテキストに対してテキスト解析を行い、テキスト解析情報を出力し、感性共起パタン抽出部2において、前記テキスト解析情報と、感性表現を表す単語列の情報を登録した感性表現辞書4と、感性表現と感性空間上の感性軸の極を表す極表現とが特定の関係をもって共起する場合の単語列の正規表現からなる共起パタンを登録した共起パタン抽出ルール5とを用いて、極表現と特定の関係をもって共起した感性表現およびその出現数に関する情報である極単位共起感性表現情報を抽出し、感性特徴量付与部3において、極単位共起感性表現情報を用いて、各感性表現の感性ベクトルからなる感性情報を出力する。
(もっと読む)
161 - 180 / 794
[ Back to top ]