
Fターム[5B075NK32]の内容
検索装置 (67,127) | 検索キー情報 (8,147) | 検索キー情報の自動抽出 (2,419) | 自然言語解析による検索キーの抽出 (1,229)
Fターム[5B075NK32]の下位に属するFターム
不要語辞書 (35)
限定辞書 (43)
類義語拡張を伴うもの (357)
Fターム[5B075NK32]に分類される特許
781 - 794 / 794
文書情報マイニングツール
この発明の実施例は、文書から参照キーを抽出するための方法、コンピュータ読取可能な媒体、およびシステムを提供する。文書は、少なくとも1つのキーを識別するために構文解析され、このキーは、少なくとも1つの文脈表示から識別される。キーは、キーの種類に応じて分類され、キーの種類は、文脈表示から識別される。キーは、抽出され、その後、構造化されたシェル内の或る位置に格納され、この位置は、キーの種類に対応する。その結果、当該キーが抽出された文書を探索者が識別することを可能にする当該キーおよび当該キーの種類のうちの1つをシークする探索により、当該キーが見付けられ得る。  (もっと読む)
(もっと読む)
複雑なカテゴリー化のための分類ツール
一般的な情報や、特にインターネット情報の出現は、実際に多くの人々にとって利用可能な情報が増え続けるということを助長しており、その利用者のうちの多くは情報の専門家ではない。情報を組織化し、検索の実行を容易にするための新しくよりよいメカニズムが必要である。本技術は、例えば目的や概念や考えや専門用語やその他というような、一連の登録の組織化の一種を紹介するものである。これは分類の概念化と検索の実行を容易にする。特に、本技術は、情報を組織化するためにさまざまな基準が存在する体系的なカテゴリー化を容易にし、利用者によるその点検や利用を容易にする。  (もっと読む)
(もっと読む)
情報抽出システム
【課題】 テキスト中に表現された事物に関する事実や意見などの記述内容を、事実や意見の観点と記述を対応付けて抽出する。そのために、テキストを入力する入力部と、テキストに記述された表現の観点とその観点に関する記述の組を特定するための観点・記述抽出規則を格納する観点・記述抽出規則格納部と、前記テキスト中の文字列の統語的属性または意味的属性の少なくとも一方の属性から、前記観点・記述抽出規則を用いて観点とその記述の組を対応付け、それらを識別するための識別情報を付与した要素メタデータとして抽出する観点・記述抽出部と、前記観点・記述抽出部が抽出した要素メタデータを格納するメタデータ格納部を有する構成とし、テキスト中に表現された事物に関する事実や意見などの記述内容を、観点と記述の組として構成し、事実や意見の対応付けた形に整理して抽出する。 (もっと読む)
情報提供装置、情報提供方法、情報提供プログラム、及び情報提供プログラムを記録した記録媒体
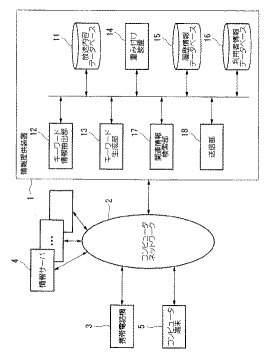
【課題】 容易に番組関連情報や、より詳細な情報等の放送内容の関連情報を利用者に提供可能な情報提供装置を提供する。
【解決手段】 キーワード情報抽出部12は、携帯電話機3上で実行されたアプリケーションプログラムの操作によって、テレビを視聴中の利用者に希望の放送内容を指定させる。次に、放送内容データベース11から、指定された放送内容に基づいて、EPGによる文章情報やメタデータによる単語情報をキーワード群として抽出する。次に、キーワード生成部13が、抽出されたキーワード群から、例えば主題や定義を現すような重要な意味を持つ言葉を、検索用キーワードとして抽出する。次に、関連情報検索部17は、キーワード生成部13により生成された検索用キーワードを用いて情報サーバ4に対する関連情報の検索を実行し、送信部18が、検索された放送内容の関連情報を、予め利用者が指定したメールアドレスへ送信する。
(もっと読む)
情報表示方法、中央処理装置及びコンピュータプログラム

【課題】 通信ネットワークを介して中央処理装置に接続された端末装置からの要求により、前記中央処理装置に記録された掲示情報、キーワード又は該キーワードに関するキーワード情報を、前記端末装置に迅速に表示させることができる情報表示方法、中央処理装置及びコンピュータプログラムを提供する。
【解決手段】 中央処理装置10は、端末装置20、20…から送信された日記ページから、日記ページを作成したユーザ名、作成した日付、及び日記ページに含まれるキーワードを関連付けた関連データベース10cを作成し記録する。一方、一の端末装置20からの要求により、中央処理装置10は、関連データベース10cからキーワードを抽出し、前記キーワードに関するキーワードページへのリンクを生成して、要求された日記ページを前記一の端末装置20に表示させる。
(もっと読む)
コンテンツ推奨方法及び装置
本発明は、コンテンツ推奨方法及び装置並びにユーザプロファイル更新方法及び装置に関する。本方法は、現在のコンテンツ推奨方法に基づきユーザに推奨を行う前に、コンテンツ警告処理ステップを追加し、これにより、以前にユーザに直接提供可能な推奨が、ユーザへの送信前にコンテンツ警告方法により対応して処理されねばならない。あるいは、ユーザのフィードバック情報の受信後、本方法及びシステムは、コンテンツ警告方法により対応してフィードバック情報を処理し、コンテンツ警告方法により処理されたフィードバック情報に従ってユーザプロファイルを更新する。本発明は、より慎重かつ正確にコンテンツを推奨することが可能であり、可能な限りユーザに所望されないプログラムの推奨を回避するため、ユーザの要求にさらに従う推奨を行う。  (もっと読む)
(もっと読む)
画像解析システム及び画像解析方法並びにこれに用いる携帯型通信端末のストラップ
【課題】 画像や色彩と言葉を相互に客観的に関連付けして分類したデータベースを構築し、画像や色彩、言葉を機械的に抽出すること。
【解決手段】 画像解析システム1を、運用者が管理する運用サーバ2及び解析サーバ3と、多数のユーザの通信端末4とで構成する。運用サーバ2は、インターネット上にWebページを公開し、登録会員ごとのメッセージ付き写真画像を閲覧に供す。運用サーバ2はこのサイトに送られた画像付き電子メールをメールの文書データと画像データとに関連づけて画像データベース5に格納する。解析サーバ3は画像データベース5の画像データをビットごとにRGB値及びCMYK値を解析し、画像データ全体の平均値を夫々算出して平均的特徴色を算出すると共に、文書データから形容詞を抽出して、夫々を関連付けした色彩データベース6に夫々格納する。平均的特徴色と形容詞は、一方をもとに他方を機械的に抽出できる。
(もっと読む)
広告主ウェブ情報の検索を用いた広告提供
【課題】広告主ウェブ情報の検索を用いた広告提供
【解決手段】
広告主は、一定のターゲット特定情報(キーワードターゲット特定、等)を入力及び/又は維持することを要求されずに、検索結果ページ、ウェブページ、電子メール、等の様々なコンテンツ上にターゲットが特定された広告を掲載すること又はこれらの様々なコンテンツと関連する広告を提供することが許可される。このことは、入手可能な広告主情報の検索可能データ構造(転置インデックス(460)、等)を用いることによって達成させることができる。広告主ウェブ情報は、広告主のウェブサイトから抽出された項目及び/又は句を含むことができる。特に、検索問い合わせ(410)を用いて、マッチする広告主(従ってマッチする広告)を検索することができる。例えば、検索問い合わせ(410)は、広告主ウェブサイトから抽出された単語及び/又は句を含む転置インデックス(460)を検索するために用いることができる。広告主ウェブページ、又はその他の何らかの識別子は、関連広告を検索するためのキーとして用いることができる。
(もっと読む)
マルチメディアストリームのマルチメディア要約を生成するシステムおよび方法
映像、音声、テキスト情報の何らかの組み合わせを含む一つまたは複数のマルチメディア入力ストリームの閲覧を容易にし、改善するシステムが、マルチメディア要約を生成することでユーザーがマルチメディア入力ストリームをブラウズし、あるいは全体を視聴することを決め、あるいはその両方を行いやすくする。前記マルチメディア要約は、システム指定、ユーザー指定ならびにネットワークおよび機器上の制約に基づいて自動的に構築される。本発明の特定の用途においては、前記入力マルチメディアストリームはニュース放送(たとえばテレビのニュース番組、ビデオ保存庫の映像)を表す。そのような特定の用途においては、本発明によって、ユーザーは、事前に与えられたユーザーの好み設定ならびに支配的なネットワークおよびユーザー機器の制約に基づくニュースストリームの要約を自動的に受け取ることができる。  (もっと読む)
(もっと読む)
特許明細書分析システム及び特許明細書分析方法及びプログラムを記録したコンピュータ読み取り可能な記録媒体及びプログラム
【課題】特許出願又は特許に係る明細書(以下、特許明細書という)を分析する特許明細書分析システムに関し、明細書に含まれる語句を抽出し、その頻度を視覚的に表示し、利用者による明細書の内容把握を容易にすることを課題とする。
【解決手段】語句抽出部5は、明細書文書データ取得部1で取得した特許明細書の文書データ中から、記載されている欄と対応付けて語句を抽出し、語句出現頻度算出部3は、記載欄の重み付けに従って、1以上の欄からなるグループ毎の出現頻度を算出し、出現頻度出力部4により、語句毎の出現頻度をグループ毎に積み上げたグラフとして表示する。
(もっと読む)
URL指定装置及びURL指定プログラムを記録した記録媒体
【課題】 自然言語を入力するだけで、目的サイトに接続することができるURL指定装置及びURL指定プログラムを記録した記録媒体を提供する。
【解決手段】 URL指定装置1は、自然言語を入力する自然言語入力部10、作成されたURLに接続しURLサイトのデータを読み取って表示するブラウザ部11、入力された自然言語よりキーワードとなる語句を抽出する自然言語解析部12、データベース3,14の蓄積情報を用いて抽出されたキーワードから目的とするURLを作成するとともに、URLになり得る語句をユーザの嗜好などに合わせて並べ替える学習を行う学習機能部13、及びキーワードに対応したURLを蓄積する個人用データベース14を備えて構成する。
(もっと読む)
メール応対管理サーバおよびその方法、ならびに同方法がプログラムされ記録された記録媒体
【課題】 顧客から発せられる大量のメール問合せに対し、迅速で適切な内容で一定レベルの回答を行うシステムを構築する。
【解決手段】 顧客から発せられる大量のメール問合せを情報管理サーバ11で一括管理し、ここで自動的にメールを適切な担当者に仕分け、そのメールにあらかじめ適切な回答を添付することで、迅速で適切な内容で一定レベルの回答を要求のあった顧客のクライアント端末17に送信する。また、担当が手動で適切な回答を検索して適用し、その検索適用した行為を情報管理サーバ11が内蔵するDBに履歴として蓄積、管理することにより、自動的に添付した回答と担当者が適用した回答を比較することで、メール添付する回答の評価を行ない、より適切な回答をメール添付する。
(もっと読む)
キーワード検索装置
【課題】 ユーザ興味対象に関連したキーワードを自動生成し、ユーザ興味対象を的確に反映した検索が可能な環境を提供することができるキーワード検索装置を提供することを目的とする。
【解決手段】 二次記憶装置5のウェブサーバ6は、検索のためのキーワードを入力する検索GUI部7と、入力キーワードの文字列を取得するキーワード取得部8と、キーワードを含むコメントを取り出すキーワード検索処理部9と、与えられた日本語文章から品詞と単語を決定する形態素解析処理部11と、決定された単語の中から名詞だけを抽出する名詞選択部12と、日本語文章を単語毎に分割して品詞と共に取り出す単語切出し処理部10と、取り出した単語を使用回数の多い順に整理する単語ヒストグラム作成部13とを有し、キーワード検索処理部9は使用回数の多い単語をキーワードとして再度コメントを検索する。
(もっと読む)
自然言語検索支援システムおよび自然言語検索支援方法
【課題】自然言語検索機能を有しない既存のデータベースに対する自然言語検索を実現する自然言語検索支援システムを提供する。
【解決手段】登録部11は、自然言語検索機能を有しない既存データベースAのデータの中から抽出スキーマファイル14で定義された部分のみを抽出し、既存データベースAにおける参照先であるURLとともに自然言語解析部12に引き渡す。自然言語解析部12は、そのデータを自然言語解析し、その解析結果とURLとを対応づけてインデックスデータベース15に格納する。その後、ブラウザBを介して自然言語による検索文が入力されると、自然言語解析部12は、この検索文を自然言語解析し、その解析結果を基にインデックスデータベース15から対応するURLを取得する。そして、ブラウザBは、自然言語解析部12により取得されたURLを用いて既存データベースAのデータを参照する。
(もっと読む)
781 - 794 / 794
[ Back to top ]