
Fターム[5B075NK43]の内容
検索装置 (67,127) | 検索キー情報 (8,147) | 検索キー情報の格納形態 (1,488) | 構造化 (1,350) | 階層構造 (409)
Fターム[5B075NK43]に分類される特許
1 - 20 / 409
情報処理システム、情報生成装置、情報提供装置、情報生成方法、情報提供方法、情報生成プログラム、および情報提供プログラム
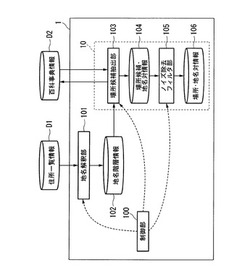
【課題】場所に関連する情報とその場所を含む地域とを関係付けることができること。
【解決手段】場所地名生成部(10)は、地域を識別する地域識別情報と地域の包含関係に基づいた階層関係を示す階層情報とが対応付けられた地名階層情報と、解説文書の見出語が階層関係で関係付けられたカテゴリ情報と、に基づいて、地域識別情報に関するカテゴリ情報から場所に関連する場所関連情報を抽出し、抽出した場所関連情報と当該地域識別情報についての地名階層情報とを対応付けた場所地名情報を生成する。
(もっと読む)
プログラム及び画像処理装置

【課題】プログラム及び画像処理装置において、登録されている画像の撮影条件と照合する入力画像の撮影条件の違いにかかわらず正確な画像照合を行うことを目的とする。
【解決手段】入力された画像データの各フレームに対して特徴点を抽出し、抽出した特徴点に基づいて入力特徴ベクトルを算出する前処理部と、検出対象画像の特徴点の特徴ベクトルをノードとし、カテゴリ毎に当該カテゴリを代表する代表特徴ベクトルと特徴ベクトルのサンプルがメンバーであるサブツリーで接続されると共に検出対象毎のクラスにクラスタ化された木構造が登録された記憶部と、第1段階では前記入力特徴ベクトルと前記記憶部内のクラスとのマッチングを行い、第2段階ではマッチングされたクラス内の各メンバーとのマッチングを行いマッチングすると認識された検出対象のデータを出力する認識部を備えるように構成する。
(もっと読む)
文書評価支援システム、及び文書評価支援方法
【課題】予め定義した任意の文書内容の標準文書構造化データに対して、入力した文書の内容が関連する箇所を可視化することを支援する文書評価支援システムを提供する。
【解決手段】任意の文書の内容についての標準文書構造化データを保管する標準文書構造化データ保管装置、入力文書を文書構造化データに変換する構造化文書変換装置、構造化文書変換装置によって変換された文書構造化データを保管する文書構造化データ保管装置、標準文書構造化データと入力文書構造化データとを比較,評価する構造化データ比較評価装置、入力した文書の中から要注意箇所を抽出して、要注意箇所に対する参考情報を作成する参考情報作成装置、標準文書構造化データと入力文書構造化データとの比較結果から各語句の評価スコアを算出して蓄積する評価結果保管装置、評価結果に応じてグラフや語句の表示を変更する評価結果表示装置を備える。
(もっと読む)
グループ化装置およびエレメント抽出装置
【課題】ネット上において特定ユーザーの個人領域ページを特定し、ページ内に含まれるエレメントを抽出する。
【解決手段】第1のアドレスキーと第2のアドレスキーの類似度がしきい値以上と判断された場合に、URLを特定のアドレス群として関連付ける(個人領域の特定)。さらに、イメージ化したWebページ上に点を配置し、配置した点を含むエレメントの階層構造を統合などして、対応する内容データを抽出する(エレメントの抽出)。
(もっと読む)
パケット分類システム、パケット分類方法、及びパケット分類用プログラム
【課題】パケットを分類するためのルールを検索するパケット分類器を提供する。
【解決手段】パケット分類器(1)は、振り分け処理部(11)と、第1のルール比較部(12)と、第2のルール比較部(13)を備える。振り分け処理部(11)は、振り分けポリシーを記憶する。第1のルール比較部(12)は、ルール集合を2つ以上の部分集合に分類して記憶する。第2のルール比較部(13)は、ルール集合を分類せずに記憶する。振り分け処理部(11)は、検索キーを該部分集合に振り分ける。第1のルール比較部(12)は、該振り分け結果に基づいて対応する部分集合内のルールと比較して検索キーに一致するルールを出力する。第2のルール比較部(13)は、該振り分け結果に関係なく記憶している全てのルールと比較して検索キーに一致するルールを出力するように動作する。
(もっと読む)
アンダーフロー処理装置並びにアンダーフロー処理方法
【課題】削除速度と木の検索速度のトレードオフを調整可能なアンダーフロー時の多次元インデックスの処理技術を提供する。
【解決手段】判定手段は、点削除が行われたノードにおいてアンダーフローが発生しているか否かを判定し、発生している場合には、発生しているノードの情報を得る。検索手段は、前記アンダーフローが発生しているノードの中心座標QからカレントノードのセルCまでの最短距離及び許容誤差係数εにより定まる調整可能な値が、最近傍ノード候補リストに格納されている距離より小さいか否かを判定することにより最近傍ノードを決定し、当該最近傍ノードの情報を得る。授受手段は、アンダーフローが発生しているノードと、前記検索手段より得られた最近傍ノードとの間で点若しくはセルの授受を行う。
(もっと読む)
住所検索装置及び住所検索方法
【課題】住所の構造を考慮した住所検索を可能とする。
【解決手段】住所検索装置は、住所に含まれうる単語を、住所の階層を示す階層情報と対応付けて記憶する辞書記憶部と、住所の階層間の連続可能性を示すコスト情報を記憶するコスト記憶部と、検索用の住所データを記憶する検索用マスタ記憶部と、住所を検索するための検索文字列を含む検索要求を受け付ける検索要求受付部と、検索文字列を辞書記憶部に記憶されている単語で分割して得られる検索単語の組み合わせのうち、連続可能性の高い検索単語の組み合わせを、コスト情報に基づいて出力する検索文字列分割部と、検索用マスタ記憶部に記憶されている住所データの中から、検索文字列分割部から出力される検索単語が含まれる住所データを検索する検索部と、検索単語との一致度に応じて検索部の検索結果を出力する検索結果出力部と、を備える。
(もっと読む)
検索装置
【課題】与えられた文字列が、登録されていることの検出を少ない手間により行なう検索装置を提供する。
【解決手段】本発明の一実施形態として、複数の文字列をトークン列に変換し共通するトークン列を併合して構成される木構造データであり木構造データのノードには末端ノードまでの長さの最大値および最小値が関連づけられている木構造データを記憶するインデックスメモリと、検索する文字列をトークン列に変換するトークナイザと、トークナイザにより変換されたトークン列を走査しインデックスメモリに記憶されている木構造データのノードの子ノードを選択して根ノードを始点とする経路を検索し、ノードの子ノードの中から、末端ノードまでの長さの最大値および最小値の範囲内に未走査のトークン数を含む子ノードが存在しなければ、検索する文字列が複数の文字列の中に存在しないことを検出する検索装置を提供する。
(もっと読む)
N分木内部ノードの圧縮方法及び装置及びプログラム
【課題】 1つの比較キー(N分木のノードに設定される分岐判断の数値)のサイズを小さくする。
【解決手段】 本発明は、入力されたM個の整数列に対してN分木作成を行い、N分木をROOTノードから高さHずつの部分木に分解し、幅優先に並び替え、該部分木内の比較キーの表現空間を8×Sビットから8×Tビットに縮退する変換を行い、変換された比較キーを含むブロックを記憶手段に格納し、記憶手段からROOTノードを含むブロックを読み出し、入力された探索キーを初期化手段で行った変換処理と同様の変換処理を行い、変換された探索キーと読み出されたブロックの比較キーを比較する処理をリーフノードになるまで繰り返し、リーフノード内に該探索キーと同じ比較キーが存在する場合は、該比較キーに対応する整数列内の位置情報を出力する。
(もっと読む)
クラスタリング装置及びクラスタリング方法
【課題】データ点の分類を、木構造インデックスを生成しながら行う。
【解決手段】新規データ点が属すべきクラスタを、木構造インデックスを用いて検索する。新規データ点と、検索されたクラスタの中心点との距離が固定値未満である場合に、新規データ点を、クラスタに属させる。前記距離が固定値以上である場合に、新たなクラスタを生成して、その新たに生成したクラスタに新規データ点を属させる。
(もっと読む)
情報処理装置、情報処理方法、及びコンピュータプログラム
【課題】 トライ構造における検索の高速性を保ちつつ、部分一致検索、前後一致検索を可能とするために、N-gram構造の特徴をさらに取り込んで文字列キーワード検索を行う技術を提供すること。
【解決手段】 登録キーワードとして入力されたキーワードを用いてトライ構造データ及びN-gramデータを作成する。そして検索時には、それら両方のデータを使用して検索キーワードとして入力されたデータが含まれる登録キーワードを検索する。
(もっと読む)
相同性検索装置及びプログラム
【課題】特定のシード構造を使用せず、最適化マッチを適応的に生成可能な、ワードベース探索戦略に基づく相同性検索装置の提供。
【解決手段】相同性判定の編集距離閾値Tに対し、検索要求ワードWを段階的に分割する終端節点数T+1のワード二分木を生成し、各終端節点に対応する素ワード素ワードWiをクエリとして検索対象シーケンスSに対する完全検索を行い、完全マッチを抽出する。次いで、抽出した各完全マッチについて、ワード二分木に基づき、ワード二分木の各節点に対するワードを単位として素ワードWiを伸長し、検索対象シーケンスSの完全マッチ部分に所定の検索ウィンドウを追加した比較対象シーケンスと伸長した素ワードとの編集距離を算出し、編集距離がT以下ならば伸長した素ワードとのマッチを出力するという処理を繰り返す。
(もっと読む)
情報処理装置、情報処理方法、及びコンピュータプログラム
【課題】 複数の文字列をコンパクトに格納することができる簡潔木構造において、検索処理の計算コストを抑えた文字列登録検索装置及びその制御方法、文字列登録検索システム、プログラムを提供する。
【解決手段】 ダブル配列構造を構築してから簡潔木構造に変換する方法により、簡潔木構造において検索処理の計算コストを抑えた新たな簡潔木構造を実現する。
(もっと読む)
プログラム、情報処理装置、情報処理システムおよび情報処理方法
【課題】異なるグループに属する複数のデータを、グループ間を横断して簡易に処理対象とすることを課題とする。
【解決手段】ファイルが属するフォルダを、ツリー構造をもって管理するコンピュータ10に、ツリー構造によって管理されている所定のフォルダから、ツリー構造を少なくとも1階層遡った上位フォルダを特定するステップS104と、ツリー構造において、上位フォルダに従属する従属フォルダに属するファイルを、処理対象とするステップS501と、を実行させる。
(もっと読む)
サーバ装置
【課題】言葉やフレーズなどで具体的に特定できない情報や漠然としたニーズに対応する情報を検索するサーバ装置を提供する。
【解決手段】ユーザ端末3と通信ネットワークNWを介して接続されたサーバ装置1であって、店舗の特徴を示す複数の特徴データを分類して階層的に連付けた特徴データベース20と、ユーザ端末3に対して、階層毎に特徴データを提示すると共に提示した特徴データの選択を受け付ける画面情報を送信すると共にユーザ端末3が画面情報上で指定した特徴データにより店舗情報を検索する情報提供部11とを備えている。また、店舗データベース20は、上位階層に店舗の概念的なニーズを示した特徴データが配置され、上位階層から下位階層に向かうにしたがい段階的に店舗の具体的なニーズを示した特徴データが配置されている。
(もっと読む)
情報処理装置、情報処理装置の処理方法及びプログラム。
【課題】画像ファイルを管理するフォルダの階層構造に従って画像ファイルの検索条件を視覚的に表示することで、画像ファイルの検索を容易に行うことができる仕組みを提供すること。
【解決手段】画像ファイルを管理するフォルダの階層情報を記憶する階層情報記憶手段と、検索条件の入力を受け付け、入力された検索条件と前記フォルダに対応付く情報とが一致したフォルダを特定し、特定したフォルダと前記階層構造から、検索条件として選択可能なフォルダに対応付く情報を分類し、分類した情報を表示し、表示した情報を指定し、フォルダの特定は、指定された情報と前記フォルダに対応付く情報とが一致したフォルダを特定し、分類は、前記特定したフォルダと前記階層構造から、再度検索条件として選択可能なフォルダに対応付く情報を分類する。
(もっと読む)
検索支援装置、検索支援方法、および検索支援プログラム
【課題】検索前処理および検索処理との処理時間の短縮化を図ること。
【解決手段】検索支援装置が、複数の節点に付された検索条件のうちの特定の検索条件として、「虎ノ門」の入力を受け付ける。検索支援装置が、検索条件として「虎ノ門」が付された節点を特定する。対象データとして「B店」を有している節点と、対象データとして「F店」を有している節点と、が特定される。検索支援装置が、木構造データ100の葉から、対象データとして「B店」を有している節点を経由する根までの経路1を探索する。検索支援装置が、木構造データ100の葉から、対象データとして「F店」を有している節点を経由する根までの経路2を探索する。検索支援装置が、探索した経路1,2を出力する。検索支援装置が、探索した経路1,2上の節点を検索対象節点に設定し、設定後の木構造データ100を出力する。
(もっと読む)
撮像装置、制御方法及びプログラム
【課題】通信手段が利用できない場合や予めメタデータを登録していない場合においても、撮像装置の設定によりメタデータを自動的に付加する
【解決手段】撮像装置は、画像を撮影し、位置情報を取得し、ユーザ操作に応じて設定されたユーザのスケジュール情報を記憶し、スケジュール情報に紐付く予定名と同名のフォルダを生成し、撮影された画像が記憶されたスケジュール情報に一致するか否かを判定を行い、画像が記憶されたスケジュール情報に一致すると判定された場合、スケジュール情報に紐付く予定名を画像の画像データに付加し、スケジュール情報の予定名が付加された画像を、予定名と同名のフォルダに格納する。
(もっと読む)
索引方法、検索方法、及びその記憶媒体
【課題】本発明の課題は、高次元特徴ベクトル空間における画像探索用のツリー生成を効率的に行い、画像探索を効果的に行えるようにすることを目的とする。
【解決手段】上記課題は、コンピュータが、サンプル画像の特徴を現す高次元特徴ベクトルによる高次元ベクトル空間において該サンプル画像を索引付けする索引方法であって、該コンピュータが、前記高次元特徴ベクトルを表現する複数の属性からランダムに選択された所定数の属性を用いて、複数のサンプル画像の該ランダムに選択された属性の属性値に基づいて該所定数を次元とするツリーを生成するツリー生成手順を実行する索引方法によって達成される。
(もっと読む)
ブログ本文特定装置及びブログ本文特定方法
【課題】制御負荷を抑えつつブログ本文の特定を可能なブログ本文特定装置及びブログ本文特定方法を提供すること。
【解決手段】ブログ本文特定装置(1)の第1起点特定部(2)は、同一ユーザに対応付けられた複数のブログページを解析して、当該複数のブログページの夫々について、ソースコードに含まれるタグの当該ソースコード内でのパスを示す外部パス情報を生成し、この外部パス情報からタグを一意に特定でき(共通パス)、かつ、本文を含んでいるパス(本文包含パス)であっても最も深いパスを、ブログ本文を含む起点パスとして特定する。そして、ブログ本文特定装置(1)のブログ本文抽出手段(5)は、この起点パスに基づいて、当該ユーザのブログページの本文を抽出する。
(もっと読む)
1 - 20 / 409
[ Back to top ]