
Fターム[5B080CA08]の内容
Fターム[5B080CA08]の下位に属するFターム
メモリアドレス制御 (40)
Fターム[5B080CA08]に分類される特許
61 - 80 / 105
レイトレース・レンダリングのための並列化された交差テストおよびシェーディングのアーキテクチャ

【課題】 レイトレース・レンダリングのための並列化された交差テストおよびシェーディングのアーキテクチャを提供する。
【解決手段】 実施例では、シーンのレイトレーシングは、リンク/キューを介して全体として通信する複数のシェーディング資源と連結された複数の交差テスト資源を使用する工程を含む。テストからシェーディングへのキューは、レイ識別子を含むそれぞれのレイ/プリミティブ交差指標を含む。シェーディングからテストへのキューは、テストされる新しいレイの識別子を含み、レイを定義するデータは交差テスト資源の間に分散させられたメモリに別個に格納される。レイ定義データは、レイ識別子に基づいて複数回に亘りテストのため選択可能である場合、レイが交差テストを終了するまで、分散メモリの中で維持することが可能である。アクセラレイション形状の構造が使用可能である。レイ識別子および形状データのパケットは、交差テスト資源の間を循環可能であり、各交差テスト資源はパケットの中で特定されたレイをテスト可能であり、そのレイのための定義データが交差テスト資源のメモリの中に存在する。アクセラレイション形状テスト結果は、交差した形状に基づいてレイのコレクションを可能にさせ、最近傍検出レイ/プリミティブ交差はシェーディングのためのレイ識別子をキューイングすることによって指示される。
(もっと読む)
一般作業負荷およびグラフィックス作業負荷を処理するための統合プロセッサアーキテクチャ

1つ以上の制御ユニットと、複数の第1の実行ユニットと、1つ以上の第2の実行ユニットとを備えるプロセッサである。プロセッサ命令セットに適合するフェッチされた命令が、第1の実行ユニットに送られる。第2の命令セット(プロセッサ命令セットとは異なる)に適合するフェッチされた命令が、第2の実行ユニットに送られる。第2の実行ユニットは、グラフィックス演算を実行するように構成され、またはJavaバイトコード、マネージドコード、ビデオ/オーディオ処理演算、暗号化/復号化演算などの実行のような他の特殊な機能を実行するように構成されてもよい。第2の実行ユニットは、コプロセッサのように動作するように構成されてもよい。単一の制御ユニットが、すべての実行ユニットに対するフェッチ、デコード、およびスケジューリングを処理してもよい。他の形態として、マルチ制御ユニットが、実行ユニットの異なるサブセットを処理してもよい。 (もっと読む)
複数のグラフィックサブシステムおよび低電力消費モードを有するコンピューティングデバイス用ドライバアーキテクチャ、ソフトウェアおよび方法
現在、多くのコンピューティングデバイスが2つ以上のグラフィックサブシステムを備えることがある。複数のグラフィックサブシステムは、能力が異なり、電力消費量が異なることがあり、例えば、あるサブシステムが別のサブシステムよりも多くの平均電力を消費することがある。電力消費の高いグラフィックサブシステムがデバイスに結合されて、低電力消費グラフィックサブシステムの代わりに、またはこれに追加して使用されることがあるが、性能向上と付加の能力が得られるが、全体的な電力消費が増大してしまう。電力消費の高いグラフィックサブシステムを低電力消費モードに設定しつつ、電力消費の高いグラフィックサブシステムの使用から低電力消費グラフィックサブシステムへ切り替えることによって、全体的な電力消費が低減される。プロセッサがアプリケーションソフトウェアおよびドライバソフトウェアを実行する。前記ドライバソフトウェアは、前記第1のグラフィックサブシステムの動作を制御する第1のドライバコンポーネントと、前記第2のグラフィックサブシステムの動作を制御する第2のドライバコンポーネントとを含む。第1のグラフィックシステムおよび第2のグラフィックシステムのいずれが使用中であるかに応じて、別のプロキシドライバコンポーネントが、第1のドライバコンポーネントおよび第2のドライバコンポーネントのいずれかにコール(例えばAPI/DDIコール)を転送する。  (もっと読む)
(もっと読む)
マルチテクスチャマッピング装置、およびマルチテクスチャデータのメモリ格納方法
【課題】マルチテクスチャの各要素テクスチャにおける同一位置の画素データをグラフィックスメモリから読み出す場合に、データアクセスを高速化し、システムの処理性能を向上させる。
【解決手段】テクスチャに対して同一位置にある、各要素テクスチャにおける複数の画素データが、同一位置毎に1つの画像データ格納メモリ上に連続して並ぶように、画素データの格納位置を決定する画素データ格納位置決定部と、決定された格納位置にしたがって、複数の画素データを1つの画像データ格納メモリに格納する画素データ格納部とを備える。
(もっと読む)
情報処理装置、および情報処理方法、並びにコンピュータ・プログラム
【課題】レジスタ、演算部などを備えたデータ処理部において、効率的なデータ処理および実装面積の削減を実現した構成を提供する。
【解決手段】レジスタ、演算部などを備えたデータ処理部において、複数の命令テーブルの切り替えや命令の多重化により効率的に命令を実行し、またダブルバッファ構成とした入出力レジスタを利用したデータ格納制御により入出力のオーバーヘッドや命令のレイテンシの解消を図り処理の高速化を実現した。本構成により、命令の圧縮・伸長によるバスバンド幅、外部IO、メモリ容量の小型化が実現され、データ処理部を構成するLSIの論理回路の実装面積の削減、さらに消費電力の低減が実現される。
(もっと読む)
図形描画装置
【課題】少ないハードウェア規模で効率よく図形描画処理を実行することのできる図形描画装置を得る。
【解決手段】SIMDプロセッサ101は、3Dグラフィックスのジオメトリ処理とベクターグラフィックスのエッジ交点算出処理を行い、これらの処理結果を共通のSP出力バッファ104〜107に出力する。ピクセルシェーダ112は、3Dグラフィックス及びベクターグラフィックスにおけるピクセルシェーダ処理を行う。フラグメント処理部114は、3Dグラフィックスではデプスバッファ、ベクターグラフィックスではマスクバッファとして用いる第1の補助バッファ116と、3Dグラフィックスではステンシルバッファ、ベクターグラフィックスではシザーバッファとして用いる第2の補助バッファ117と、共通に用いるカラーバッファ115を用いて、フラグメント処理を行う。
(もっと読む)
タイルリニアホストテクスチャストレージ
【課題】ポリゴン情報が、マトリクス構成の情報の領域又はタイルブロックの形式で整理、格納、及び転送される、グラフィックスアプリケーションのための処理および実行コンピュータシステムを提供する。
【解決手段】テクセル情報のポリゴンバイトは、キャッシュヒット効率の向上のために、グラフィックスサブシステム内に、例示的な8×8マトリクスの行及び列のフォーマットで整理され、ホストストレージがグラフィックスキャッシュを再び満たすためにアクセスされた場合に、ホストストレージ装置のリニアアドレススキームヘ変換、又はリニアアドレススキームから変換される。メモリタイルのポリゴン情報を含むバイトは、完全な1タイル分の情報が、通常のマルチラインアクセスのアービトレーション及び他の典型的なアクセス遅延を最小限に抑えるために、1回のバースト方式ホストメモリアクセスで転送されるように構成される。
(もっと読む)
アプリケーションの変更前にコマンドの変更のパフォーマンスを解析するためのグラフィックコマンド管理ツールおよびその方法
アプリケーションのためにビデオフレームレンダリング特性の最適化を可能にする方法、システム、グラフィカルコンピュータインタフェース、および計算機可読媒体が開示される。前記方法は、ビデオフレームをレンダリングするステップと、前記ビデオフレームの前記レンダリングを表すプッシュバッファ設定をキャプチャするステップと、を有する。また、前記方法は、前記アプリケーションをバイパスすることにより前記プッシュバッファ設定のアスペクトを変更するステップと、前記変更されたアスペクトにより前記フレームを再レンダリングするステップと、も有する。更に、前記方法は、前記レンダリングを前記再レンダリングと比較するステップと、比較結果を提示するステップと、を有する。アプリケーションのコードを変更せずに、パフォーマンス、レンダリングおよび処理の効率に関して、可能な変更の、アプリケーションに対する寄与を評価するための機能を可能にするグラフィカルユーザインタフェースが提供される。 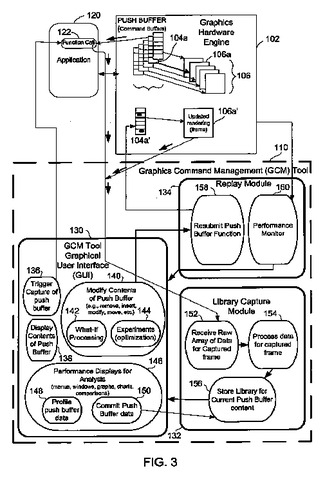 (もっと読む)
(もっと読む)
マルチテクスチャリングのための動的に構成可能なテクスチャキャッシュ
テクスチャキャッシュを動的に構成するための技術を開示する。三次元(3D)グラフィックスパイプラインのテクスチャマッピング処理の間に、バッチがシングルテクスチャマッピングに対するものである場合には、テクスチャキャッシュは、nウェイのセットアソシエイティブテクスチャキャッシュとして構成される。しかしながら、バッチがマルチテクスチャマッピングに対するものである場合には、nウェイのセットアソシエイティブテクスチャキャッシュは、1組のM個のn/Mウェイのセットアソシエイティブサブキャッシュへと分割され、ここで、nとMは1より大きい整数であり、nはMによって割り切れる。 (もっと読む)
画像処理装置
【課題】ピクセルデータの転送を高速に行い、効果的にレンダリング処理を行う。
【解決手段】単位図形の頂点について3次元座標、R,G,Bデータ、テクスチャの同次座標(s,t)および同次項qを含むポリゴンレンダリングデータを受けてレンダリング処理を行う画像処理装置は、複数に分割された記憶モジュールと、各記憶モジュールに近接配置された2次メモリと、各記憶モジュール毎に対応して分割された複数のピクセル処理モジュールとを有する。各記憶モジュールがテクスチャデータを記憶している。各ピクセル処理モジュールが、ポリゴンレンダリングデータを補間する回路と、「s/q」および「t/q」を生成してこれらに応じたテクスチャアドレスを用いて2次メモリを介して対応する記憶モジュールからテクスチャデータを読み出し、表示データの図形要素の表面へのテクスチャデータの張り付け処理を行う回路とを有する。
(もっと読む)
3次元グラフィック加速器及びそのピクセル分配方法
【課題】テクスチャキャッシュのミス率を減少させることができるピクセル分配器を提供する。
【解決手段】3次元グラフィック加速器は、制御信号を中央処理装置から受けて格納するレジスタと、前記レジスタから前記制御信号に応答してポリゴンの情報を生成する幾何学処理部と、前記幾何学処理部から前記ポリゴンの情報を受信してピクセルを出力するラスタライザと、前記ラスタライザから前記ピクセルを受信し、前記制御信号に応答して、前記ピクセルを複数のピクセルシェイダに分配するピクセル分配器と、を備え、前記制御信号は、前記ピクセルがテクスチャマッピング、デプステスト、及びブレンディングのうちのいずれか1つ以上を使用する場合に活性化される。
(もっと読む)
3次元グラフィックスパイプラインの自動負荷分散
デバイスは、3次元(3D)グラフィックスパイプラインの頂点処理ステージ、サブ画面分割ステージおよびピクセルレンダリングステージを処理するためのプロセッサを有する。プロセッサは、ピクセルレンダリングステージのための処理を他のステージより優先させることによって3Dグラフィックスパイプラインの作業負荷を分散する処理スレッドを含む。並行に独立して動作する各処理スレッドはサブ画面タスクのタスクリストにおけるタスクのレベルを検査する。レベルがしきい値より下にある、空である、またはサブ画面タスクがすべてロックされている場合、処理スレッドは頂点処理ステージにループする。そうでない場合、処理スレッドはピクセルレンダリングステージ中にサブ画面タスクを処理する。 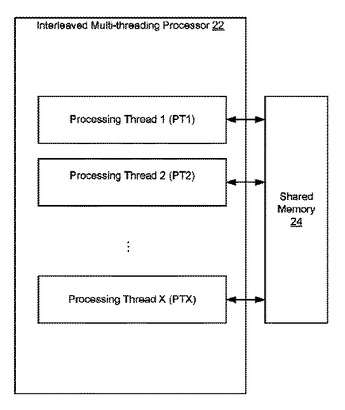 (もっと読む)
(もっと読む)
高速ピクセル・レンダリング処理
最終ステージ(ピクセル・レンダリング)において、サブスクリーンのピクセルを並列かつ独立に処理する、三次元(3D)グラフィックス・パイプライン。サブスクリーンタスクは共有メモリーのリストに保存されている。共有メモリーは、ピクセル・レンダリング処理に割り当てられた複数個の処理スレッドからアクセスされる。処理スレッドは、サブスクリーンタスクを順序に従って、捕捉し、ロックし、スクリーン上に表示するビットマップを生成するタスクを実行する。タスクは、頂点情報が重ねあわされている表示エリアを分割することにより、M×Nサブスクリーンタスクに生成される。システム分析に基づいて、MおよびNの値は変化する。 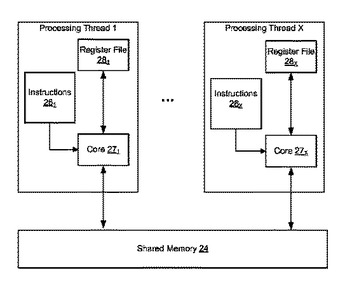 (もっと読む)
(もっと読む)
画像処理装置及びその制御方法、プログラム
【課題】 レンダリング処理能力及びバンドメモリ幅に基づきタイルベクタの分割サイズを決定し、省メモリで効率的なレンダリング処理を実現する画像処理装置及びその制御方法、プログラムを提供する。
【解決手段】 ラスタ画像データを、設定された第1ブロックサイズのブロックに分割し、各ブロックにベクトル化処理を実行することで、前記ラスタ画像データをブロックベクタ画像データに変換する。ブロックベクタ画像データをラスタ画像データに展開する。処理対象の前記ブロックベクタ画像データを展開に要する予測時間を予測する。予測した予測時間に基づいて、前記処理対象のブロックベクタ画像データを、前記第1ブロックサイズよりも小さい第2ブロックサイズのブロックベクタ画像データに再変換する。得られるブロックベクタ画像データを展開して得られるラスタ画像データを画像出力部に出力する。
(もっと読む)
テクスチャマッピング方法、プログラム及び装置
【課題】滑らかなシェーディングを可能にするとともに、メモリ資源の節約に好適なテクスチャマッピング方法を提案する。
【解決手段】テクスチャデータ(20)のU座標方向及びV座標方向に対して濃淡勾配を形成するように、色調の異なるデータ領域C1〜C10を設定する。テクスチャマッピングを施すオブジェクト表面の輝度をIとすれば、テクスチャデータにアクセスするための読み出し座標のうちU座標をU=a*I+bとして算出し、V座標をV=dから求める。動的変数dの値はアプリケーションの用途に応じて適宜設定することができる。テクスチャデータ(20)は互いに直交する2方向に対して色調の濃淡勾配が形成されているため、滑らかなシェーディングを可能にしつつ、複数のテクスチャメモリを集約した構成となっているため、メモリ容量の節約にもなる。
(もっと読む)
3Dグラフィック回路のための画素キャッシュ
デバイスメモリと、ハードウェアエンティティと、サブ画像セル値キャッシュと、キャッシュ書込みオペレータとを含む装置が提供される。ハードウェアエンティティのうちの少なくともいくつかは、デバイスメモリへのアクセス及びデバイスメモリの使用を含む動作を実行する。ハードウェアエンティティは、プリミティブオブジェクトからの3D画像を表示するために処理する3Dグラフィック回路を含む。キャッシュは、デバイスメモリから分離されており、バッファされたサブ画像セル値を含むデータを保持するために提供される。キャッシュは、3Dグラフィック回路の画素処理部分が、デバイスメモリ内のサブ画像セル値に直接アクセスする代わりに、キャッシュ内のバッファされたサブ画像セル値にアクセスするように、3Dグラフィック回路に接続される。書込みオペレータは、バッファされたサブ画像セル値を、優先スキームの指示の下、デバイスメモリへ書き込む。優先スキームは、1つ又は複数のプリミティブオブジェクトを境界付ける境界セル値をキャッシュ内に保存する。  (もっと読む)
(もっと読む)
三次元コンピュータ映像を発生するシステムのためのメモリマネージメントの改良
【課題】メモリの占有面積を減少すると共に性能を改善するメモリマネージメントシステム及び方法を提供する。
【解決手段】三次元コンピュータ発生映像を発生するシステムに使用するためのメモリマネージメントシステム及び方法が提供される。この方法は、映像を複数の長方形エリアに細分化するステップと、各長方形エリアに対するオブジェクトデータを記憶する1つ又は複数の第1部分、及びオブジェクトデータから導出される深さデータを記憶する1つ又は複数の第2部分をいつでも有しているメモリを準備するステップと、メモリの1つ又は複数の第1部分にオブジェクトデータを記憶するステップと、オブジェクトデータから各長方形エリアに対する深さデータを導出するステップと、各長方形エリアに対する深さデータをメモリの1つ又は複数の第2部分に記憶するステップと、既存のコンテンツの少なくとも一部分に置き換えるようにメモリの1つ又は複数の第1部分のうちの1つ以上に更なるオブジェクトデータをロードするステップと、記憶された深さデータを検索するステップと、新たなオブジェクトデータ及び記憶された深さデータから各長方形エリアの各画素に対する更新された深さデータを導出し、そしてその更新された深さデータを、以前に記憶された深さデータに置き換えるように記憶するステップと、メモリにロードすべき更なるオブジェクトデータがなくなるまで前記4つのステップを繰り返すステップと、表示のために、映像データ及び陰影付けデータを深さデータから導出するステップと、を備えている。
(もっと読む)
画像処理装置
【課題】テクスチャ・マッピングの高速化の妨げになる外部メモリからキャッシュメモリへのテクスチャデータのキャッシングを避け、描画速度の向上を図ることができるようにした画像処理装置を提供する。
【解決手段】テクスチャを貼り付ける三角形ごとにテクスチャデータ使用率が境界値以上であるか否かを判定し、境界値以上の場合は、キャッシュメモリ15を有効とし、境界値未満の場合は、キャッシュメモリ15を無効とする制御部31を備えることにより、外部メモリ5からのテクスチャデータのキャッシュメモリ15へのキャッシングは、テクスチャを貼り付ける三角形のテクスチャデータ使用率が境界値以上の場合にのみ行われ、境界値未満の場合には行われないようにする。
(もっと読む)
構成可能なキャッシュを有するグラフィックスシステム
グラフィックスシステムがグラフィックスプロセッサおよびキャッシュメモリシステムを含んでいる。グラフィックスプロセッサは、グラフィックス画像をレンダリングするための種々のグラフィックス動作を行う処理ユニットを含んでいる。キャッシュメモリシシテムは、完全に構成可能なキャッシュ、部分的に構成可能なキャッシュ、または構成可能キャシュと専用キャッシュの組み合わせを含んでいてもよい。キャッシュメモリシシテムは、制御ユニット、クロスバー、およびアービターをさらに含んでいてもよい。制御ユニットは、処理ユニットによるメモリ利用を判定し、そしてメモリ利用に基づいて構成可能なキャッシュを処理ユニットに割り当てうる。これらのキャッシュの良好な利用を実現するためおよびメモリアクセスボトルネックを回避するために、構成可能なキャッシュが割り当てられうる。クロスバーは、処理ユニットをそれらの割り当てられたキャッシュに結合する。アービターは、キャッシュとメインメモリとの間のデータ交換を容易にする。
(もっと読む)
描画装置及び描画処理方法
【課題】効率的・高速な描画処理を実現するとともに描画処理のエラーの原因となる不適切なリード・モディファイ・ライトのタイミングを回避する。
【解決手段】オンチップバス1003を介しアクセス可能なメモリに対し描画処理を実行する描画装置1005。その論理演算処理装置2003は、描画処理のためにリード要求コマンドを、それに対するリード応答を待つことなく連続的に発行し、発行済みの各リード要求コマンドに対しリード応答が返った時に、そのリードデータに論理演算処理を施したライトデータを前記メモリの当該リード要求コマンドと同一のアドレスへ書き込むライト要求コマンドを発行するが、リード応答が未だ返されない発行済みリード要求コマンドと同じアドレス対する新たなリード要求コマンドの発行を抑止する。
(もっと読む)
61 - 80 / 105
[ Back to top ]