
Fターム[5B080CA08]の内容
Fターム[5B080CA08]の下位に属するFターム
メモリアドレス制御 (40)
Fターム[5B080CA08]に分類される特許
41 - 60 / 105
フレームバッファにおけるウィンドウ表示の形成
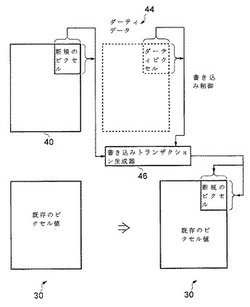
【課題】各タイルの全ピクセル値のこのような読み取りおよび書き込みを行うことは、不利に高い回数のメモリアクセスを要求する。その結果、スピードの低下およびエネルギー消費の増大が生じることとなる。
【解決手段】遅延描画コマンドを用いるウィンドウ表示は、タイルメモリ40内に記憶された1つまたは複数の新規のピクセル値を形成するようにフレームバッファ30のタイル22に対して書き込む描画コマンドを処理することにより動作する。タイルメモリ内のどのピクセルが、新規のピクセル値を記憶するダーティピクセルであり、タイルメモリ内のどのピクセルが、新規のピクセル値を記憶しないクリーンピクセルであるかを示すダーティピクセルデータも、形成される。ダーティピクセルデータに応じて、タイルメモリ内に記憶された新規のピクセル値は、フレームバッファメモリに対して書き込まれる。タイルメモリ内のクリーンピクセルに対応するフレームバッファメモリ内に記憶されたピクセルは、書き込まれることがないため、変更されないままとなる。
(もっと読む)
グラフィックスプロセッサの複数のディスプレイヘッドを用いたアンチエイリアシング

【課題】1つのグラフィックスプロセッサの複数のディスプレイヘッドを用いた画像データのアンチエイリアシングを提供する。
【解決手段】同じグラフィックスプロセッサ122の2つのディスプレイヘッド206が、画素転送パスを介してマスター/スレーブ形式で互いに結合されている。「マスター」ディスプレイヘッドは、それ自体の画素に加えて「スレーブ」ディスプレイヘッドから画素を受け取り、マスターディスプレイヘッド中の画素選択論理回路がこの2画素を混合するか、いずれか一方を選択して他方を除外する。2画素が同じ画像の異なるサンプリング位置に対応する場合には、混合した画素がアンチエイリアシング処理画素となる。
(もっと読む)
光散乱を推定するための方法
本発明は、異種成分からなる関与媒質(2)によって散乱された光の量を推定するための方法に関係する。必要とされる計算時間を最小にしつつレンダリングを最適化するために、本方法は、2つの連続する階層のレベルの間で少なくとも1つの方向(120)において、前記媒質中の光減衰差を表す誤差情報の少なくとも1つの部分に基づいて複数の空間細分割階層のレベルから前記媒質(2)の少なくとも1つの空間細分割レベルを選択するステップと、少なくとも1つの散乱方向(120)に沿った前記媒質(2)のサンプリングの手段によって散乱された光の量を推定するステップであって、サンプリングは少なくとも1つの選択した空間細分割レベルに基づく推定するステップとを含む。  (もっと読む)
(もっと読む)
エンコード済みのテクスチャ要素ブロックについて使用することができるデコーディングシステムおよび方法
デコーディングシステム(1)が、N個の異なるデコーダ(100、200、300、400)を備えており、各々のデコーダが、他のN−1個のデコーダの回路とは異なる独自の回路を有している。各々のデコーダ(100、200、300、400)が、入力されるエンコード済みのテクセルブロック(40)に基づいて少なくとも1つのテクセル値を生成する。値選択部(500)が、少なくともN個のテクセル(30〜36)のうちの少なくとも1つを含むテクセルブロック(10)の境界に対する、少なくともN個のテクセル(30〜36)の位置に基づいて、少なくともN個のテクセル値を、デコーダ(100、200、300、400)のうちの少なくとも1つから選択的に出力するように構成されている。ピクセル計算部(600)が、値選択部(500)からの少なくともN個の選択されたテクセル値に基づいて、デコード後のピクセルのピクセル値を計算する。 (もっと読む)
階層メッシュ量子化によるメモリ効率の優れたレイトレーシング
【課題】シーンの三角形および境界ボリューム階層(BVH)をコンパクトな1つのデータ構造としてエンコードする方法およびシステム。
【解決手段】インタラクティブなレイトレーシングにおいて、高効率かつ容易な復元が実行され利用されてよい。量子化された頂点および三角形のストリップは、BVHリーフノードに格納されてよい。ローカル頂点位置および頂点インデックスは、ビット列にエンコーディングされた少数のビットを用いてよい。トラバースの際には、最適なアルゴリズムでデコーディングし、オーバーヘッドが最小限であるランダムアクセスを実現してよい。
(もっと読む)
グラフィックス処理システム
【課題】グラフィックス処理システムにおけるフレームバッファ生成および類似のオペレーションに対する改善を提供すること。
【解決手段】トランザクション排除ハードウェアユニット5は、タイルベースのグラフィックスプロセッサによって生成されるタイルのメモリ2内のフレームバッファへの書き込みを制御する。トランザクション排除ハードウェアユニット5は、タイル毎にタイルの内容を表す署名を生成する署名生成器20を有する。署名比較器23は、グラフィックスプロセッサからの新しいタイルの署名をフレームバッファ内のタイルの署名と比較する。署名が一致しない場合、署名比較器23は、書き込みコントローラ24を制御して、新しいタイルをフレームバッファに書き込む。署名が一致する場合、フレームバッファにデータは何も書き込まれず、既存のタイルがフレームバッファ内に残る。
(もっと読む)
テセレーションエンジン及びそのアプリケーション
【解決手段】
グラフィクス処理を行うための方法、装置及びシステムが開示される。この点において、処理ユニットは、テセレーションモジュール及び接続性モジュールを含む。テセレーションモジュールは、幾何学的形状の部分を逐次的にテセレートして幾何学的形状に対する一連のテセレーション点を提供するように構成される。接続性モジュールは、テセレーション点の1つ以上のグループを一連のテセレーション点が提供される順序で1つ以上のプリミティブ内へと接続するように構成される。
(もっと読む)
複数のシェーダエンジンを伴う処理ユニット
【解決手段】
プロセッサは第1のシェーダエンジン及び第2のシェーダエンジンを含む。第1のシェーダエンジンは、ディスプレイデバイス上で表示されるべき画素の第1のサブセットのための画素シェーダを処理するように構成される。第2のシェーダエンジンは、ディスプレイデバイス上で表示されるべき画素の第2のサブセットのための画素シェーダを処理するように構成される。第1及び第2のシェーダエンジンの両方はまた、一般計算シェーダ及び非画素グラフィクスシェーダを処理するようにも構成される。プロセッサはまた、第1及び第2のシェーダに結合されると共にこれらの間に置かれるレベル1(L1)データキャッシュを含んでいてもよい。
(もっと読む)
画像処理装置
【課題】画像処理装置において、処理性能の低下を抑制すること。
【解決手段】テクスチャデータを格納するメモリ部1、メモリ部1に格納されているテクスチャデータの一部を格納するキャッシュ部2、キャッシュ部2に格納されているデータを参照して将来描画の対象となるピクセルがキャッシュミスを起こすか否かを判定する判定部3、判定部3によりキャッシュミスを起こすと判定された複数のピクセルの情報を保持する保持部4を備える。データ処理部5は、保持部4に情報が保持されているピクセルにより必要とされるデータがキャッシュ部2に格納されていない場合に、当該ピクセルよりも後のピクセルを次の描画対象とする。データ処理部5は、保持部4に情報が保持されているピクセルにより必要とされるデータがキャッシュ部2に格納されるときに当該ピクセルが現在の描画位置よりも前のピクセルである場合に、当該ピクセルを次の描画対象とする。
(もっと読む)
画像形成装置及び画像形成方法ならびに画像形成方法を実行するプログラム
【課題】 レンダリングのエッジ処理において、ページ内に大量のエッジが存在するデータを処理する場合、エッジ情報をロードした時点でCPUキャッシュに格納される。
しかし、他のエッジをロードしているとCPUキャッシュから溢れ、次にエッジ情報を用いてエッジ処理を行う際、メインメモリから情報をロードするので処理に時間がかかってしまう課題がある。
【解決手段】 これまでは、1スキャンライン分のエッジ情報を保持し処理していたのを、2つ以上のブロックに分割しそれぞれのブロックでエッジ情報を保持し処理することにより、近接するエッジが近接するメモリ上に保持される可能性が高くになる。その結果、キャッシュにミスヒット率が低下し処理速度の向上をはかることが出来る。
(もっと読む)
タイルベースの3Dコンピュータグラフィックシステムのマルチレベルディスプレイコントロールリスト
三次元コンピュータグラフィック画像をレンダリングするための方法及び装置が提供される。画像は、複数の長方形タイルへと分割され、それらタイルは、複数レベルの次第に大きくなるタイルグループより成るマルチレベル構造に配列される。画像データは、複数のプリミティブブロックへと分割され、それらプリミティブブロックは、各々が交差するグループに基づきマルチレベル構造内のタイルグループに指定される。画像をレンダリングするための制御ストリームデータが導出され、その制御ストリームデータは、マルチレベル構造の各レベル内の各タイルグループに対してプリミティブブロックへのリファレンスを含み、これらリファレンスは、各グループに指定されたプリミティブブロックに対応し、制御ストリームデータは、プリミティブデータを表示のためにタイルグループ内のタイルへとレンダリングするのに使用される。これは、グループ内の複数のタイルに交差するプリミティブブロックに対して、制御ストリームデータが、グループ内の各タイルではなく、タイルグループに対して書き込まれるように行われる。 (もっと読む)
写実的画像形成の処理負荷を分散するためのシステム及び方法
【課題】 改善された写実的画像形成の処理負荷を分散させるためのシステム及び方法を提供する。
【解決手段】 グラフィックス・クライアントが、シーン・モデル・データを含むフレームを受信する。サーバ負荷分散ファクタ及び予測レンダリング・ファクタを設定する。サーバ負荷分散ファクタ及び予測レンダリング・ファクタに基づいて、フレームを複数のサーバ帯域に分配する。サーバ帯域を複数の計算サーバに分散させる。計算サーバから処理済みサーバ帯域を受信する。受信した処理済みサーバ帯域に基づいて、処理済みフレームを組み立てる。画像としてユーザに表示するために、処理済みフレームを伝送する。
(もっと読む)
フレームバッファ管理のシステム及び方法
【課題】メモリ資源の最適な利用を実現する。
【解決手段】画像形成装置においてフレームバッファメモリ及びディスプレイリストメモリを有する単独のメモリプールのフレームバッファを管理する方法が開示されている。いくつかの実施形態においては、メモリプールから、少なくとも一つのピクスマップに割り当てられた等しいサイズのブロックを用いた画像に対応する前記ピクスマップを管理する方法は、前記画像のスキャンラインのうち少なくとも一つを求める要求を受け付けるステップと、前記メモリプールに使用可能なメモリブロックがある場合、前記スキャンラインのうち少なくとも一つを求める要求に対して前記メモリプールのブロックのうち少なくとも一つのブロックにポインタを固定するステップと、前記メモリプールに使用可能なメモリブロックがない場合、複数のメモリ解放方法のうち少なくとも一つを適用するステップと、を備える。
(もっと読む)
テクスチャ情報をコード化するための方法および装置
【課題】ピクセルに対するピクセル値が、記憶しているテクセル値から生成され、そのピクセルを生成したピクセル値に応じて表示させる。
【解決手段】ピクセルが、第1のテクセル基準値、第2のテクセル基準値、および第1のテクセル基準値、第2のテクセル基準値およびそれにより1つのテクセル・ブロックを表すための第3のテクセル基準値の3個からなる集合にテクセルをマッピングするために動作するテクセル値を記憶することによりテクスチャリングされる。他の実施形態の場合には、あるピクセルに対する第1のミップマップ値が、一組の最も近い隣接するテクセルに対する検索したテクセル値から二線補間される。ピクセルに対する第2のミップマップ値は、一組の最も近い隣接するテクセルに対する検索したテクセル値を平均することによって生成される。ピクセルに対するピクセル値は、第1および第2のミップマップ値の間で補間を行うことにより生成される。
(もっと読む)
画像処理方法、画像処理装置、および画像処理システム
【課題】3次元オブジェクトのレンダリング処理を柔軟性や互換性を保ちながら、並列処理により高速化することは難しかった。
【解決手段】オブジェクト記憶部52はオブジェクトの3次元データと、オブジェクトの占有する空間領域を包含するB−boxの配列データとを記憶する。分類部44はオブジェクト記憶部52からB−box配列を読み込み、オブジェクトの属性やLOD情報にもとづいてB−boxをグループに分類する。描画処理部46は、同一グループに属するB−boxを包含するブリックを算出し、ブリックごとに独立した描画処理を行って画像データを生成し、画像記憶部54に格納する。統合部48は、画像記憶部54に格納されたブリックごとの画像データを統合して最終的に表示すべき出力画像データを生成する。
(もっと読む)
レイトレーシングシステムアーキテクチャー及び方法
規範的なアーキテクチャーによりレイトレーシング機能を実施するシステムが提供される。一実施例において、加速構造の要素に対して光線が収集体へと収集され、それらは、あるケースでは、レイトレースされるシーンを構成するオブジェクトに関連される。検出された光線交差の指示も出力バッファに収集され、ある実施例では、出力バッファは、シーンオブジェクトに各々関連した複数の部分と、シェーディング中に実行されるべきコードの共通部分とを含む。バッファコンテンツは、ブロックの読み取りでアクセスできる。交差シェーディングリソースは、識別された光線に対して交差をシェーディングするのに使用されるデータをロードし、そしてそれら交差をシェーディングするのに使用するためにそのデータをローカル記憶することができる。 (もっと読む)
画像処理システム
【課題】転送元メモリからの素材のロード回数を減らして全体的な転送時間の短縮を図りつつ、転送処理間における調停を可能にする。
【解決手段】素材の転送過程で複数種の処理が併存し、素材の特性に応じて処理を使い分ける画像処理システムにおいて、ディスプレイリスト解析部2bは、ディスプレイリスト10を解析して、それぞれの素材の転送命令を順次出力する。転送処理部2c〜2eは、ディスプレイリスト解析部2bからの転送命令によって自己が指定された場合、転送命令に係る素材の取得要求を出力する。この取得要求を管理する調停部5は、取得要求に係る素材がキャッシュメモリ4に格納されているか否かを判定し、必要に応じて、取得要求に係る素材をNANDメモリ3からキャッシュメモリ4にロードする。
(もっと読む)
グラフィックス・システム内で中間ターゲットを提供するためのシステムおよび方法
【課題】グラフィックスAPIからのシリアル化プログラムが、単一プログラム用の手続き型シェーダの命令制限を越えるアルゴリズムをサポート可能とすること。
【解決手段】コンピュータグラフィックスに関連して中間ターゲット(複数)、すなわち、他の目的用のプログラム間でのデータの共用も可能にし、自動的にアクセス可能な中間メモリバッファ(複数)がビデオメモリ内に提供されて使用される。バッファのサイズすなわち中間ターゲットに格納されるデータ量は、グラフィックスデータに関して変化する解像度用に可変的に設定可能である。単一のプログラムは、このバッファ内に後で使用可能で、同じプログラムの拡張部および/または他のプログラムによって、所望される場合何度でも再使用される中間データを生成し、現在のグラフィックスチップの速度を維持しながら、シェーディングプログラムについてかなりのフレキシビリティと複雑さを可能にする。
(もっと読む)
混合精度命令実行を伴うプログラマブルストリーミングプロセッサ
本開示は、異なる実行ユニットを使用して、混合精度(例えば完全精度、半精度)命令を実行することが可能なプログラマブルストリーミングプロセッサに関する。様々な実行ユニットは、それぞれがグラフィックスデータを使用して指定の精度レベルで命令を実行することが可能である。例示的なプログラマブルシェーダプロセッサは、コントローラと、複数の実行ユニットとを含む。コントローラは、実行のための命令を受け取り、命令の実行に対するデータ精度の指示を受け取るために構成されている。コントローラは、また、実行されると、命令に関連付けられたグラフィックスデータを、示されたデータ精度に変換する個別の変換命令を受け取るために構成されている。実施可能な場合、コントローラは、示されたデータ精度に基づいて実行ユニットのうちの1つを選択する。コントローラは、その後、選択された実行ユニットに、命令に関連付けられたグラフィックスデータを用いて、示されたデータ精度で命令を実行させる。 (もっと読む)
レイトレース・レンダリングのための並列化された交差テストおよびシェーディングのアーキテクチャ
【課題】 レイトレース・レンダリングのための並列化された交差テストおよびシェーディングのアーキテクチャを提供する。
【解決手段】 実施例では、シーンのレイトレーシングは、リンク/キューを介して全体として通信する複数のシェーディング資源と連結された複数の交差テスト資源を使用する工程を含む。テストからシェーディングへのキューは、レイ識別子を含むそれぞれのレイ/プリミティブ交差指標を含む。シェーディングからテストへのキューは、テストされる新しいレイの識別子を含み、レイを定義するデータは交差テスト資源の間に分散させられたメモリに別個に格納される。レイ定義データは、レイ識別子に基づいて複数回に亘りテストのため選択可能である場合、レイが交差テストを終了するまで、分散メモリの中で維持することが可能である。アクセラレイション形状の構造が使用可能である。レイ識別子および形状データのパケットは、交差テスト資源の間を循環可能であり、各交差テスト資源はパケットの中で特定されたレイをテスト可能であり、そのレイのための定義データが交差テスト資源のメモリの中に存在する。アクセラレイション形状テスト結果は、交差した形状に基づいてレイのコレクションを可能にさせ、最近傍検出レイ/プリミティブ交差はシェーディングのためのレイ識別子をキューイングすることによって指示される。
(もっと読む)
41 - 60 / 105
[ Back to top ]