
Fターム[5B091AA04]の内容
Fターム[5B091AA04]の下位に属するFターム
Fターム[5B091AA04]に分類される特許
1 - 20 / 162
例文検索装置、処理方法およびプログラム
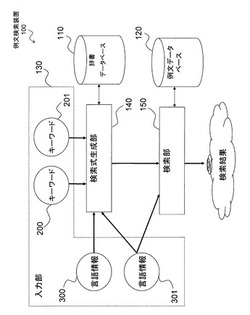
【課題】複数の異なる言語の入力キーワードに基づいて特定言語の例文を検索する例文検索装置、処理方法およびプログラムを提供する。
【解決手段】複数の例文を記憶する例文データベースと、所定言語と異なる特定言語の語句ごとに、その語句と、その語句の訳語である所定言語の語句と、を互いに対応付けて記憶する辞書データベースと、所定言語のキーワードと、特定言語のキーワードと、をそれぞれ受け付ける入力部と、辞書データベース内の所定言語の語句のうち、特定言語のキーワードに対応付けられた訳語を訳語キーワードとして検出する検索式生成部と、例文データベース120内の例文の中から、所定言語のキーワードと訳語キーワードとの少なくとも一方を含む例文を検索し、その検索結果を出力する検索部と、を含む。
(もっと読む)
ファイルフォーマット、サーバ、電子コミックのビューワ装置および電子コミック生成装置

【課題】電子コミックにおいて、オリジナルの言語のセリフ、およびオリジナルの言語のセリフから任意の言語に変換されたセリフの文字列を過不足なく吹き出し領域内に配置可能にするファイルフォーマットを提供する。
【解決手段】ユーザ端末は、スクロールビューまたはコマビューのいずれであっても、ファイルフォーマットの吹き出し領域の情報に基づき、各吹き出し内の台詞を示す第1のテキスト情報を表示でき、オリジナルの言語のセリフ、およびオリジナルの言語のセリフから任意の言語に変換されたセリフの文字列を吹き出し領域に過不足なく配置することができる。
(もっと読む)
翻訳装置、翻訳方法、及び翻訳プログラム
【課題】正確な翻訳文を得るととともに、表現可能な範囲の拡張性を確保した翻訳技術を提供する。
【解決手段】第1の言語で記述された第1の例文と、当該第1の例文を第2の言語で記述した第2の例文とを格納する例文格納手段を備えた翻訳装置において、複数の候補例文の中から利用者により選択された前記第1の例文と、当該第1の例文における所定の構成部に埋め込まれる文字列として利用者により入力された文字列とを取得する制御手段と、前記文字列を前記第2の言語の文字列に翻訳するとともに、前記第1の例文に対応する前記第2の例文を前記例文格納手段から読み出し、前記所定の構成部に対応する前記第2の例文における構成部に、前記第2の言語の文字列を埋め込むことにより翻訳文を生成し、当該翻訳文を出力する翻訳手段と、を備える。
(もっと読む)
機械翻訳装置及び機械翻訳プログラム
【課題】該当する専門分野の用語に統一を図った訳文を生成することである。
【解決手段】翻訳辞書部の翻訳辞書情報及び専門用語辞書部の対訳情報を用いて第一言語文書の形態素解析を行い形態素の属性情報及び訳語情報を解析情報として求め、訳語情報に基づき訳文を生成する。その際、専門用語辞書の見出し語が使われて構文解析に失敗したときはその見出しを棄却して訳文を得る。専門用語辞書の見出し語の棄却により訳文を得たときは、単語単位に分割した第一言語の見出し語の訳語候補のいずれかが単語単位に分割した見出し語の訳語に一致しているかどうかを判定し、一致しているものがあるときは、文書解析手段で得られた訳文中のその見出し語の訳語に相当する部分をその訳語候補に置き換える。
(もっと読む)
自動単語対応付け装置とその方法とプログラム
【課題】トピックを導入した同義語辞書モデルを構築させ、その同義語辞書モデルと従来の単語対応付けモデルとを同時に用いた自動単語対応付け装置を提供する。
【解決手段】この発明の自動単語対応付け装置は、訓練データ記憶部と、アライメント確率学習部と、自動対応付け部と、を具備する。訓練データ記憶部は、単語で区切られた原言語と目的言語の対訳文の組みで構成される対訳文コーパスと、上記目的言語の同義語の組の集合である同義語辞書とから成る。アライメント確率学習部は、トピック毎に、対訳文コーパスの対数尤度と同義語辞書の対数尤度との重み付き和を最大にするパラメータを学習する。自動対応付け部は、対象翻訳文とそのパラメータを入力として対象翻訳文の原言語と目的言語の単語間のアライメントを生成する。
(もっと読む)
情報処理装置
【課題】変換対象となっている語が日中変換辞書に登録されていない日本語の未知語である場合に、当該未知語の中国語への変換精度の向上を図る。
【解決手段】情報処理装置は、入力された日本語の文字情報のうち、日本語と中国語との対訳辞書に登録されていない未知語を検出する未知語検出手段と、上記未知語を日本語における漢字を含む他の言い換え語に言い換える言い換え手段と、上記言い換え語に含まれる日本語漢字を、日本語漢字と中国語漢字との対応漢字情報に基づいて中国語漢字に変換して、上記言い換え語を中国語に変換する中国語変換手段と、を備える。
(もっと読む)
翻訳装置
【課題】 翻訳前のテキストデータと翻訳後のテキストデータを表示する翻訳装置であって、視認性に優れた翻訳装置を提供する。
【解決手段】 翻訳前の文字列と翻訳後の文字列がどちらも第1の文字サイズで表示領域内に表示可能であれば、当該第1の文字サイズで表示領域内に表示し、翻訳前の文字列と翻訳後の文字列のどちらか一方でも第1の文字サイズで表示したときに表示領域内に全ての文字列を表示できないのであれば、翻訳前の文字列と翻訳後の文字列の両方を第1の文字サイズよりも小さい第2の文字サイズで表示領域内に表示する。
(もっと読む)
情報出力装置及び情報出力プログラム
【課題】中国語テキストの四声をユーザに分かりやすく表示する。
【解決手段】電子辞書1は、中国語の漢字文字列と当該漢字文字列に対応するピンイン文字列とが含まれる中国語テキストを記憶する中国語会話データベースを備えている。そして、記憶されている中国語テキストから漢字文字列とピンイン文字列とをそれぞれ抽出して、ピンイン文字列に含まれる四声データを漢字文字列の各漢字に対応付けるとともに、この四声データの発音の抑揚を視覚的に示す四声マークを、当該四声データと対応付けられた各漢字の近くに表示する。
(もっと読む)
例文表示制御装置及びプログラム
【課題】例文表示でユーザが一方の言語の例文中の任意の単語をマーキングした際に、他方の言語の例文の該当する単語を自動的にマーキングする。
【解決手段】ユーザが入力部13を通じて第1言語と第2言語の一方の言語の例文中の文字列を指定すると、CPU11は、その指定された文字列を識別表示(マーキング)する。その際、CPU11は、当該指定文字列から辞書検索のための単語を抽出し、この抽出した単語の対訳を辞書データベース23から検索することにより、第2言語の例文中の該当する文字列に対して同じ表示形態で識別表示を行う。
(もっと読む)
機械翻訳システム、機械翻訳方法及び機械翻訳プログラム
【課題】翻訳処理の際に、別の機械翻訳システム上の辞書の情報を利用することが可能であり、かつ、システム間のデータ転送量が少なくて済むようにする。
【解決手段】第1の翻訳システムは、翻訳に用いる辞書を記憶する第1の辞書記憶手段と、第1の辞書記憶手段が記憶する辞書を用いて、入力文を翻訳する第1の翻訳手段と、第1の辞書記憶手段が記憶する辞書を用いて、第1の翻訳手段が翻訳処理に用いた辞書エントリに関連づけられた辞書エントリを第1の辞書記憶手段が記憶する辞書から抽出し、抽出した辞書エントリを通信回線を介して第2の翻訳システムに送信する辞書エントリ抽出手段とを含み、第2の翻訳システムは、翻訳に用いる辞書を記憶する第2の辞書記憶手段と、第1の翻訳システムから通信回線を介して送信された辞書エントリを受信し、受信した辞書エントリを第2の辞書記憶手段が記憶する辞書に登録する辞書登録手段とを含む。
(もっと読む)
情報処理装置、表示制御方法、およびプログラム
【課題】ユーザが選択した原文の範囲と対応関係にある翻訳文の範囲を、ユーザが確認可能な翻訳装置を提供する。
【解決手段】対訳テンプレートを用いて第1言語による第1文を第2言語による第2文に翻訳する翻訳装置1であって、第1文と第2文とを出力部11に表示させる表示制御部25と、第1文に含まれる1つまたは複数の語句が選択されたことを検知する検知部32と、少なくとも対訳テンプレートに基づいて、第2文に含まれる、選択された語句に対応する複数の対応語句を特定する特定部33とを備え、表示制御部25は、対応語句が特定されたことに基づき、当該対応語句の表示態様を変更する。
(もっと読む)
データ検索および言語翻訳のための方法および手段
本発明は、データ検索および翻訳に関する。特に、本発明は、インターネットまたはデータベースから文書を検索することに関する。さら、本発明は、文書、ウェブページ、画像または音声中の言葉をある言語から別の言語に翻訳することにも関する。本発明に係る少なくとも1つのコンピュータを含むコンピュータで実施される方法は、少なくとも1つの検索語を含む検索クエリを受信する工程と、少なくとも1つの検索語に対して少なくとも1つの同義語を引き出す工程と、前記受信した検索クエリを少なくとも1つの同義語で拡張する工程と、前記拡張した検索クエリを用いて少なくとも1つの文書を検索する工程と、前記拡張したクエリによって得られた検索結果を取り出す工程と、少なくとも1つの検索語が出現する文脈に基づいて、前記同義語拡張した検索結果をランク付けする工程とを特徴とする。本発明の最良の形態は、より優れた検索結果を提供するインターネット検索エンジンであるとみなされる。 (もっと読む)
翻訳装置及び翻訳プログラム
【課題】 追加説明を含む入力文について、正しく翻訳できるようにすること。
【解決手段】 翻訳装置は、入力文から追加説明部分を抽出する抽出手段と、入力文から前記抽出手段で追加説明部分が抽出され前記追加説明部分が除かれた文に、当該追加説明部分の位置を示す管理情報を付加する付加手段と、前記追加説明部分が除かれた文を翻訳する第1の翻訳手段と、前記抽出手段で抽出された追加説明部分を翻訳する第2の翻訳手段と、前記管理情報に基づいて、前記第1及び第2の翻訳手段の翻訳結果を合成する合成手段と、を具備することを特徴とする。
(もっと読む)
翻訳支援装置及び翻訳支援プログラム
【課題】 翻訳対象となる文の構造の正確さを損なわないように翻訳支援する翻訳支援装置及び翻訳支援プログラムを提供することを目的とする。
【解決手段】 入力画面上の表示欄に表示された翻訳対象を、分解に関する第1の指示に基づいて、文の骨格をなす主構造と文の構成要素をなす副構造とに分解する分解手段110と、主構造及び副構造を、翻訳に関する第2の指示に基づいて、それぞれ翻訳する翻訳手段120と、翻訳手段によって翻訳された主構造及び副構造を、合成に関する第3の指示に基づいて、合成する合成手段150と、合成手段により合成された主構造及び副構造を表示装置に表示させる表示制御手段160と、を有する。
(もっと読む)
対訳登録システム及びプログラム
【課題】ユーザが第二言語の知識を有していなくても、第一言語である日本語の知識のみで、漢字文字列からなる未知語の対訳を得ることである。
【解決手段】漢字解析部28は入力装置18から入力された未知語を1文字または2文字単位に区切り単漢字辞書部33を辞書引きして区切り文字ごとの読みと語義とを求め、語義選択画面表示部29は区切り文字ごとの語義を選択するための語義選択画面を表示し、言い換え候補生成部30は、語義選択画面からユーザから特定の語義が選択されたときは漢字熟語パターン情報記憶部34の言い換え表現式に当てはまるパターンの言い換え候補を生成し、言い換え候補選択画面表示部31は言い換え候補選択画面を表示し、翻訳部32は言い換え候補からユーザにより選択された言い換え表現を翻訳して未知語とその翻訳結果の訳語とを対にして翻訳辞書部35に辞書登録する。
(もっと読む)
翻訳装置及び翻訳プログラム
【課題】複雑な入力文について、少ない計算量で精度良く翻訳できるようにする。
【解決手段】入力文と候補例文の類似度及びカバー率の関係に基づき候補例文を検索し、前記入力文の示す単語で区切られた文字列を検索した候補例文に対応させ、単語及び節を含む文字列に変換する。変換文字列を、前記候補例文との相違値を算出し、算出した相違値を定める前記変換した入力文と候補の例文との写像としての対応関係を抽出し、抽出した対応関係を選択する。選択された対応関係を、当該入力文に対応する候補の例文に対応して修正し、修正した入力文に基づき、前記相違値の算出と対応関係の抽出を修正し、該修正結果に基づき、前記入力文を翻訳する。
(もっと読む)
自動翻訳対応電話システムおよび自動翻訳対応電話機
【課題】話者が発する音声に関する情報を登録する際に、音声の認識の状態を話者が確認することが可能であるとともに、第1言語を用いる話者と第2言語を用いる通話相手との通話時に、精度の高い翻訳を行うことが可能な自動翻訳対応電話システムを提供する。
【解決手段】この自動翻訳対応電話システム1は、予め登録された話者が発する音声に関する情報に基づいて、日本語の音声を、日本語の文字として認識するための音声認識部19と、日本語に含まれる方言に対応する方言辞書21bを有する電子辞書部21を含み、日本語の文字を英語の文字に変換するための翻訳エンジン部20と、話者が発する音声に関する情報を登録する際に、話者が確認可能なように日本語の文字を通知するようにスピーカ12bを制御する制御部13とを備え、制御部13は、日本語の文字を英語の文字に変換する際に、方言辞書21bを選択して参照するように構成されている。
(もっと読む)
自動翻訳対応電話機および自動翻訳対応電話システム
【課題】話者が発する音声に含まれる話者の意図する単語が、話者の意図する単語と異なる単語として誤って認識されるのを抑制するとともに、話者が発する音声に関する情報を登録する際に、音声の認識の状態を話者が確認することが可能な自動翻訳対応電話機を提供する。
【解決手段】この発信元電話機10(自動翻訳対応電話機)は、日本語によって話者が発する音声が入力される集音器12aと、話者が発する音声に関する情報を予め登録して記憶するためのメモリ18と、話者が発する音声に関する情報に基づいて、話者が発する音声を日本語に対応する文字として認識するための音声認識部19と、文字を音声として出力するスピーカ12bと、話者が発する音声に関する情報を登録する際に、話者が発する音声を日本語に対応する文字として認識した結果に基づいて、文字を音声として出力するようにスピーカ12bを制御する制御部13とを備える。
(もっと読む)
機械翻訳装置、方法及びプログラム
【課題】原文データ中の特定の用語に対してその語の略語が併記されている場合、用語の複数ある翻訳候補から生成した略語と、文中に記載された略語とが一致する翻訳候補を選択して翻訳を行うことである。
【解決手段】用語・略語抽出部26は、原文解析・翻訳部25が辞書部31を参照して入力部22で受け付けた原文データを解析した解析結果を参照して、原文から略語とそれに対応する展開表記の用語とを抽出し、生成略語選択部28は、略語生成部27によって生成された生成略語と用語・略語抽出部26が原文データから抽出した抽出略語とを比較して一致度が100%の生成略語を選択し、原文解析・翻訳部25は、略語生成部27が生成の元とした第二言語の翻訳候補を翻訳結果に使用する。
(もっと読む)
変換モデル生成装置、音声認識結果変換システム、方法およびプログラム
【課題】音声認識結果をどのような目的で変換するかによって定まる複数の用途における各用途に応じた変換モデルの生成を容易に行うことを可能にする。
【解決手段】ある音声データに対して音声認識処理の結果を示す学習用音声認識結果データと、音声データを所定の目的をもってテキストに変換した結果を示す学習用整形済みテキストとを用いて、学習用音声認識結果データによって示される音声認識結果テキストと学習用整形済みテキストとの間の異なり部分を抽出し、抽出された異なり部分の出現傾向に基づいて、予め定められている個別の用途に応じた変換モデルを生成するための学習データを選別する用途別学習データ選別手段501と、用途別学習データ選別手段によって選別された学習データを用いて、個別の用途に応じた変換モデルを生成する変換モデル生成手段502とを備える。
(もっと読む)
1 - 20 / 162
[ Back to top ]