
Fターム[5B091BA02]の内容
Fターム[5B091BA02]に分類される特許
1 - 20 / 135
翻訳装置、翻訳方法及びコンピュータプログラム
情報表示装置及びプログラム
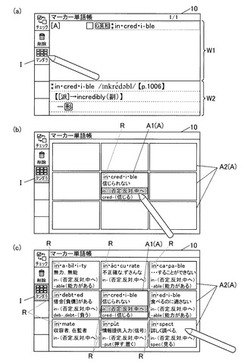
【課題】語源の共通する同語源単語を効率良く学習することを可能とする。
【解決手段】電子辞書1は表示部40と、語源付き辞書データベース821と、語源付き辞書データベース821に記憶された何れかの単語を指定する入力部30と、CPU20とを備える。CPU20は、指定単語に含まれる各単語構成部分と同じ語源の単語構成部分を含む単語を、語源付き辞書データベース821により記憶された単語の中から同語源単語として抽出し、指定単語及び同語源単語を表示部40に一覧表示させるとともに、当該指定単語と当該同語源単語の双方に共通して含まれる単語構成部分を識別表示させる。
(もっと読む)
意味ラベル付与モデル学習装置、意味ラベル付与装置、意味ラベル付与モデル学習方法、及びプログラム

【課題】会話の流れによって疑問表現になったり、断定表現になったりする述部の機能表現に対しても、適切な意味ラベルを付与する。
【解決手段】学習用発話対作成部22で、形態素解析結果に対して、機能表現及び応対表現の正解ラベルが付与された正解コーパスに基づいて、学習用発話対を作成する。パラメータテーブルに、素性として、発話対の前の発話の終わりに表れる機能表現の意味ラベルと、それに対する後の発話の初めに表れる応対表現の意味ラベルとの並びの素性を用い、複数種類の素性各々について、重みの初期値を設定する。パラメータテーブル作成部24で、発話対の形態素情報と機能表現辞書30とを用いて、各形態素について候補となる意味ラベルを全て含んだラティスを構築し、ラティス構造からパラメータテーブルの素性毎の重みに基づいて最尤パスとして探索する。最尤パスが正解の意味ラベル列となるようにパラメータテーブルの重みを学習する。
(もっと読む)
自然言語処理装置、自然言語処理方法および自然言語処理プログラム
【課題】解析対象となる文書の言語およびドメインを考慮して、その文書に適した解析器を作成する自然言語処理装置を提供する。
【解決手段】自然言語処理装置100は、対訳記憶手段と対訳検索手段と単語抽出手段と正解作成手段と解析器生成手段とを備える。対訳記憶手段は、未知言語の文書と一又は複数の既知言語の文書とからなる複数の対訳文書、およびそのドメインを記憶する。対訳検索手段は、ドメインを指定して、対訳記憶手段から対訳文書を検索する。単語抽出手段は、対訳検索手段で検索された対訳文書から、未知言語の単語と既知言語の単語とを対応付けた単語ペアを抽出する。正解作成手段は、単語ペア、および検索された対訳文書における既知言語の文書の解析結果を用いて、検索された対訳文書における未知言語の文書の解析結果を推定する。解析器生成手段は、未知言語の文書の解析結果を用いて、未知言語の解析器を生成する。
(もっと読む)
ルビ付きデータ生成装置、ルビ付きデータ生成方法及びプログラム
【課題】原稿等をスキャナで読み取り生成した文字テキストデータを翻訳しルビを生成し、該文字テキストデータの列幅と対応するルビの列幅に基づき圧縮率を算出し、該文字テキストデータの表記方向に圧縮した該ルビを該文字テキストデータの近傍に付して表示し、圧縮率が所定の圧縮率を超える場合には、該ルビを縮小し複数段で表示するルビ付きデータ生成装置、ルビ付きデータ生成方法及びプログラムを提供する。
【解決手段】ルビ付きデータ生成装置1は、文字の印刷されている原稿をスキャナ11で読み取り、文字認識部12で文字認識を行いテキストデータ化し、ルビ判定部13により認識した各文字テキストデータを翻訳して、対象の文字テキストデータの列幅と、生成したルビの列幅とに基づいてルビを圧縮するための圧縮率を算出し、対象の文字テキストデータを表記する方向に各ルビを圧縮し、該文字テキストデータの近傍に付与すように表示部15を制御する。
(もっと読む)
翻訳支援装置、翻訳支援方法及びプログラム
【課題】
英語から日本語に人手で翻訳を行う作業者が行う必要のある入力操作を可能な限り少なくすることによって、作業の効率化及び省力化を図ることである。
【解決手段】第1言語文書解析手段は、翻訳辞書部を用いて第1言語文書を解析し形態素解析情報及び係り受け解析情報を求める。第2言語文書解析手段は、翻訳辞書部を用いて第1言語文書のうち翻訳者により第2言語に翻訳された文を解析し形態素解析情報及び係り受け解析情報を求める。訳語リスト作成手段は、第1言語文書の中に含まれる単語のうち内容語を抽出し、翻訳者により翻訳された文中から第1言語の内容語に対応する第2言語の内容語を抽出し、第1言語と第2言語との内容語を対応付けた訳語リストを作成する。訳語予測手段は、翻訳者が翻訳しようとする第1言語の文に含まれる内容語が訳語リストにあるときはそれに対応する第2言語の内容語を導き出し表示装置に表示する。
(もっと読む)
画像処理装置およびプログラム
【課題】原稿の読者が理解可能な特徴文字列を生成可能な画像処理装置を提供する。
【解決手段】読者言語登録部320は読者言語を登録し、原稿言語登録部322は原稿言語を登録する。切替部326は、言語組合せ情報に基づいて、特徴文字列生成部40において特徴文字列を生成させるために使用される特徴文字列生成手段を切り替える。特徴文字列生成部40は、切替部326によって特徴文字列の生成に使用される特徴文字列生成手段が切り替えられ、切り替わった特徴文字列生成手段を使用して、特徴文字列を生成する。
(もっと読む)
用語の対応を見出す方法、プログラム及びシステム
【課題】 ランダムウォークの技法を用いて、多数の用語を対象としても妥当な計算量で異言語の単語集合を列挙することが可能な技法を提供すること。
【解決手段】 第1の言語(例えば日本語)の専門用語集合と、第1の言語の一般用語集合と、第2の言語(例えば英語)の専門用語集合と、第2の言語の一般用語集合とを生成する。次に、第1の言語と第2の言語それぞれにおいて、同一言語の専門用語集合と一般用語集合の間に、コーパスの情報に基づきリンクで結び、2部グラフを生成する。次に、異なる言語の一般用語の対訳辞書(例えば、英和辞書)で一般用語間のリンクを生成し、異なる言語の一般用語間で2部グラフを連結する。次に、同一言語内、及び異なる言語間の2部グラフのリンクの重み付けされた情報に基づき、関連度行列Mを生成する。次に、Q=(1-c)(I-cM)-1という、類似度行列Qを計算する。
(もっと読む)
ロシア語検索装置およびプログラム
【課題】電子辞書等によるロシア語検索装置において、アルファベット文字の入力からロシア語辞書の見出し語を容易且つ迅速に検索することを可能にする。
【解決手段】[英字キリル文字読み変換入力]モードを設定した検索語入力画面G1の英字検索語入力エリアAeにおいて、ロシア語の読みに応じた英字の文字列[lemon]を入力すると、当該入力された英字の文字列は英字キリル文字類似音声変換テーブルに従いキリル文字の文字列[лемон(第1候補)][лэмон(第2候補)]に変換される。そして、当該変換されたキリル文字の文字列と一致するロシア語の見出し語が[露和辞書]に存在するか否かスペルチェックに掛けられ、一致する見出し語が存在しない場合には、最も近似する見出し語と一致する検索文字列[лимон]に訂正された後、該当する見出し語の説明情報[лимон レモン」が読み出されて説明情報表示画面G2として表示される。
(もっと読む)
電子機器
【課題】入力した文章を有効に活用することができる電子機器を提供することにある。
【解決手段】文章を入力可能な入力部と、文章中の単語を所定の規則に基づいて項目ごとに分類する解析部と、単語が分類された項目の種類を当該単語と共に記憶する記憶部と、文章を翻訳する翻訳アプリケーションを実行する制御部と、を備え、制御部は、入力部により入力された文章を翻訳アプリケーションにより翻訳する際に、文章中の単語ごとに翻訳し、翻訳される言語における項目の配列規則に従って翻訳された単語を並び変えることで上記課題を解決する。
(もっと読む)
電子コミックのビューワ装置、電子コミックの閲覧システム、ビューワプログラム、該ビューワプログラムが記録された記録媒体ならびに電子コミックの表示方法
【課題】電子コミックにおいて、オリジナルの言語から任意の言語に変換されたセリフの文字列を過不足なく配置する吹き出しを描画する。
【解決手段】コンテンツ表示制御部25は、表示部24の画面サイズ情報(DB21に記憶されている)に従ってその文字サイズを維持したままテキスト情報が吹き出しに収まるか判断する。コンテンツ表示制御部25は、収まらないと判断した場合は、さらに、レイアウト変更可であるか否かを付帯情報に基づいて判断し、レイアウト変更可であれば、表示指定のあった画像領域に対応する吹き出しの話者を起点に、横置き用の吹き出しを描画する。
(もっと読む)
単語帳作成装置及び単語帳作成プログラム
【課題】学習効率を低下させずに容易に単語帳データを作成する。
【解決手段】電子辞書1は、複数の見出し語を有する辞書データベース820を複数記憶するフラッシュROM80と、科目毎に、辞書データベース820の何れかを検索対象辞書データベース820Tとして記憶する科目別検索条件テーブル87と、外部からテキストデータ851を取得するとともに、当該テキストデータ851の科目を検知するCPU20とを備える。CPU20は、テキストデータ851に含まれる各単語を検出するとともに、テキストデータ851の科目に対応する検索対象辞書データベース820Tを検出し、検出された単語から、当該検索対象辞書データベース820Tに見出し語として存在する単語を抽出する。単語帳テーブル86は、CPU20により抽出された単語と、テキストデータ851の科目とを対応づけて記憶する。
(もっと読む)
処理装置、処理方法、及び、プログラム
【課題】簡易な処理での抽出が可能となる処理装置等を提供する。
【解決手段】チャンク及び該チャンクを構成する一または複数の単語の種類を受け付ける。予め記憶部15に記憶したチャンク及びチャンクの種類と、受け付けたチャンク及び該チャンクを構成する一または複数の単語の種類とに基づき、チャンクに対する処理を選択する。チャンクを構成する一または複数の単語の属性を選択した処理に対応付けて記憶する。チャンク及びチャンクを構成する一または複数の単語に属性を付与する。単語の属性及び該単語の属性に対応する処理を記憶した記憶部15を参照し、単語に付与された属性に対応する処理を抽出し、抽出した処理を単語に適用する。
(もっと読む)
バイリンガルコーパスを同時セグメント化するための装置及びそのコンピュータプログラム
【課題】過学習の問題なくトークンのソース及びターゲットシーケンスを同時セグメント化する装置を提供する。
【解決手段】装置は、第1及び第2の文字シーケンスを記憶する記憶部と、第1及び第2のシーケンスのブロック対を同時セグメント化する同時セグメント装置と、各フレーズ対の発生を計数するカウンタ74と、ブロック対をランダムにサンプルするサンプル抽出器88と、サンプルされたブロック対中のフレーズ対の数から1を引く減算器100と、サンプルされたブロック対に対する可能な全同時セグメント化の確率を計算する計算器102と、計算された確率に従って、可能な同時セグメント化の1つをサンプルするサンプル抽出器106と、フレーズ対の計数を更新する更新部108と、サンプル抽出器88から更新部108までを、終了条件が満たされるまで繰返し動作させる繰返し制御部90とを含む。
(もっと読む)
文章学習用ブロックおよび言語学習プログラムを格納するコンピュータで読み取り可能な記録媒体
【課題】文章を構成する各単語をブロックでイメージ化して結合する方式によって特定言語の構造を覚えさせる言語学習プログラムを格納するコンピュータで読み取り可能な記録媒体と文章学習用ブロックが提供される。
【解決手段】一実施形態の言語学習プログラムは、複数の単語(vocabulary)ブロックを格納する単語ブロックデータベースおよび前記複数の単語ブロックのうちから主語(subject)ブロック、動詞(verb)ブロック、および目的語(objective)ブロックが選択される段階と、前記動詞ブロックと前記主語ブロックが結合可能なペアであれば2つのブロックを並べて結合する段階と、前記結合したブロックの動詞ブロックの部分と前記目的語ブロックが結合可能なペアであれば2つのブロックを並べて結合して全体的に1つの文章を完成する段階とを実行するユーザインターフェースモジュールを含む。
(もっと読む)
孔版印刷システム
【課題】作像エンジンがモノクロベースでカラースキャナ搭載という構成・仕様であっても、カラースキャナのポテンシャルを十分活用することができる孔版印刷システムを提供する。
【解決手段】原稿と、複数の色により原稿上の特定のエリアが指定されたカラーコマンドシートと、をカラー画像として読み取る読取手段と、読取手段により読み取られた原稿のうち、カラーコマンドシートに指定された特定のエリア内の単語を解析する解析手段と、解析手段により解析された単語のうち、第1の色で指定された特定のエリア内の単語を翻訳する翻訳手段と、を有する。
(もっと読む)
上位概念出力プログラム及び上位概念出力装置
【課題】対象とする語句が見出し語となっている概念が概念辞書中に存在しない場合において、対象とする語句の上位概念を出力する上位概念出力プログラム及び上位概念出力装置を提供する。
【解決手段】上位概念出力装置1は、語句を受け付ける表現受付手段100と、表現受付手段100により受け付けられた語句と関連する語句との関連度を計算し、当該関連度に基づいて関連する語句から関連語を検索する関連語検索手段101と、概念辞書111に基づいて、関連語を見出し語として持つ概念を抽出し、抽出された概念の上位概念を概念辞書111に基づいて抽出し、関連語と上位概念とこれらの概念の繋がりとから構成される部分木20を作成する部分木作成手段102と、概念の繋がりの形態に対応付けられた係数基づいて、関連度から上位概念のスコアを計算する関連度計算手段103と、上位スコアを有する上位概念を出力する概念出力手段104とを有する。
(もっと読む)
語句分類処理装置、語句検索装置、文字入力支援装置、語句分類処理方法、語句抽出方法、文字入力支援方法、構文解析誤り修正装置、構文解析誤り修正方法、およびコンピュータ読み取り可能な記憶媒体
【課題】テキストデータの中から語句を自動的に抽出し分類する装置、方法、およびプログラムに関し、言語学的にまとまった単位の語句の自動抽出および分類を可能にする。
【解決手段】テキストデータ中の連文節あるいは文などの一次元文字列に含まれる語句を分類する装置であって、前記一次元文字列を構文解析して得た構文解析木の各々の部分木について、前記部分木中のフレーズの一次元列を生成し(S106)、フレーズと該フレーズの属性とを関連付けたフレーズ分類結果のデータベースを参照して、前記生成したフレーズの一次元列中の各フレーズの属性を抽出し(S104)、前記生成したフレーズの一次元列と前記抽出したフレーズの属性とから、前記フレーズの一次元列に対応する属性の一次元列を求め、該属性の一次元列とフレーズの一次元列とを関連付けた語句分類結果を生成してデータベースに格納する(S107,S108)。
(もっと読む)
単語境界判定装置
【課題】より精度良く単語の境界を判定する。
【解決手段】単語境界判定装置1は、2文字以上から構成される一の文字列から、一の文字列の一部を構成する1文字以上の文字列(第1文字列)、および、一の文字列の一部を構成する1文字以上の文字列であって一の文字列において第1文字列に続く文字列(第2文字列)を抽出する抽出部22と、抽出された第1文字列、第2文字列の組合せ毎に、ラベル付学習データ内における、第1文字列に続く第2文字列の出現回数および非出現回数、並びに、第1文字列以外の文字列に続く第2文字列の出現回数および非出現回数を、第1文字列と第2文字列の間の単語境界の有無別に集計する集計部23と、該集計値を用いてモデル検定を行った上でモデル選択を行うことで一の文字列の特徴量を算出する特徴量算出部31と、該特徴量を使用した識別器14aを用いて未知文字列の単語境界を判定する単語境界判定部14とを備える。
(もっと読む)
異国語の学習補助システム
【課題】英語の単語を用いた文章に容易にアクセスできることで、英語の複数の和訳を理解しやすくする。
【解決手段】
英語の複数の単語群から選ばれた一つの単語の発音を発する英語発声部と、その英単語に対応した日本語の単語の発音を発する日本語の発声部とを備えると共に、その英単語が使われる単語を発声した後に、その複数の英単語の中から対応した英単語を用いた文章を発声するように構成した。また、得意な場合はその英単語に対応した和訳を早送り再生またはスキップするようにした。
(もっと読む)
1 - 20 / 135
[ Back to top ]