
Fターム[5B091CC01]の内容
Fターム[5B091CC01]の下位に属するFターム
単語辞書 (59)
文法、ルール辞書 (38)
概念辞書、知識ベース (192)
Fターム[5B091CC01]に分類される特許
21 - 40 / 125
意味属性推定装置、方法及びプログラム
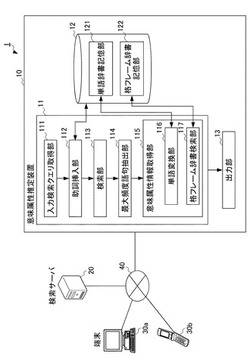
【課題】単語の羅列による検索クエリであっても、その単語の意味を推定することができる意味属性推定装置、方法及びプログラムを提供すること。
【解決手段】検索クエリ取得手段(111)が端末から検索クエリを取得すると、助詞挿入手段(112)が検索クエリに助詞を挿入した複数の仮文を作成する。そして、作成された複数の仮文それぞれについて検索手段(113)が検索すると、最大頻度語句抽出手段(114)は、その検索結果から最も一致した数の多い仮文を抽出する。一致した数の多い仮文は、使用される頻度が高いといえるので、意味属性情報取得手段(115)は、その仮文に含まれる単語の意味属性情報を取得する。これにより、意味属性推定装置(10)は、検索クエリに使用された単語の意味属性情報を出力することができる。
(もっと読む)
異表記取得装置、異表記取得方法、およびプログラム

【課題】従来、十分な異表記抽出の精度が得られなかった。
【解決手段】用語対の異なる文字である編集箇所の字種に関する素性である字種関連素性、用語辞書を用いて取得された素性である辞書関連素性、用語対を構成する2つの用語の類似度を示す素性である類似度素性のうちの一以上の素性を含む複数の素性と、用語対が異表記の用語対であるかを示す情報である正負情報とを対応付けた学習データを2以上格納し、編集距離が1以上の用語対ごとに、字種関連素性、辞書関連素性、類似度素性のうちの一以上を含む複数の素性を取得する素性取得部と、用語対に対して、2以上の学習データと取得された複数の素性とを用いて、教師あり機械学習法により、各用語対が異表記の用語対であるか否かを判断する機械学習部と、判断結果を出力する出力部とを具備する異表記取得装置により、精度の高い異表記の用語対抽出ができる。
(もっと読む)
単語の関連キーワードを決定する装置ならびにその動作制御方法およびその動作制御プログラム
【課題】ウェブ・ページに適したキーワードを決定する。
【解決手段】関連するキーワードを決定したい単語を入力する。入力された単語に関連するウェブ・ページが見つけられる。見つけられたウェブ・ページのメタ・タグに記述されているキーワード(プログラム言語,オブジェクト指向,教育,セミナー)が抽出される。入力された単語の専門辞書が登録されている辞書サーバに抽出されたキーワードが送信される。その辞書サーバに,送信されたキーワードが登録されていれば,そのキーワードは入力された単語に関連するキーワードと決定される。
(もっと読む)
単語出現確率算出装置および方法、語義推定装置および方法、プログラム、並びに記録媒体
【課題】膨大な量の学習コーパスを必要とすることなく、精度の高い単語出現確率を算出する。
【解決手段】直接出現確率算出部15Bにより、語義別見出語と語義文の組み合わせごとに、当該語義文内に当該語義別見出語が出現する直接出現確率14Cを算出し、間接共起確率算出部15Cにより、任意の語義別見出語が複数の語義文においてそれぞれ異なる語義別見出語と共起するという連接共起関係を経ることにより、任意の2つの語義別見出語が1つ以上の語義別見出語を介して間接的に共起する間接共起確率14Dを語義別見出語対ごとに算出し、単語出現確率算出部15Dにより、間接共起確率14Dから生成した間接共起確率行列Cと、直接出現確率14Cから生成した直接出現確率行列Aとの行列積CAを算出し、当該行列積CAの各行列要素を単語出現確率14Eとして出力する。
(もっと読む)
漢文例文検索装置およびプログラム
【課題】漢文例文検索装置において、漢文の例文を漢文の訓読の規則を考慮して適切に検索すること。
【解決手段】漢文検索入力画面Gの熟語検索文字列入力エリアE1に検索文字列(熟語)が入力された場合には、漢文例文データベースから順次読み出される例文データを対象に、前記検索文字列(熟語)と完全一致し且つその文字列間に返り点が存在しない文字列(熟語)を含んでいる例文データが検索されて表示される。また、読み順検索文字列入力エリアE2に検索文字列(読み順)が入力された場合には、漢文例文データベース24cから順次読み出される例文データを対象に、漢文の訓読の規則に従った漢字1文字が順次取得され、前記検索文字列(読み順)と完全一致する例文データが検索されて表示される。
(もっと読む)
辞書評価支援装置およびプログラム
【課題】業務文書チェック辞書のような辞書の評価作業を支援することを可能とする。
【解決手段】正規表現解析部32は、パターンマッチ辞書24に格納されている第1のパターンに含まれる第1の自立語を抽出する。形態素解析辞書検索部33は、第1の自立語と同音かつ同品詞である第2の自立語を形態素解析辞書23から検索する。辞書パターン作成部34は、第2の自立語を含む表現を表す第2のパターンを作成する。パターンマッチ部35は、第1のパターンによって表される表現を含む第1の例文のパターンマッチ結果および第2のパターンによって表される表現を含む第2の例文のパターンマッチ結果を作成する。例文追加部37は、第1の例文の数が予め定められた数以上でない場合、当該第1のパターンによって表される表現を含む第3の例文を例文コーパス22に追加する。結果出力部38は、第1乃至第3の例文のパターンマッチ結果を出力する。
(もっと読む)
応答生成装置及びプログラム
【課題】不適切な応答文の生成を防止して、自然な対話を行う。
【解決手段】言語解析部20でのユーザ発話に対する形態素解析の解析結果に基づいて、事態判別部22でユーザ発話に事態が含まれているか否かを判別し、事態が含まれている場合に、事態(単語)抽出部24がユーザ発話から事態を表す単語を抽出する。感情質問応答生成部26は、抽出された単語が感情を尋ねることが適切な単語として感情質問可能判断DB28に登録されている場合に感情を尋ねる質問を応答文候補として生成する。感情質問可能判断DB28には、シソーラス上の第4階層に感情に関する分類名が付されていない単語が登録されている。
(もっと読む)
情報処理装置及びプログラム
【課題】意味役割が厳密に定められず、曖昧な意味役割を持った格要素を含む文についての解析にも適用可能な構文意味辞書情報を提供する。
【解決手段】述語を含んだ標本文を取得し、当該取得した標本文において当該述語に係っている格要素の表層格と、自然言語文における表層格と意味役割との間の対応関係に関する規則と、に基づいて、当該述語に係る格要素の表層格と意味役割との対応関係に関する評価値を算出することにより、当該述語の構文意味辞書情報を生成する情報処理装置である。
(もっと読む)
地域特性辞書生成方法及び装置
【課題】地域毎に特徴語を抽出して、特徴語に関する地域特性辞書を生成する方法及び装置を提供すること。
【解決手段】地域特性辞書生成サーバ1は、ブログサーバ2に格納されているブログのうち、地域ブログの情報を収集するブログ情報収集部11と、収集された地域ブログの情報より用語を抽出して、用語の出現数の合計値を地域毎に計数する用語出現数計数部12と、地域ブログの数量及び用語が含まれている地域ブログの数量を計数するブログ数計数部13と、地域における用語の出現数の合計値、地域ブログの数量、及び用語が含まれている地域ブログの数量に基づいて所定の演算を行い、地域における用語の出現頻度の偏差を算出する用語出現偏差算出部14と、算出した用語の出現頻度の偏差が予め定めた閾値よりも大きい場合に、用語の出現頻度の偏差を算出した地域の地域特性辞書である辞書DB22に、当該用語を登録する辞書登録部15とを備える。
(もっと読む)
例文表示装置、例文表示方法および例文表示プログラム
【課題】 膨大な例文データの中から目的とする例文を絞り込みやすい電子辞書を提供すること。
【解決手段】 文字入力を受け付ける入力手段と、例文のデータを記憶した例文データ記憶手段と、前記入力手段から入力された文字列で前記例文データ記憶手段に記憶された例文を検索する例文検索手段と、前記例文検索手段の検索結果を指定された条件で並び替える例文表示制御手段と、前記例文表示制御手段の制御結果を表示する表示手段と、を有することを特徴とする。
(もっと読む)
翻字のための機械学習
翻字ペアを自動識別するためのコンピュータプログラム製品を含む方法、システムおよび装置が開示されている。1実施例では、方法が提供される。方法は、複数のリソースを受信するステップであって、複数のリソースは複数のアンカーテキストを含むステップと、複数のアンカーテキストから1又は複数の潜在的な翻字を決定するステップと、1又は複数の潜在的な翻字から1又は複数の潜在的な翻字ペアを識別するステップとを含み、各潜在的な翻字ペアは、第1筆記システムの第1アンカーテキストおよび第2筆記システム第2アンカーテキストを含み、第2アンカーテキストおよび第1アンカーテキストは、同じリソース又はロケーションを識別する。  (もっと読む)
(もっと読む)
辞書機能を備えた電子装置およびプログラム
【課題】検索対象とする言語に十分な知識がない場合でも、適切な例文の絞り込み検索を行うことが可能になる辞書機能を備えた電子装置を提供する。
【解決手段】検索キーワード(単語)「example」を入力すると、当該入力されたキーワード「example」を構成単語として含む全ての英語例文が抽出された後、この抽出された英語例文の構成単語を対象に、前記キーワード「example」以外の各構成単語における同じ単語の個数がカウントされ、このカウント個数の多い構成単語から順にその個数を対応付けたコロケーション候補の一覧画面Lcが表示される。そして、この一覧画面Lcから任意のコロケーション候補(構成単語)を選択すると、前記キーワード「example」を構成単語として含む抽出英語例文の中から、選択されたコロケーション候補(構成単語)をさらに含む英語例文が絞り込み検索されて一覧表示される。
(もっと読む)
電子辞書、電子辞書の検索方法及び電子辞書の検索プログラム
【課題】 膨大な例文データの中から目的とする例文を絞り込みやすい電子辞書を提供すること。
【解決手段】 複数の言語の文字列を入力するための入力手段と、入力手段から入力する文字列の言語を切り替える入力言語切替手段と、少なくとも1つの単語からなり、複数の言語の例文が対になった例文検索用データを記憶する記憶手段と、入力手段から入力された文字列により例文検索用データを検索する例文検索手段と、例文検索手段により検索された例文検索結果を検索候補として表示する表示手段と、を有し、例文検索手段は、入力手段から入力された文字列を言語毎に分類し、記憶手段に記憶された対応する言語の例文検索用データを検索することを特徴とする。
(もっと読む)
電子機器、表示制御方法、およびプログラム
【課題】マーカ表示の対象として選択された範囲のうちマーカ表示をする範囲や文字消去表示をする範囲をマーカの色に基づいて指定可能とする。
【解決手段】少なくとも見出し語の本文における選択された各範囲について、それぞれに指定された色を用いてマーカ表示をするか、あるいは当該指定された色を用いて文字消去表示をするかを同一の色が指定された範囲毎に一括制御制御する表示制御部21と、第2入力部12を介して色の指定を受け付ける第1受付部24とを備え、色の指定を受け付けた際に当該指定された色を用いてマーカ表示をしている範囲があれば、表示制御部21は当該マーカ表示をしている範囲を当該指定された色を用いて文字消去表示をする一方、色の指定を受け付けた際に当該指定された色を用いて文字消去表示をしている範囲があれば、表示制御部21は当該文字消去表示をしている範囲を当該指定された色を用いてマーカ表示をする。
(もっと読む)
例文検索装置および例文検索処理プログラム
【課題】電子辞書装置等の例文データベースを活用して翻訳に似た機能を実現することが可能になる例文検索装置を提供する。
【解決手段】格納例文メモリ12dに記憶されている全ての例文のそれぞれを構成する形態素の各単語をキーワードとし、当該キーワードが含まれる例文の文章IDを対応付けて記憶した検索インデックスメモリ12eを用意する。そして、ユーザ入力された文字列(文章)を形態素解析した各単語のそれぞれに対応する文章IDを前記検索インデックスメモリ12eから検索し、その検索された文章IDの出現頻度(出現数)が多い順に当該文章IDに対応する例文とその対訳文を前記格納例文メモリ12dから読み出して、例文検索結果の表示画面Gとして表示する。このため、高度で負荷の重い翻訳機能を必要とすることなく、例文のデータベースを有効に活用して翻訳に似た機能を実現できる。
(もっと読む)
翻訳プログラム、翻訳システム及び対訳データ生成方法
【課題】処理負荷が小さく、かつ、翻訳精度の高い翻訳システム及び翻訳プログラム、並びに、対訳データ生成方法を提供すること。
【解決手段】翻訳システム1は、第1言語で表現された複数の第1言語単文データと、第2言語で表現された複数の第2言語単文データとを含み、対訳関係を有する前記第1言語単文データと前記第2言語単文データとが関連付けられて記憶された第1の対訳データ記憶部32と、前記第1言語で表現された原文データを受け取り、前記原文データの訳文データを出力する翻訳処理部40とを含む。前記翻訳処理部40は、前記原文データに基づいて前記第1の対訳データ記憶部に記憶されたいずれかの第1言語単文データを翻訳対象として選択する翻訳対象選択処理部44と、翻訳対象として選択された第1言語単文データと対訳関係を有する第2言語単文データを前記第1の対訳データ記憶部から読み出して、読み出した第2言語単文データに基づき前記訳文データを出力する対訳出力処理部48とを含む。
(もっと読む)
例文集合ベース翻訳装置、方法およびプログラム、並びに翻訳装置を含んで構成された句翻訳装置
【課題】 句翻訳装置における翻訳精度および速度を向上させる。
【解決手段】 句翻訳装置40は、辞書ベース翻訳方式による辞書ベース翻訳部44、例文完全マッチング翻訳方式による例文完全マッチング翻訳部46、単語アライメント例文ベース翻訳方式による単語アライメント例文ベース翻訳部50、例文集合ベース翻訳部52、例文ベース翻訳方式による例文ベース翻訳部54、ルールベース翻訳方式によるルールベース翻訳部56を備え、入力された句が、順次これらの翻訳部に段階的に入力されるよう構成される。例文集合ベース翻訳部52は、例文対訳辞書66から、入力された句を含む複数の例文対訳組を選択し、複数の例文対訳組における各例文対訳組相互間の共通部分の組をそれぞれ抽出し、抽出した複数の共通部分の組の入力された句に対する支持度合を算出し、支持度合に基づいて選択された共通部分の組における対訳句を第2言語の訳文として出力する。
(もっと読む)
対訳情報生成装置、対訳情報生成方法、及びプログラム
【課題】同義の三言語の単語を含む三言語対訳情報を生成する対訳情報生成装置を提供する。
【解決手段】二言語間の単語を対応付ける情報である対訳辞書であって、第1言語、第2言語、第3言語におけるすべての二言語間をむすぶ3種以上の対訳辞書が記憶される対訳辞書記憶部11と、第1言語の単語、第2言語の単語、第3言語の単語におけるすべての二言語間の単語の組が、対訳辞書記憶部11で記憶されている対訳辞書によってむすばれる関係にある第1言語の単語、第2言語の単語、第3言語の単語の組である三言語対訳情報を生成する三言語対訳情報生成部13と、三言語対訳情報生成部13が生成した三言語対訳情報を出力する三言語対訳情報出力部14と、を備える。
(もっと読む)
着眼点抽出装置
【課題】 ある属性を評価する際に、その属性のどの点に着目して評価したかを知ることが可能な着眼点抽出装置を提供する。
【解決手段】 キーワードが指定されると、記事データ取得手段30は、指定されたキーワードを含む記事データを記事データ記憶手段10から抽出する。着眼ワード取得手段40は、着眼ワード記憶手段60に記憶された着眼ワードが、抽出された記事データに存在するかどうかを確認し、存在する場合には、その着眼ワードを取得する。着眼文作成手段50は、抽出した記事データにおける着眼ワードの係り受け情報を利用して、着眼ワードを含む着眼文を作成する。
(もっと読む)
機械翻訳装置、機械翻訳方法、及びプログラム
【課題】二言語間の機械翻訳を繰り返すことによって、第1言語から第N言語(Nは3以上の整数である)までの翻訳を行う機械翻訳装置を提供する。
【解決手段】第1言語の翻訳対象となる翻訳対象文書を受け付ける翻訳対象文書受付部11、第1言語から第N言語までの同義の単語の組である多言語対訳情報が1以上記憶される多言語対訳情報記憶部12、その1以上の多言語対訳情報から、第i言語(iは1からN−1の整数である)の翻訳対象文書に含まれる単語を含む多言語対訳情報を選択する多言語対訳情報選択部13、選択後の多言語対訳情報に含まれる二言語間の対訳関係が用いられるように、第1言語の翻訳対象文書からはじめて、第i言語の翻訳対象文書を第(i+1)言語に機械翻訳する処理を第N言語まで繰り返す機械翻訳部14、機械翻訳後の第N言語の文書を出力する出力部15を備える。
(もっと読む)
21 - 40 / 125
[ Back to top ]