
Fターム[5D015AA00]の内容
音声認識 (5,191) | 目的、機能 (1,020)
Fターム[5D015AA00]の下位に属するFターム
連続音声の認識 (112)
不特定話者音声の認識 (117)
話者の識別、照合 (293)
キーワードの抽出 (173)
音声理解 (90)
人声以外の音波信号をも認識するもの (219)
Fターム[5D015AA00]に分類される特許
1 - 16 / 16
コミュニケーションロボット
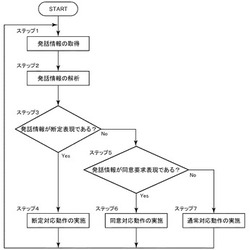
【課題】使用者がロボットに向けて発話するとき、使用者がより話し易く、より親しみを感じることができるコミュニケーションロボットを提供する。
【解決手段】使用者が発する話し言葉を検知する音声検知手段と、所定の応答反応を表出する反応表出手段とを有したコミュニケーションロボットに、使用者の話し言葉に反応して予め定められた複数パターンの応答反応を表出させる。このとき、話し言葉が通常表現であるか否かの判定、話し言葉が同意要求表現であるか否かの判定、話し言葉が断定表現であるか否かの判定の少なくともいずれかの判定を実施し、判定結果に基づいて異なる応答反応を表出させる。
(もっと読む)
音声解析システムおよび音声解析装置

【課題】音声取得手段にて音声を取得し、取得した音声の非言語情報に基づいて話者の心理状態を推定する。
【解決手段】使用者に装着される端末装置と、端末装置から情報を取得するホスト装置とを備える。端末装置は、マイクロフォンにより取得された音声を解析して発話者を識別すると共に、非言語情報である音声特徴量に基づいて発話者の精神活性度を推定し、推定結果を含む発話情報をホスト装置に送信する。ホスト装置は、複数の端末装置から取得した発話情報の中から特定の会話に係る発話情報を抽出して解析し、各発話者の精神活性度の組み合わせに基づいて、会話に参加している各発話者の感情を推定する。
(もっと読む)
音声言語評価装置、方法、及びプログラム
【課題】テキストレベルの言語表現への変換を行うことなく、また事前知識を要することなく、入力された音声信号が示す言語の種類を評価する。
【解決手段】音素表現計算部13で、学習用音声信号から抽出されたメルスペクトルをNMFにより分解して言語の種類毎に音素表現Hと配合比率Uとを求め、音素表現Hを音素表現記憶部14に言語の種類毎に記憶する。評価用音声信号が入力されると、特徴情報抽出部12で、メルスペクトルを抽出し、音素配合比率計算部15で、抽出されたメルスペクトルと、音素表現記憶部14に記憶された音素表現Hとに基づいて、言語の種類毎に配合比率Uを計算する。言語類似性評価部16で、計算された配合比率Uと音素表現記憶部14に記憶された音素表現Hとの積を言語の種類毎に各々計算し、評価用音声信号から抽出されたメルスペクトルとの類似度に基づいて、評価用音声信号が示す言語の種類を評価する。
(もっと読む)
音声出力装置、音声出力方法および音声出力プログラム
【課題】
多言語の音声を出力する音声出力装置において、聞き手集団の使用言語を理解していないことに起因する、情報提供の無駄を軽減する。
【解決手段】
音声出力内容を入力する音声出力内容入力部と、前記音声出力内容に基づいて複数の言語から成る出力音声を生成する出力音声生成部と、周囲環境の音声を入力する環境音声入力部と、前記入力した音声の言語を認識し、言語の構成比を算出する言語構成比算出部と、前記言語構成比算出部で算出した言語構成比に応じて、出力する音声の構成を変更する音声出力構成変更部と、変更された音声を出力する音声出力部と、を有する。
(もっと読む)
情報処理装置
【課題】セキュリティが考慮された、使い勝手の良い情報処理装置を提供する。
【解決手段】画像を入力する第1入力装置(52)と、位置情報と時刻情報との少なくとも一方の情報を入力する第2入力装置(52)と、前記画像の出力指示があったときに、前記第2入力装置(52)が入力した情報に基づいて前記画像の出力に制限を加えるか否かを判断する判断装置(70)と、を備える情報処理装置(50)である。
(もっと読む)
音認識装置および音認識方法
【課題】観測音が認識対象とする音であるか否かの判定を漏れなく行う。
【解決手段】HMMを用いて、観測音から抽出した特徴量の、目的音に基づく第1の認識モデルおよび非目的音に基づく第2の認識モデルに対する尤度と、観測音が目的音および非目的音のうち何れであるかを示す認識結果とを認識部で求め、認識結果が示す認識モデルに対応する尤度を用いて信頼度算出部で認識結果の信頼度を算出する。認識結果と信頼度とを用いて、認識結果の正解率を、観測音が目的音と仮定した場合と、観測音が非目的音と仮定した場合とについて正解率算出部で算出する。警報出力処理部は、認識結果と正解率と基づき、認識結果が目的音を示し、正解率が第1の閾値以下の場合と、認識結果が非目的音を示し、正解率が第2の閾値以下の場合とにおいて、観測音が目的音と非目的音の何れにも属さない未知音であることを示す情報を出力する。
(もっと読む)
情報記録装置
【課題】 情報記録再生装置の使い勝手を向上させる。特にシーンの区切りの設定を簡便
化する。
【解決手段】 音声認識手段を備え、記録中に特徴抽出されたタイミングで、シーンの区
切りを設定し、同時にサムネールを設定する。再生時には、該サムネールと同時に、特徴
抽出時の音声を同時に出力する。
(もっと読む)
悲鳴検知装置
【課題】様々な環境音や会話音声を含む監視空間において、悲鳴の検知精度を向上させた悲鳴検知装置を提供する。
【解決手段】悲鳴の語尾が母音を所定時間継続した音声であるという特質を利用し、悲鳴検知装置2は、監視空間にて音響を集音するマイク部20と、マイク部が集音した音響から音声の母音部分を抽出する母音抽出部220と、抽出した母音部分が、所定の悲鳴音量以上であり、且つ所定時間以上継続していると悲鳴であると判定する悲鳴判定部221と、悲鳴判定部が悲鳴と判定すると異常信号を出力する異常出力部222と、を有する。
(もっと読む)
保留関連発話抽出方法、装置及びプログラム
【課題】より適切に保留に関連する発話を抽出することができる技術を提供する。
【解決手段】
音声特徴量算出部2が、音声信号の音声特徴量を抽出する。音声認識部3が、音声特徴量、音響モデル及び言語モデルを用いて上記音声信号に対して音声認識を行い、音声信号に含まれる発話を検出し、検出された発話についての情報を生成する。保留区間検出部4が、発話についての情報を用いて、隣接する発話の間隔が所定の時間以上である保留区間を検出する。抽出部5が、保留区間に隣接する発話の集合から、保留区間が長いほど多くの数の発話を抽出する。
(もっと読む)
対話学習装置、対話分析装置、対話学習方法、対話分析方法、プログラム
【課題】あらかじめ対話行為ごとの満足度をラベリングしたデータが不要であり、かつ対話における対話行為ごとの満足度を評価する。
【解決手段】本発明の対話学習装置は、評価の段階ごとに、話者の対話行為を出力する状態を持つ隠れマルコフモデルM1,…,MKを学習する。また、すべての対話から話者の対話行為を出力する状態を持つ1つの隠れマルコフモデルM0を学習してもよい。そして、隠れマルコフモデル(M0,)M1,…,MKのすべての状態を互いに接続して、隠れマルコフモデルMCを作成する。なお、学習を繰り返して尤度を改善しても良い。本発明の対話分析装置は、隠れマルコフモデルMCを用いて、対話行為が隠れマルコフモデルMCのどの評価値の状態から出力されたかを推定することで各対話行為の評価値を求め、当該対話の評価値を推定する。
(もっと読む)
発話状態検出装置、発話状態検出プログラムおよび発話状態検出方法
【課題】予め特定話者毎に基準情報を作成することなく、発話状態の検出を可能とすることを課題とする。
【解決手段】発話状態検出装置は、発話者の発話データを取得する発話データ取得部と、前記発話データを周波数解析した結果から高域周波数成分を抽出する周波数成分抽出部と、抽出した前記高域周波数成分について単位時間毎の変動度合いを算出する変動度合い算出部と、所定期間における複数の前記変動度合いに基づいて、所定区間毎の統計量を算出する統計量算出部と、特定発話者の発話データから得られた前記統計量に基づいて、前記特定発話者の発話状態を検出する発話状態検出部とを備える。
(もっと読む)
認証装置、認証方法及びプログラム
【課題】サービスやシステムが第三者に不正に利用されてしまうことを防止する。
【解決手段】入力を受け付けた音声信号に基づく音声と、予め記憶された音声とが、同一人物によって発声された音声であるかどうかを判定することで、ユーザ認証を行う認証装置であって、ユーザを一意に識別するIDと、当該ユーザが発声した複数の言葉毎に生成された複数の音声データとを対応付けて記憶し、さらに、複数の音声データのそれぞれと、ID毎に固有の情報である複数の固有情報とを対応付けて記憶し、端末からIDを受信すると、受信したIDの複数の固有情報のいずれかを特定するための特定情報を当該端末へ送信し、その後、当該端末から送信された音声信号を受信すると、特定情報にて特定される固有情報に対応する音声データを変換した音声信号の特徴と、受信した音声信号の特徴とを比較することにより、同一人物によって発声された音声であるかどうかを判定する。
(もっと読む)
自然言語ユーザインタフェースを漸進的に開発する装置及び方法
【課題】迅速かつ柔軟な自動応答の生成装置及び方法を提供すること。
【解決手段】自然言語ユーザインタフェース生成装置は、ユーザ端末からの会話文の入力に対応した会話文の出力における会話の状況、会話の動作及びそれらの関係を示すコンピュータ上での処理動作をノードとエッジで表現する知識構造の記憶手段と、知識構造を解釈し、複数の対話ルールと対話制御手法の組を予め関連付けて実行する応答手段とを備え、応答手段は、対話制御手法を実施するために、ノードに属する要素のうち少なくとも二つの要素の間の関係において、処理動作の流れを示す関係及び処理動作に必要な関係を対話ルールとして記憶する対話構造記憶手段と、記憶した要素に対して知識構造における関連付けの有無を判別する判別手段と、判別手段による判別の結果に応じて、対話構造記憶手段に記憶された二つの要素の間の関係を変更する変更手段と、を備える。
(もっと読む)
サンプルを用いずあらゆる言語を識別可能な識別方法
【課題】ある連続音の特徴を改善し、あらゆる言語文を正しく識別でき、よって、サンプルを用いず、台湾中国語、英語、日本語、ドイツ語、フランス語、韓国語、ロシア語、広東語、台湾語等のすべての言語を識別可能なあらゆる言語を識別可能な識別方法を提供する。
【解決手段】ある連続音(word)が1個以上の単音を含み、あらゆる言語のある連続音の特徴は、あらゆる言語の未知の連続音から抽出し、これら未知の連続音は、マトリックス値を用いて表示し、144次元空間内に散布され、あらゆる言語の既知の連続音の特徴は、144次元空間に散らばり、知の連続音周囲の未知の連続音の特徴によりシミュレート及び計算され、本発明は12個の弾性フレームを含み、長さが等しく、フィルターが無く、オーバーラップせず、ある連続音を、長さがさまざまな音波(さまざまな音節数を持つ)12×12マトリックスに転換し、ベイズ識別法により比較識別する。
(もっと読む)
発話意図情報検出装置及びコンピュータプログラム
【課題】人間の発話音声に含まれる韻律に関する情報と声質に関する情報とから、発話内容に依存しないパラ言語情報(発話意図)を検出する。
【解決手段】人間の発話音声信号から、発話内容に依存しないパラ言語情報を検出するためのパラ言語情報検出装置60は、発話音声信号の韻律に関する情報を処理するための韻律による音声処理部70と、発話音声信号の声質に関する情報を処理するための声質による音声処理部72と、韻律に関する情報及び声質に関する情報と非語彙辞書50とから発話音声の中の感動詞についてのパラ言語情報(発話意図)を抽出するためのパラ言語情報抽出部74とを含む。非語彙辞書50には、感動詞について、発話スタイル(韻律情報及び声質情報)と発話意図との関係が記憶されている。
(もっと読む)
モデリング装置、モデリング方法、プログラム
【課題】議事録作成時に、様々な条件で発言音声を抽出して効率良く議事録を作成する。
【解決手段】本発明のモデリング装置は、音声入力部1、音線変換部2、発言者認識部3、発言者DB4、意味認識部5、意味DB6、時計部7、座標化処理部8、および関数演算部9からなる。音声入力部1は、発言音声が入力され、音声変換部2は、発言音声をデジタル音声信号に変換する。発言者認識部3は、発言者DB4内の音声特徴のデータパターン等を用いて、発言音声の発言者を認識する。意味認識部5は、発言音声の意味を、意味DB6内の意味の集合体を検索することで認識する。座標化処理部8は、発言者認識部3で認識された発言者、意味認識部5で認識された意味、およびその発言者がその意味の発言をした時点の時刻をそれぞれ座標数値化して3次元座標上の点に表す。関数演算部9は、3次元座標上の各点同士の相関を表す相関関数を演算する。
(もっと読む)
1 - 16 / 16
[ Back to top ]