
Fターム[5D015LL00]の内容
音声認識 (5,191) | 音声認識装置の制御 (1,048)
Fターム[5D015LL00]の下位に属するFターム
後処理 (238)
認識結果の表示・出力 (271)
他の情報入力装置の援用 (113)
多重処理 (13)
動作モードの設定、切換 (73)
音声認識装置の用途 (261)
Fターム[5D015LL00]に分類される特許
61 - 79 / 79
操作装置

【課題】使用者が機器を操作する意図で発生した音声にのみ反応して機器を操作できる操作装置を提供する。
【解決手段】音声認識手段3では、マイクロホン2に入力された音声の意味が予め登録された命令に一致しているか否かを判定し、音声の意味が命令に一致していると判定すれば当該命令を操作手段4に出力する。トリガ手段10は、使用者からの所定の合図を検出したときにトリガ信号を操作手段4に出力する。操作手段4は、トリガ信号を受けた後の所定の受付期間にのみ、音声認識手段3からの命令に従って操作対象であるエアコンAやテレビTVを操作する。
(もっと読む)
提示装置及び提示プログラム

【課題】文章の各文を提示する際の文の提示順を変更する。
【解決手段】文章の文を対話形式で提示する提示装置において、入力装置から操作コマンドが入力されると、これが次のドキュメントを指示するコマンドが格納されているか否かを判断する(154)。次のドキュメントを指示するコマンドの場合、次のドキュメントに移行するための処理を実行する(164)。次のドキュメントを指示するコマンド以外の他の操作命令のコマンドの場合、今回のコマンドに対応するテキストを検索し、提示できるように処理する(156)。
(もっと読む)
会話制御装置
【課題】ーザ発話内容の混乱や不明瞭さにかかわらず、ユーザに対して予め展開したい特定の話題に関する説明文章を出力する。
【解決手段】この会話制御装置は、回答文と、当該回答文の次の順番で出力することが予定される回答文である次候補回答文を指定する次プラン指定情報とをそれぞれが有する複数のプランを記憶する会話データベースと、第1のユーザ発話に応じて、前記プラン記憶手段に記憶されたいずれかのプランを選択し、そのプランが有する回答文を出力し、その後、第2のユーザ発話に応じて、当該プランが有する次プラン指定情報に基づいて、次候補回答文を出力するプラン会話処理部とを有し、前記複数のプランの少なくとも一部は、一つの説明文章を複数に分割して得られる複数の回答文に対応していることを特徴としている。
(もっと読む)
会話制御装置
【課題】ユーザに質問を繰り返して行うことで、ユーザにある結論やアドバイスなどの、予め準備した情報にたどり着かせるための会話を提供する。
【解決手段】会話制御装置は、回答文と、当該回答文の次の順番で出力することが予定される回答文である次候補回答文を指定する次プラン指定情報とをそれぞれが有する複数のプランを記憶する会話データベースと、第1のユーザ発話に応じて、会話データベースに記憶されたいずれかのプランを選択し、そのプランが有する回答文を出力し、その後、第2のユーザ発話に応じて、当該プランが有する次プラン指定情報に基づいて、次候補回答文を出力するプラン会話処理部とを有し、プランの少なくとも一部は、ユーザを誘導するための一連の質問を回答文として有しており、次プラン指定情報は、複数の次候補回答文を指定する情報である。
(もっと読む)
操作装置
【課題】 複数種類のコマンドに係るリスト画面または当該コマンドに対応した処理内容に係るリスト画面を検索する際の操作性を向上させること。
【解決手段】 データ書き換え可能なメモリ9には、複数種類の音声コマンドを羅列した音声コマンドリストが記憶されている。制御回路2は、音声認識装置8を通じてヘルプ画面の表示を指令する音声コマンドが入力されたときは、音声コマンドリスト中の音声コマンドを羅列した音声認識ヘルプ画面をスクロール画面として表示する。制御回路2は、音声コマンドの種類毎の入力頻度を示す履歴データをメモリ9に記憶すると共に、その履歴データにより示される入力頻度が高い音声コマンドほど前記音声認識ヘルプ画面での表示順が下位となるように変更する処理を行う。
(もっと読む)
音声対話処理方法及びシステム並びにそのためのプログラム
【課題】利用者との対話レスポンスを短縮する。
【解決手段】本音声対話処理方法は、対話シナリオに関するデータを格納する対話データ格納部に格納されるデータから、現対話より後に発生する可能性のある対話において用いられ且つ利用者からの回答を認識するための語彙が登録されている認識文法データを特定する特定ステップと、特定された認識文法データを用いて、当該認識文法データに対応する音声認識エンジンを現対話より後に発生する可能性のある対話に先立って起動するステップとを含む。このような処理を行うことにより、音声認識エンジンの起動時間を節約することができ、レスポンス時間を短縮させることができる。
(もっと読む)
テレビ受像機
【課題】ユーザが命令を発声している間、該命令を受け付けているかどうか確認できるようにしたテレビ受像機を提供する。
【解決手段】TV1は、TV1全体の制御を行う制御部11と、テレビ放送信号を処理するチューナ12と、テレビ放送信号から映像信号と音声信号とを分離抽出する映像/音声切換部13と、OSDを映像信号に重畳するOSD処理部14と、映像信号を表示部16に出力する映像処理部15と、映像を表示する表示部16と、音声信号を音声出力部18に出力する音声処理部17と、音声を外部に発生する音声出力部18と、操作部19と、エージェントPGを記憶する記憶部21と、キャラクター画像を記憶するOSD画像メモリ22と、音声入力手段である音声入力部30と、入力音声から雑音を除去する音響処理部31と、音声認識手段である音声認識部32と、認識結果処理手段である認識結果処理部33と、記憶手段である記憶部34と、を備える。
(もっと読む)
データ作成装置及びコンピュータプログラム
【課題】複数のDBのデータから評価対象のシステムで利用可能なデータを作成することができるデータ作成装置を提供する
【解決手段】データ作成装置は、複数のDBに保存されているデータの仕様に関する情報を受信する処理部72と、処理対象のシステムで使用するデータの仕様に関する情報を準備する処理部70と、処理対象のシステムで使用するデータの仕様と、各DBのデータの仕様とを照合することにより、複数のDB中から、処理対象のシステムで使用することができるデータを有するDBを特定する処理部76と、使用可能なDBからデータを取得し、処理対象のシステムで使用するデータの仕様と、取得されたデータの仕様との比較に基づいて、当該取得されたデータを、所定のシステムで使用可能な形式に変換する処理部80,82,86とを含む。
(もっと読む)
音声入力自動化パソコン
【課題】音声入力文字化とキーボード操作を簡易にする為に、音声単音毎に定義処理即ち演算処理する為に、ランダムアクセスメモリーを並列にし、かつスイッチ素子で並列にしたランダムアクセスメモリーに音声をアナログ/ディジタルコンバーターで数値化した、サンプルを逐次ランダムアクセスメモリーに入力し、定義処理即ち演算処理し、単音の一つのパターンと比較して音声文字化を行い、かつソフトウエアの設定やインストールのキーボード操作入力の手続手順を記憶素子から発して行い、更にハードディスク記憶装置など、ソフトウエアプログラムの壊れて作動しないものに対して、強制消去、強制読出しを行え、操作を簡易にした。
【解決手段】磁気ディスク等の磁気のアナログ効果を利用してディジタル圧縮して、情報転送装置等を用い情報を一括管理し、更に情報の読み出し即ち盗みや書込みのイタズラに対処する為の情報安全装置を設け、情報の安全性を高めた。
(もっと読む)
音声対話装置
【課題】 本発明は、ユーザの発話音量を所望のレベルまで効果的に誘導することができる音声対話装置の提供を目的とする。
【解決手段】 本発明は、ユーザとの情報のやりとりを音声によって行う音声対話装置において、ユーザからの発話が入力される音声入力手段と、音声入力手段に入力される発話データに基づいてユーザの発話音量を算出する発話音量算出手段と、音楽を出力する音楽出力手段と、前記音楽出力手段を制御する出力制御手段とを備え、前記出力制御手段は、ユーザの発話音量を所望のレベルまで誘導すべく、音楽出力手段による音楽の出力を開始又は音楽出力状態を維持しつつ、ユーザの発話音量の算出結果に応じて、音楽出力手段により出力する音楽の音量を調整することを特徴とする。
(もっと読む)
音声認識装置
【課題】 本発明は、周辺の騒音レベルとの関係でどの程度の音量で発話すればよいかを話者が感覚的に把握し易い音声認識装置の提供を目的とする。
【解決手段】 ユーザの発話音声に対して音声認識処理を行う音声認識装置において、マイク40に断続的に入力される発話区間を検出する発話区間検出手段と、検出した発話区間内における音に基づいて、発声音量を算出する発声音量算出手段と、検出した発話区間外における音に基づいて、騒音音量を算出する騒音音量算出手段と、算出した発声音量と騒音音量とを対比可能に表示する表示手段とを備えることを特徴とする。
(もっと読む)
発話様式推定装置、発話様式推定方法及び発話様式推定プログラム
【課題】 音素や音節といった構成要素の継続時間長の確率分布を、発話速度の影響を軽減して精度よく推定すること、及び発話速度の分布を精度よく推定すること。
【解決手段】 パラメータ初期化手段106と、パラメータ更新手段107と、収束判定手段108と、発話速度パラメータ記憶手段109と、継続時間長パラメータ記憶手段110とを備えている。そして、与えられた継続時間長データを最も良く説明するよう、発話速度の分布を規定する発話速度パラメータと、継続時間長の分布を規定する継続時間長パラメータとを、収束するまで反復的に更新するよう動作し、発話速度パラメータと継続時間長パラメータとを同時に推定する。
(もっと読む)
選択可能な音声パターンの音声入力方法及び装置
【課題】使用者が各種の入力音声パターンを記憶する必要がなく、且つ音声パターンを限定し認識範囲を縮小しても音声認識の正確性が向上する選択可能な音声パターンの音声認識装置の入力装置を提供する。
【解決手段】複数の音声パターンを提供する音声パターン選択ユニットと、該複数の音声パターンを出力且つ切換えて使用者の選択に供する出力インターフェースと、該使用者により入力された音声を認識して認識結果を得る音声認識ユニットと、データを記録する内容データ・ベースと、該認識結果に基づいて該内容データ・ベースに至り対応データ・ベースを検索するデータ・ベース検索ユニットとを備えてなる音声認識装置の音声入力装置を提供する。
(もっと読む)
音声認識装置および音声認識方法
【課題】特定話者の音声認識率を向上させつつ、不特定話者に対する音声認識率を保持できる音声認識装置の提供
【解決手段】音声認識部7は、特徴量検出部3で検出された特徴パラメータと不特定話者用の隠れマルコフモデル(HMM)および特定話者用のHMMとを参照して、特徴パラメータの系列が生起する生起確率を求める。さらに、音声認識部7は、生起確率を求める過程で、各単語について不特定話者/特定話者用HMMに共通の1つの隠れマルコフモデルの状態系列を持つようにし、その1つのHMMの各状態の確率を、データ格納部4、6に格納される出力確率関数と遷移確率のうち、予め組み合わせが設定されている2組の出力確率関数値と遷移確率を乗算し、この乗算値のうち大きな方を選択し、選択した乗算値に基づいて生起確率を求め、この求めた生起確率に基づいて入力音声の認識を行う。
(もっと読む)
音声認識を実行するための方法、システム、及びプログラミング
本発明は、選択可能な認識モードを有する音声認識、大語彙音声認識に於ける選択肢リストの使用、ユーザが単語変換を選択することが出来ること、一つ又は複数の特定の方法で認識を自動的にオフの状態にする音声認識、大語彙音声認識に関する電話キー制御、電話キー・アルファベット・フィルタリング及綴りを使用する音声認識、ユーザが再発話認識を実行可能な音声認識、音声認識及び音声合成(TTS)生成の組み合わせ、手書文字を用いた音声認識及び/又は文字認識の組み合わせ、音声録音及び再生を用いた大語彙音声認識の組み合わせに関する。  (もっと読む)
(もっと読む)
集中型生体認証
システム(200)は、個人の身元を確認する情報に関連した音声サンプル情報を格納する記憶部(210)を含む。システムは、VoIP(Voice over Internet Protocol)によってパケット化されるとともに呼び出し中に呼出人から得られるデジタルオーディオサンプルを使って呼出人の身元を認証するための要求を、呼出人によって呼び出される通信プラットフォーム(150/152/154)から受ける受信部(221)を含む。さらにシステムは、デジタルオーディオサンプルを音声サンプル情報と照合し、呼出人を本人と認証する処理部(223)を含む。
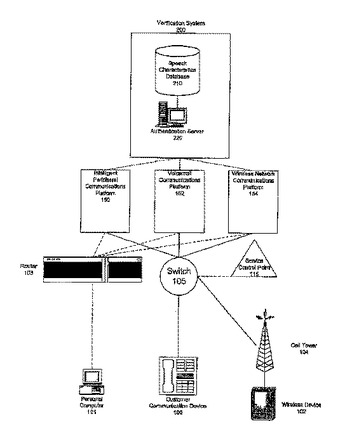 (もっと読む)
(もっと読む)
音声対話装置
【課題】ユーザの発話内容を対話的に理解するにあたり、ユーザからの返答を精度良く認識できるような適切な質問を行って、ユーザの発話内容を効率的に理解できるようにする。
【解決手段】各種名称とその名称の属性を表す複数の分類語とを関連づけて、認識対象語として外部記憶装置7に記憶させておく。そして、ユーザから名称の発話が行われ、信号処理装置6でその発話に対する音声認識処理を行った結果、十分な認識尤度が得られなかった場合には、その名称に対応する分類語のうちで、認識が容易な分類語による返答を求める質問を生成して出力する。
(もっと読む)
音声対話型メッセージング方法及び装置
メッセージ作成方法は、メッセージを作成する要求を受信するステップと、メッセージの受信者を尋ねる第1のプロンプトを出力するステップと、メッセージの受信者を含む、第1のプロンプトに対する第1の可聴応答を受信するステップと、メッセージの本文を尋ねる第2のプロンプトを出力するステップと、メッセージの本文を含む、第2のプロンプトに対する第2の可聴応答を受信するステップと、メッセージを作成するステップとを有する。電子装置は、ユーザに受信者情報の入力を音声でプロンプトし、及びメッセージ情報の入力を音声でプロンプトする音声案内モジュールと、受信者情報の音声によるプロンプト及びメッセージ情報の音声によるプロンプトに対して受信した応答を解釈する音声認識モジュールと、受信者情報の音声によるプロンプト及びメッセージ情報の音声によるプロンプトに対する応答に基づき、メッセージを作成するメッセージコンプライアモジュールとを備える。  (もっと読む)
(もっと読む)
音声対話システム用のユーザ適応対話支援
音声対話システムに直面する共通の課題は、それらのシステムが最適な方法でこのようなシステムについての様々なレベルの経験度を有するユーザに供給しなければならないことである。本発明は、経験の浅いユーザと経験豊かなユーザとを区別し、相応じて適応される音声プロンプトを生成する音声対話システムに関する。このシステムは、経験の浅いユーザと経験豊かなユーザとを区別し、前者には詳細な音声プロンプトを、後者には簡潔な音声プロンプトを発することができる。本発明によれば、音声対話システムは、簡潔な音声プロンプトを使用して音声対話ステップを開始する。システムユーザが、指定時間(認識タイムアウト)後にその簡潔な音声プロンプトに反応しなかった場合、詳細な音声プロンプトが発せられる。したがって、両方の種類の音声プロンプトが、対話ステップ毎に発せられ、システムユーザの選択に利用できる。そのユーザは常にユーザが必要とする種類及び方法の対話を選択できる。経験豊かなユーザは常に対話の過程に関する主導権をとる選択肢を有する。音声対話のある時点においてユーザが音声対話システムによって期待される音声応答の種類について確信がない場合、ユーザは単に認識タイムアウトを待ち、次に詳細な音声プロンプトを聞くことができる。 (もっと読む)
61 - 79 / 79
[ Back to top ]