
国際特許分類[G10L15/00]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声認識 (6,879)
国際特許分類[G10L15/00]の下位に属する分類
音声認識のための特徴抽出;認識単位の選択 (203)
セグメンテーション,または語区切れ検出 (272)
標準パタンの作成;音声認識システムの学習,例.話者適応 (725)
音声の識別または探索 (1,500)
不利な環境に特に適した音声認識技術,例.雑音またはアクセントのある音声 (334)
音声認識処理中の手順,例.マン・マシン対話 (884)
音響以外の特徴を用いる音声認識,例.唇の位置 (190)
音声をテキストに変換するシステム (3)
音声認識システムの構造上の細部 (875)
国際特許分類[G10L15/00]に分類される特許
1,031 - 1,040 / 1,893
プログラム、コンピュータ及び制御方法
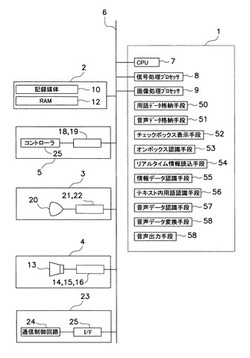
【課題】ゲームに対する思考を中断することなく、情報取得を行うことができるようにする。
【解決手段】本ゲームプログラムでは、サーバから受信したリアルタイム情報が、テキストデータとして制御部1に認識される。そして、テキストデータにおける用語データDに対応する部分のデータが、テキスト内用語データとして制御部1に認識される。そして、テキスト内用語データに対応する音声データVが制御部1に認識される。そして、制御部1に認識された音声データVを音声出力部4に供給する命令が制御部1から発行され、制御部1に認識された音声データVを音声信号に変換する処理が音声出力部4において実行される。そして、音声信号が音声出力部4から音声として出力される。
(もっと読む)
発話訓練装置

【課題】簡易な構成により発話訓練者が発した音声の正否などを直感的に知覚させることができる発話訓練装置を提供する。
【解決手段】発話訓練データ18を記憶する記憶手段17と、前記発話訓練データから訓練課題となる文字列を読み出し、該文字列を表示する表示手段13と、表示された前記文字列に従って発話訓練者が発する音声を入力する音声入力手段14と、入力された音声を認識し、認識結果を生成する音声認識手段15と、前記文字列と前記認識結果との正否を比較判定する比較判定手段11と、比較判定の結果を所定の態様で色を変化させて出力する出力手段16とを備えた構成としている。
(もっと読む)
発言者表示システム、発言者表示方法および発言者表示プログラム
【目的】本発明は、発言者の音声データをもとに氏名を表示する発言者表示システム、発言者表示方法および発言者表示プログラムに関し、発言者の音声データを音声認識して音声テキストデータに変換すると共に声紋テンプレートと照合していずれの氏名、権限の発言者かを判別して表示したり、音声テキストデータを検索して該当する発言を行った発言者の音声を発声すると共に併せて当該発言者の氏名、権限を表示することを目的とする。
【構成】音声データを音声テキストデータに変換すると共に声紋テンプレートと照合して発言者の氏名を判定する手段と、判定した発言者の氏名を表示する手段とを備える。
(もっと読む)
契約支援システム
【課題】契約を行う際に、ユーザの確認が必要な内容につき、ユーザが内容を把握しやすいようにする。
【解決手段】契約支援システム100は、契約を行うために必要な契約者または被保険者の情報を含む契約用データを取得する契約情報取得部102と、ユーザに、当該ユーザの確認が必要な確認情報と当該確認情報に対する回答を発話させる指示とを表示する表示処理部108と、ユーザから、確認情報に対する回答を音声で取得する確認データ取得部112と、契約情報取得部が取得した契約用データに、確認データ取得部が取得した音声の音声データを対応付けて記憶部に記憶する契約用データ書込処理部106と、を含む。
(もっと読む)
音声翻訳装置及びその方法
【課題】音声認識や機械翻訳の失敗の可能性があることを利用者にわかるように翻訳結果を音声で出力できる音声翻訳装置を提供する。
【解決手段】音声翻訳装置10は、音声入力部11、音声認識部12、機械翻訳部13、パラメータ設定部14、音声合成部15、音声出力部16からなり、音声認識・機械翻訳によって得られる複数の尤度から出力する音声データの音声ボリューム値を決定し、尤度の低い語彙に関してユーザに対して音声ボリューム値を小さくして伝わりにくくし、逆に尤度の高い語彙に関してユーザに対して音声ボリューム値を大きくして、特に強調されて伝えられるようにする。
(もっと読む)
音声データ書き起こし支援システム
【課題】音声データの書き起こし作業を効率良く行うことができる音声データ書き起こし支援システムを提供する。
【解決手段】依頼者端末2は、音声データを複数の分割データに分割して、各分割データに対応するメタデータをサーバ1に送信する。サーバ1は、作業者端末6からのアクセスに基づいて作業者端末6に分割データのメタデータを提供し、分割データに対応するテキストデータを作業者端末6から受信してメタデータを更新する。依頼者端末2は、サーバ1におけるメタデータの更新を自動検知して、テキストデータを受信する。
(もっと読む)
静止画像表示システム
【課題】本発明は、台詞が対応付けられた一連の静止画像が順次切り替えられて表示される静止画像表示システムに関し、エンターテイメント性の向上、観覧意欲の喚起を図ることを目的とする。
【解決手段】一連で構成される静止画像毎に関連する所定の台詞に対応する効果音データを効果音DB38に記憶しおき、音声処理部21の音声認識手段31で入力した台詞音声を解析した音声データと、照合テーブル33の現に表示されている静止画像に対応する台詞キーワードとを音声照合手段32が照合し、一致したときの当該台詞キーワードで特定される照合個別信号に基づいて効果音制御手段35が対応する効果音データを効果音DB38より抽出して効果音出力部23に送出して出力させる構成とする。
(もっと読む)
データ呼出制御装置、データ呼出システム、データ呼出制御装置の音声認識語彙登録方法および車両
【課題】予め決められた識別情報をユーザが記憶する必要がなく、容易に外部記憶端末に記憶されているデータの呼出を可能にする。
【解決手段】複数のデータのうち、再生装置によって再生中のデータに付随したタグを取得するタグ取得部10と、ユーザからのボイスタグの登録要求を検出する登録要求検出部13と、登録要求検出部13により登録要求が検出された場合に、タグを構成する複数のカテゴリのうち、ボイスタグを登録するカテゴリを判定するカテゴリ判定部14と、カテゴリ判定部14で判定されたカテゴリの識別情報に対して音声認識部12で認識されたボイスタグを対応付けて登録するボイスタグ登録部15と、ボイスタグ登録部15によって登録したボイスタグと当該ボイスタグが対応付けされたカテゴリの識別情報とを記憶する記憶部18とを具備することを特徴とする。
(もっと読む)
電話による音声を用いてインターネットによる取引にアクセスし、これを処理し、実行するためのシステム及び方法
【課題】電話を使ってアイテム又はサービスに関係する取引を実行するための方法等を提供する。
【解決手段】電話を使ってアイテム又はサービスに関係する取引を実行するための方法等は、前記アイテム又はサービスを識別する情報を提供する段階と、取引が、識別されたアイテム又はサービスと関係付けられる、実行されることになる取引についての問合せを提供する段階と、ユーザーの回答に応答して、識別されたアイテム又はサービスに関係付けられた取引を実行するよう、要求をサーバーシステムへ送る段階とを含んでいる。ユーザーがコンピューターインタフェースで何らの操作を実行することなく、取引は実行される。
(もっと読む)
音声およびテキスト通信システム、方法および装置
本開示はスピーチをテキストに変換し、およびその逆を行うためのシステム方法および装置に関する。一つの装置はボコーダ、スピーチをテキストに変換するエンジン、テキストからスピーチへの変換エンジン、およびユーザインタフェースを含む。ボコーダはスピーチ信号をパケットの中に変換するように動作可能である。スピーチ−テキスト変換エンジンは、スピーチをテキストに変換するように動作可能である。テキスト−スピーチ変換エンジンはテキストをスピーチに変換することが可能である。ユーザインタフェースは、複数のモードの中からユーザ選択を受信することが可能である。ここで、第1のモードはスピーチ−テキスト変換エンジンを使用可能にし、第2のモードは、テキスト−スピーチ変換エンジンを使用可能にし、そして第3のモードはスピーチ−テキスト変換エンジンおよびテキスト−スピーチ変換エンジンを使用可能にする。  (もっと読む)
(もっと読む)
1,031 - 1,040 / 1,893
[ Back to top ]