
Fターム[5B075NK31]の内容
Fターム[5B075NK31]の下位に属するFターム
自然言語解析による検索キーの抽出 (1,229)
抽出領域指定 (82)
特徴箇所を検索キー情報とするもの (542)
Fターム[5B075NK31]に分類される特許
521 - 540 / 566
音声データからのキーワード抽出のための装置,方法,プログラム及び記録媒体

【課題】予め記録された音声データから、キーワードを高精度に抽出できるようにする。
【解決手段】音声データを記録した記録手段から、取り込み対象の音声データの位置をずらしながら、連続する所定量Nの音声データを順次取り込む。そして、取り込んだ各々のこの所定量の音声データと、所定の検索用キーワードの音声データとの音響的特徴をそれぞれ比較照合する。そして、この比較照合の結果この検索用キーワードの音声データと一致していたこの所定量の音声データを、キーワードとして抽出する。
(もっと読む)
情報処理方法、情報処理装置及びデータ処理装置

【課題】 HMM類似度に基づいて動画像を検索する。
【解決手段】 検索が受信される。検索は、時間情報を含むオブジェクトであり得る。静的成分及び時間成分を含む検索モデルが次に、オブジェクトについて判定される。静的成分及び時間成分に対する重み付けも判定される。検索モデルは次に、1つ又は複数のサーチ・モデルと比較される。サーチ・モデルも、静的成分及び時間成分を含む。サーチ結果が次に、比較に基づいて判定される。一実施例では、比較は、検索モデル及びサーチ・モデルの静的成分及び時間成分を比較し得る。静的成分と時間成分との差の重み付けは、サーチ結果のランク付けを判定するのに用い得る。
(もっと読む)
情報処理システム
【目的】インターネットから取得した情報の保存や管理を容易にする。
【構成】クライアント401とサーバ403とが接続された情報処理システムにおいて、クライアント401が、インターネットを介して取得した情報の保存をサーバ403に指示するKPTC1システム402を有し、サーバ403が、データベース406と、クライアント401より保存を指示された情報に所定のインデックスを付与するKPTS1システム402と、付与されたインデックスに基づいて情報をデータベース406に保存管理する知識ベース管理部405とを備える。
(もっと読む)
時間情報抽出装置、時間情報抽出方法、及び時間情報抽出プログラム
【課題】 本発明の目的は、時系列データからどのような流れが存在するのか、及び、なぜそのような流れになったのかを抽出する時間情報抽出装置を提供することである。
【解決手段】 それぞれが時間情報及びテキスト情報を含む複数のデータを入力し(S110)と、テキスト情報とキー概念との対応関係テーブルを用いて、複数のデータから、時系列パターンを生成し(S120〜130)、この時系列パターンから、キー概念が同一、かつ、時間経過が実質的に同一である時系列パターン要素を一つに統合し、コロニーを生成し(S140)、このコロニーから第1のコロニーを指定し(S150)、第1のコロニーとキー概念が相反する第2のコロニーを特定し(S160)、第1又は第2のコロニーから時間情報が古いコロニーを抽出し(S170)、この古いコロニーから、第1又は前記第2のコロニーへの分岐条件となる時間情報を抽出する(S180)時間情報抽出装置。
(もっと読む)
話題語抽出方法及び装置及びプログラム及びプログラムを格納した記憶媒体
【課題】 電子掲示板に途中から参加するユーザが、議論されている話題が何であるかを容易に把握することを可能にする。
【解決手段】 本発明は、電子掲示板の投稿記事を蓄積する記事データベースから、該当投稿記事のタイトルと本文を読み出して、形態素解析し、形態素解析された語句の単位時間における出現頻度を算出し、語句毎に、語句別出現頻度記憶手段に格納し、語句別出現頻度記憶手段から、語句毎の出現頻度を読み出して、該出現頻度が時系列に従って大きくなっている(伸びている)語句を話題語として抽出する。
(もっと読む)
画像文字列検索装置及びそのプログラム
【課題】画像中から少なくとも1つの文字よりなる所定の文字列を検索し、該当文字列を明示的に表示することが可能な画像文字列検索装置及びそのプログラムを提供する。
【解決手段】画像入力手段1から入力され、第1の記憶手段4に記憶された画像に対して文字認識手段81により文字認識処理を実行し、認識結果の候補文字と、当該候補文字の位置情報とを含む多数の文字候補を第2の記憶手段5に記憶し、検索手段82により多数の文字候補からユーザが文字入力手段2から入力した所定の文字列中の文字に対応する候補文字を含む文字候補を検索して第4の記憶手段7に記憶し、検索結果画像作成手段83により検索結果の文字候補の位置情報に従い当該検索結果の文字候補を第1の記憶手段4に記憶された画像上で特定する検索結果画像を作成し、第1の記憶手段4に記憶された画像とともに表示手段3に表示する。
(もっと読む)
情報分類方法及び装置及びプログラム及びプログラムを格納した記憶媒体
【課題】 事前学習することなく、あるキーワードを基に、次々と取得されるような文書データもしくは大量の文書データを解析し、そこからキーワードとの関連性と時間的な新しさという観点で、話題となっている語句を抽出し、その話題語によって文書データを分類することで、よりそのキーワードに関わる特色のある分類をする
【解決手段】 本発明は、話題語の候補を選択し、話題語の候補を集約し、話題語候補に対して、文書との適合度を求め、話題性のための時刻による重み付けを行って集計したものをその話題語候補のスコアとし、スコアが一定値以上、かつ、文書数が一定数以上であれば、残った話題語を文書の情報と共に提示する。
(もっと読む)
情報処理システム、情報処理装置、および情報処理方法、並びにコンピュータ・プログラム
【課題】 機密情報を漏洩することなく管理するとともに、機密情報を参照した有効な情報提供を可能とした情報処理システムを提供する。
【解決手段】 例えば情報要求ユーザの個人的な機密情報を管理サーバのみがアクセス可能な機密情報データベースに格納する。管理サーバは、機密情報を適用して、情報提供ユーザの適任者を検索するためのキーワードを生成し、生成キーワードに基づいて情報提供ユーザを抽出した上で情報提供ユーザに、情報要求端末からの要求内容を提示する。情報提供ユーザは提示内容に応じたコメントを生成して、管理サーバの質問応答データベースに格納する。情報要求ユーザは管理サーバの認証処理における認証成立を条件として質問応答データベースにアクセスし情報提供ユーザのコメントを取得する。
(もっと読む)
プレゼンテーションの取得及び保存のためのシステムと方法
【課題】プレゼンテーションビデオの抽出、分類、保存、ならびに補充を可能とする。
【解決手段】
メディアシステムはプレゼンテーションビデオを伝播するビデオ信号を受信する。メディアシステムは、そのビデオ信号を処理して、プレゼンテーションのスライド用画像を生成する。メディアシステムは、その後、画像からテキストを抽出して、画像を分類してそれをデータベースに保存するためにテキストとその他の特徴を用いる。さらに、システムは、プレゼンテーション視聴者によるプレゼンテーションへのフィードバックを可能にして、プレゼンテーションを補完するのに用いられる。
(もっと読む)
コンテンツ検索装置とその入力装置、コンテンツ検索システム、コンテンツ検索方法、プログラム及び記録媒体
【課題】録画したコンテンツの検索を容易かつ効率よく実行できるようにする。
【解決手段】コンテンツ検索装置は、チューナ部6を通してデコードされたコンテンツを、コンテンツ蓄積部5に蓄積しておく。蓄積されたコンテンツと、そのコンテンツに付随する字幕情報とを字幕解析部8で解析し、コンテンツを所定の単位に分割して、字幕情報を用いた検索用インデックスを付与しておく。そして入力装置から送信された単語からなる検索キーをコンテンツ検索装置の受信部1で受信すると、検索部2は、受信した単語を検索クエリーとして、コンテンツ蓄積部5に蓄積されたコンテンツを検索する。検索結果は送信部3から表示装置4へ転送される。
(もっと読む)
情報処理装置、情報処理装置の制御方法、及びプログラム
【課題】真に論旨形成に寄与しうる各メッセージの相関関係の可視化を可能にする。
【解決手段】複数の発言者からそれぞれ寄せられるメッセージを記憶するメッセージデータベースから各メッセージを読み出し、読み出した各メッセージに含まれる単語の中から所定の単語をキーワードとして選出し、キーワードとして選出された単語のうち他のメッセージにも含まれる単語の総数をメッセージ毎に算出し、メッセージ毎に算出された単語の総数が判定値よりも多いメッセージのそれぞれについてキーワードとして選出された単語の数をキーワード毎に算出し、各メッセージについてキーワード毎に算出された単語の数を示すデータに対して多変量解析演算を行い各メッセージ及び各キーワードの相関を示すデータを算出する情報処理装置に関する。
(もっと読む)
コンピュータネットワーク内でのサーチのためのキーワードの生成
一実施形態では、ドキュメント(710)とのエンドユーザの対話を検出し、該ドキュメントとの該エンドユーザの対話に基づいてキーワードを生成し、及び該キーワードを使用してサーチを実行することにより、サーチ結果がコンピュータネットワーク内で生成される。該コンピュータネットワークはインターネットを含むことが可能であり、前記ドキュメントはウェブページとすることが可能である。例えば、クライアントコンピュータで実行されているプログラム(200A)が、インターネット上でのエンドユーザのブラウジング活動を監視することが可能である。該エンドユーザがリンク(711-1)をクリックした際に、該リンクに関連する情報(該リンクのラベル等)を解析して1つ又は2つ以上のキーワードを生成することが可能である。該キーワードを使用してサーチを実行して、該キーワードに応じたサーチ結果を生成することが可能である。 (もっと読む)
文書概要作成装置、表示装置、情報処理装置、プレゼンテーションシステム、文書概要作成プログラム、文書概要作成装置制御プログラム、表示装置制御プログラム、情報処理装置制御プログラム、文書概要作成方法、文書概要作成装置制御方法、表示装置制御方法及び情報処理装置制御方法
【課題】文書データによって構成される文書画像を被表示部に表示し、当該表示された文書画像を利用してプレゼンテーションを行うシステムにおける、前記文書画像の表示内容の概要を作成するのに好適な文書概要作成装置、表示装置、情報処理装置、プレゼンテーションシステムを提供する。
【解決手段】プレゼンテーションシステム1を、文書データの表示内容におけるプレゼンテーション発表者の意図する強調箇所を判断するための強調箇所判断情報に基づき、文書データの表示内容の概要を作成する文書概要作成装置2と、文書データによって構成される文書画像をスクリーン5に投射表示する表示装置3と、文書概要作成装置2において作成された概要データを取得し、当該概要データによって構成される画像を自己の表示部に表示する複数の情報処理装置4と、表示装置3から光投射される文書画像を表示するスクリーン5とを含んだ構成とした。
(もっと読む)
キーワード抽出方法、キーワード抽出プログラム、キーワード抽出プログラムを記録したコンピュータ読み取り可能な記録媒体およびキーワード抽出装置、並びにメタデータ作成方法、メタデータ作成プログラム、メタデータ作成プログラムを記録したコンピュータ読み取り可能な記録媒体およびメタデータ作成装置
【目的】 Webページからの人および人間関係の汎用的なキーワード、特に人や人間関係に関する特定のコンテクストに関連したキーワードを抽出する方法等、および抽出したキーワードを利用してメタデータを作成する方法等を提供する。
【構成】 名前NおよびコンテクストワードCの入力部からの入力を受け付け(S1)、入力された名前Nを含むWebページからキーワード候補群Wを抽出し(S2)、抽出されたキーワード候補群Wの各キーワード候補wについて、名前NおよびコンテクストワードCとの関連度rを算出し(S3)、そして、算出された関連度rに基づいて、キーワード候補群Wの中から、名前NとコンテクストワードCとを関係付けるキーワードxを抽出する(S4)。
(もっと読む)
音楽再生装置
【課題】 ユーザの状況と環境が示す雰囲気に適した楽曲を面倒な操作を伴うことなく自動再生すること。
【解決手段】 キーワード検出部2は、ユーザの発話内容から予め設定されたキーワードを検出する。感情情報検出部3は、ユーザの発話内容か抽出したプロソディ情報を分析してユーザの感情情報を検出する。ユーザ状況推定部4は、検出したキーワード及び感情情報からユーザ状況を推定する。雰囲気推定部5は、雰囲気要因情報収集部6が収集した車室内の客観的な情報とユーザの状況とから現在の雰囲気を複数のカテゴリの何れかに分類する。メモリ8には、音楽データベース7の多種類の音楽データを各分類カテゴリと対応付けた状態で区分したカテゴリリストが格納されている。検索処理部9は、カテゴリリストから雰囲気推定部4により分類されたカテゴリに属する音楽データを検索し、その音楽データを音楽データベース7から取得する。スピーカユニット10はその音楽データを再生する。
(もっと読む)
コンテンツ登録利用システム
【課題】規格が統一されない大量のコンテンツ素材を有効活用できるようににしたことを特徴とするコンテンツ登録利用システムを提供する。
【解決手段】コンテンツ登録利用サーバ100は、コンテンツ登録部110、コンテンツ利用部120を備え、コンテンツ登録部110において登録者端末300よりコンテンツ素材を登録する際に閲覧情報を抽出する機能があり、コンテンツ利用部120において利用者端末400より抽出された閲覧情報を参照することでコンテンツ素材を用いた編集を行うことができるので、規格が統一されない大量のコンテンツ素材を有効活用できる。また、コンテンツ利用部120はコンテンツ素材の閲覧情報に接続するために2次元コード生成部を備えているので、2次元コードを読み取ることでコンテンツ素材の閲覧情報を参照ことができ、容易に必要とするコンテンツ素材を見つけ出すことができる。
(もっと読む)
概念モデル空間におけるコンテンツの表現及びこれを検索するための方法及び装置
【課題】 モデル・ベクトルを用いてマルチメディア文書を索引付けすること。
【解決手段】 マルチメディア文書からモデル・ベクトル表現を抽出するための方法及び装置。モデル・ベクトルは、マルチメディア文書が一組のカテゴリに属すること、又は、一組の意味概念が当該文書に関連することに対する確信性の多次元的表現を与える。モデル・ベクトルはマルチメディア文書と関連して、そのコンテンツの索引又はカテゴリ化を与えることができ、当該マルチメディア文書を比較、検索、分類、又はクラスタ化するために用いることができる。モデル・ベクトルは、情報探索、マルチメディア・コンテンツの個人化、及びマルチメディア情報貯蔵庫照会、の目的のために用いることができる。 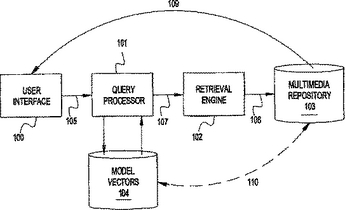 (もっと読む)
(もっと読む)
予め定められた個数の予め定義された質問に応答することによって情報を管理するシステムおよび方法
【課題】 質問に応答するシステムを提供すること。
【解決手段】 本発明は、データマイニングモジュールを使用して、企業データなどのデータをマイニングし、および各々が予め定義されたフォームを有する予め定められた個数の質問に答えるためのデータを構成する。本発明は、ユーザ問い合わせを受信し、およびユーザの問い合わせに応答するユーザインターフェースの構成要素も提供する。
(もっと読む)
ワードクラス情報を割り当てる方法
割当装置(1)はテキスト情報(ETI)の1以上のワードにワードクラス情報(WKI)を割り当てる。ユーザに競合を通知するため或いはテキスト情報(TI)中のワードに関するバックグランド情報(HI)をユーザに与えるため、割り当てられたワードクラス情報(WKI)から形成されたワードクラスシーケンス情報(WK−AI)に基づいて、アクション(A)が実行される。  (もっと読む)
(もっと読む)
キーワード分類装置およびその方法、端末装置ならびにプログラム
【課題】 問い合わせ窓口担当者が過去の類似問い合わせ事例を効率的に探したり、マーケティング担当者が、問い合わせデータを分類してパレート図を効率的に作成できるための、データの全体像把握が可能なキーワード分類装置を構築する。
【解決手段】 キーワード抽出部40は、文書保持部10に保持された複数の問い合わせデータからキーワードとなる名詞句を抽出し、キーワード記憶部50に記憶する。共起表現抽出部60は、前記複数の問い合わせデータから前記抽出されたキーワードの名詞句に共起する述語句を抽出し、共起表現記憶部70に記憶する。分類部80は、前記複数の問い合わせデータをキーワード記憶部50に記憶された名詞句によるキーワードで第1カテゴリに分類し、かつ第1カテゴリに所属する文書を共起表現記憶部70に記憶された前記名詞句によるキーワードに対応する述語句で第2カテゴリに分類し、表示装置3に表示する。
(もっと読む)
521 - 540 / 566
[ Back to top ]