
Fターム[5L096FA67]の内容
Fターム[5L096FA67]に分類される特許
81 - 100 / 1,697
姿勢判定方法、プログラム、装置、システム
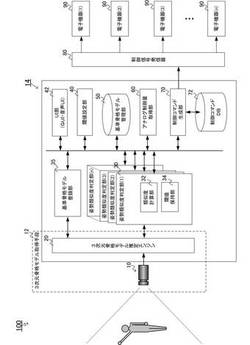
【課題】本発明は、ユーザおよび用途を限定しないNUI(Natural User Interface)を提供することを目的とする。
【解決手段】本発明においては、予め定義された基準姿勢とユーザがとった姿勢の間の類似度を各姿勢の3次元骨格モデルを構成する3次元ベクトルの内積を用いた評価関数によって計算し、所定の閾値に基づいて姿勢の類似度を判定する。本発明においては、2つのパラメータ(基準姿勢の3次元ベクトルおよび類似度の閾値)をユーザが自由に設定することができるので、それぞれのユーザの条件(身体条件・環境条件)および用途に合致したNUIを容易に構築することができる。
(もっと読む)
移動体検出装置、コンピュータプログラム及び移動体検出方法

【課題】移動体を高い精度で検出することができる移動体検出装置、コンピュータプログラム及び移動体検出方法を提供する。
【解決手段】検出ブロック設定部107は、撮像画像上で複数の画素で構成される任意の大きさの検出ブロックを複数設定する。評価値算出部109は、任意の時点tの撮像画像上で、設定した各検出ブロックが移動体の候補領域であるか否かを評価する評価値を検出ブロック毎に算出する。選択部110は、算出された評価値に基づいて、候補領域であると評価された1又は複数の検出ブロックを選択する。移動体領域検出部112は、選択した検出ブロックの撮像画像上の位置及び大きさに基づいて、撮像画像上の移動体領域を検出する。
(もっと読む)
コマンド発行装置、コマンド発行方法およびプログラム
【課題】送り動作と、送り動作とは異なる動作(例えば復帰動作や予備動作等)とを区別可能なコマンド発行装置、コマンド発行方法およびプログラムを提供する。
【解決手段】実施形態のコマンド発行装置は、取得部と検出部と第1設定部と第2設定部と第1算出部と第2算出部と発行部とを備える。取得部は、被写体を撮像した画像を取得する。検出部は、画像から、被写体の特定部分を検出する。第1設定部は、検出部で検出された特定部分の位置を示す特定位置を設定する。第2設定部は、画像のうち基準となる位置を示す基準位置を設定する。第1算出部は、基準位置から特定位置へ向かう位置ベクトルを算出する。第2算出部は、コマンドベクトルごとに、当該コマンドベクトルと位置ベクトルとの一致度を示す第1パラメータを算出する。発行部は、第1パラメータの値に基づいてコマンドを発行する。
(もっと読む)
エッジ検出装置およびそのプログラム
【課題】照明等の撮影条件が変化した場合であっても、映像を構成するフレーム画像のそれぞれからエッジを正確に検出することができるエッジ検出装置およびそのプログラムを提供する。
【解決手段】エッジ検出装置1は、第1閾値および第2閾値を用いて映像を構成するフレーム画像ごとのエッジ点を検出するエッジ検出手段20と、現フレーム画像のエッジ点から当該エッジ点とエッジ勾配強度およびエッジ方向が類似する前フレーム画像のエッジ点を追跡するエッジ追跡手段40と、エッジ検出手段20によって検出されたエッジ点を分布化してガウス混合モデルを生成するとともに、エッジ追跡手段40によって追跡が成功したエッジ点を追加してガウス混合モデルを更新するモデル生成・更新手段50と、生成または更新されたガウス混合モデルの平均値および標準偏差から第1閾値および第2閾値を算出する閾値算出手段60と、を備えている。
(もっと読む)
画像特徴量抽出装置およびそのプログラム
【課題】局所特徴量間の適合性を考慮し、概略の特徴を捉えて一般物体認識の精度を向上させる。
【解決手段】フレーム画像データからエッジ成分を検出するエッジ検出部20と、フレーム画像データから特徴点を検出する特徴点検出部30と、エッジ検出部20が検出したエッジ成分に基づき、特徴点検出部30が検出した特徴点に対する周辺領域の面積を変化させて生成した複数の特徴量を連結して局所特徴ベクトルを生成する局所特徴ベクトル生成部40と、特徴点に対して、局所特徴ベクトル生成部40が生成した局所特徴ベクトルの空間的な共起に基づく共起特徴ベクトルを生成する共起特徴ベクトル生成部50とを備えた。
(もっと読む)
画像処理方法およびシステム
【課題】2D被写体の検出と分離、カメラ姿勢推定、3D形状位置合わせおよび3D画像認識を含む画像処理における被写体の姿勢を推定する方法を提供する。
【解決手段】画像データを分析するための装置はプロセッサを含む。該プロセッサは、被写体の姿勢の複数の予測を得るために前記画像データを分析するよう構成され、前記予測は前記被写体の予測姿勢のインジケーションを含んでおり、前記予測姿勢は共通の座標系の位置、方向、スケールに関して表現され、2つの被写体姿勢間の距離を計算することで前記予測姿勢を比較することにより前記予測をグループ化するように構成され、前記距離は距離関数を用いて計算される。
(もっと読む)
情報処理装置、ダイジェスト生成方法、及びダイジェスト生成プログラム
【課題】より適切なダイジェストを生成する。
【解決手段】情報処理装置において、所定時間撮影された1又は複数の被写体を含む映像情報及び音声情報を蓄積する蓄積部と、前記蓄積部に蓄積された映像情報及び音声情報を用いて、予め設定された1又は複数の要素に基づき、前記所定時間の時系列における所定の単位時間毎の変化量を評価し、評価された結果に基づいて1又は複数のダイジェスト候補を抽出するダイジェスト生成部と、を有し、前記ダイジェスト生成部は、前記ダイジェスト候補に対応する映像情報及び音声情報に含まれる被写体の状況又は特徴をパターン認識し、認識された結果に基づいて前記ダイジェスト候補からダイジェストを生成するパターン認識部を有する。
(もっと読む)
認識装置、方法及びプログラム
【課題】認識精度の低下を防止する。
【解決手段】実施形態の認識装置は、取得部、算出部、主軸選定部、転換点設定部、区間設定部、決定部、及び提示部を備える。取得部は、第1軸〜第n軸を有する座標系で表される特定部位の位置を時系列で取得する。算出部は、位置毎に特定部位の移動ベクトルを算出する。主軸選定部は、移動ベクトル毎に、第1軸〜第n軸それぞれとの内積値である第1内積値〜第n内積値を算出し、絶対値が最も大きい内積値の算出に用いられた軸を主軸に選定する。転換点設定部は、主軸が切り替わる位置を主軸転換点及び方向転換点に設定し、移動ベクトルの方向が主軸成分において切り替わる位置を方向転換点に設定する。区間設定部は、判定対象区間、直前区間を設定する。決定部は、判定対象区間の評価値と直前区間の評価値とを用いて、判定対象区間における特定部位の移動に優位な軸を決定する。提示部は、決定結果に応じた提示を行う。
(もっと読む)
直線検出装置および直線検出方法
【課題】点の数だけなく、直線に関する他の特性も考慮した上で、ハフ変換を利用した直線検出を行うことを課題とする。
【解決手段】ハフ変換部14は、輪郭強調された2値画像データ104に対してハフ変換を実行する。ハフテーブル15には、ハフ変換後の集計値が格納される。直線算出部161は、集計値を補正する。たとえば、直線の原点からの距離に応じた重みづけにより集計値が補正される。あるいは、直線の傾きに応じた重みづけにより集計値が補正される。直線検出部16は、補正された集計値に基づき、直線を検出する。
(もっと読む)
動きベクトル導出装置および方法
【課題】あるブロックについて動きベクトルの候補が複数存在する場合においても、その複数の動きベクトルの中から画質劣化を最小とする動きベクトルを精度良く導出する。
【解決手段】動きベクトル導出部14は、二つの画像フレーム内の対応するブロック間の動きベクトルを導出する。候補ベクトル生成部20は、動きベクトルの計算対象ブロックについて複数の候補ベクトルを生成する。ブロックテクスチャ抽出部22は、候補ベクトルが生成された画像フレーム内のブロックテクスチャを抽出する。輝度差計算部30は、抽出された複数のブロックテクスチャについて、ブロックテクスチャを構成する画素の隣接画素間の輝度差の累積値を計算する。動きベクトル選択部26は、累積値の最大値が残りの累積値よりも所定倍以上の大きさであるとき、最大値が得られたブロックテクスチャから生成された候補ベクトルを前記対象ブロックの動きベクトルとして選択する。
(もっと読む)
生体情報処理装置、生体情報処理方法及び生体情報処理用コンピュータプログラム
【課題】生体画像に表された生体情報の歪みを参照用の生体画像を用いずに検出できる生体情報処理装置を提供する。
【解決手段】生体情報処理装置1は、利用者の特定の部位の表面にある生体情報を表した生体画像を複数のブロックに分割する分割部(10)と、そのブロックに写っている生体情報の一部の模様の複雑さを表す事前複雑度を推定する事前複雑度推定部(11)と、複数のブロックのそれぞれについて、そのブロックに写っている生体情報の一部の像の複雑さを表す事後複雑度を算出する事後複雑度算出部(12)と、複数のブロックのそれぞれについて、事後複雑度と事前複雑度とを比較し、事後複雑度と事前複雑度とに差異があるブロックを、そのブロックに写っている生体情報の一部に歪みがある歪みブロックとして検出する歪み検出部(13)とを有する。
(もっと読む)
領域抽出装置、撮像装置、及び領域抽出プログラム
【課題】撮像された画像から主要被写体の領域を抽出することができる領域抽出装置、撮像装置、及び領域抽出プログラムを提供する。
【解決手段】領域抽出装置140は、撮像された画像から画像特徴量に基づいて第1領域を抽出し、且つ、画像に定められた位置から画像特徴量に基づいて第2領域を抽出する領域抽出部142と、予め定められた条件を第1領域及び第2領域の少なくとも一方が満たすか否かを判定し、第1領域及び第2領域のうち、予め定められた条件を満たす第1領域及び第2領域を選択する判定部143と、判定部143が選択した第1領域及び第2領域の分布を記憶する記憶部145と、を備える。
(もっと読む)
車線認識装置
【課題】車線が認識できない場合でも、仮想車線を設定することができる車線認識装置を提供すること。
【解決手段】自車両の前方の道路を含む領域の画像を撮影する撮影手段11と、前記画像における道路の領域の輝度を検出する輝度検出手段13と、前記輝度検出手段13で検出した輝度に基づき、前記画像における道路の車線を認識する車線認識手段13と、前記車線認識手段13で認識した車線の位置を記憶する記憶手段3と、前記車線認識手段13で前記車線が認識できないとき、前記記憶手段3に記憶された車線の位置に基づき、仮想車線を設定する仮想車線設定手段13と、を備えることを特徴とする車線認識装置1。
(もっと読む)
画像処理装置および方法、並びにプログラム
【課題】より精度よく高速にグローバル動きベクトルを求めることができるようにする。
【解決手段】グローバル動きベクトル予測部は、過去の撮像画像のグローバル動きベクトルから、処理対象のフレームの撮像画像のグローバル動きベクトルの予測値を算出し、有効領域算出部は、その予測値に基づいて、撮像画像上の有効領域を定める。局所特徴量算出部は、撮像画像上の有効領域から局所特徴量を抽出し、積分射影部は、抽出された局所特徴量を所定方向の軸に射影することで、射影特徴ベクトルを算出する。グローバル動きベクトル算出部は、連続する2つのフレームの射影特徴ベクトルのマッチング処理を行うことにより、グローバル動きベクトルを算出する。本発明は、撮像装置に適用することができる。
(もっと読む)
プレゼンテーションシステム、プレゼンテーション装置およびプログラム
【課題】プレゼンテーションの開始前におけるジェスチャーの誤検出を回避することが可能なプレゼンテーションシステムおよびそれに関連する技術を提供する。
【解決手段】プレゼンテーションシステム100は、操作入力受付部とジェスチャー検出部と配信動作制御部とを備える。操作入力受付部は、プレゼンテーションの開始指示を受け付ける。ジェスチャー検出部は、当該開始指示に応答して、プレゼンテーションの発表者PTのジェスチャーの検出を開始する。配信動作制御部は、ジェスチャーの検出内容に基づいて、プレゼンテーションの発表資料の配信動作を制御する。
(もっと読む)
位置検出装置、位置検出方法及びコンピュータプログラム
【課題】検出対象の位置を精度良く検出する位置検出装置を提供する。
【解決手段】所定の位置で所定の向きに設置された撮像装置によって撮像された第一の画像から、検出対象に含まれる第一特徴点eye_2l及び第二特徴点eye_2rの平面座標の位置を検出し、第一特徴点及び第二特徴点の空間座標の位置を取得し、第一特徴点と第二特徴点との間の平面座標における距離と空間座標における距離との比を算出し、撮像装置によって撮像された第二の画像から、検出対象に含まれる第一特徴点及び第二特徴点の平面座標の位置を検出し、距離比と、第二の画像における第一特徴点及び第二特徴点の平面座標と、に基づいて第一特徴点及び第二特徴点の空間座標の位置を検出する。
(もっと読む)
直線検出装置および直線検出方法
【課題】画像内の方向や位置に依存することなく、同様の基準で、ハフ変換を利用した直線検出処理を行うことを課題とする。
【解決手段】ハフ変換部14は、輪郭強調された2値画像データ104に対してハフ変換を実行する。ハフテーブル15には、ハフ変換後の集計値が格納される。直線算出部161は、2値画像データ104内の各直線について、各直線が2値画像データ104を切り取るときの交点を求め、交点間距離Lenを算出する。正規化部162は、ハフテーブル15に格納された集計値を交点間距離Lenで除算し、集計値を正規化する。直線検出部16は、正規化された集計値に基づき、直線を検出する。
(もっと読む)
画像処理方法、画像処理装置及び画像処理プログラム、並びに、画像処理による放射線量推定方法
【課題】撮影画像内の点や短い線や被写体のコーナーなどの凸部分を特徴点として安定・的確に抽出することができるようにする。
【解決手段】元画像内の着目点と当該着目点から角度θ方向に距離dだけ離れた点との2画素の画素値の対の出現度数を用いて方向別の濃度共起ヒストグラムを作成するステップ(S2)と、当該方向別の濃度共起ヒストグラムの要素の出現確率を算出するステップ(S3)と、当該方向別ヒストグラム要素出現確率を用いて方向別自己エントロピの計算を行うステップ(S4)と、元画像の画素値を対応する方向別自己エントロピの値に置換することによって方向別自己エントロピ画像を作成するステップ(S5)と、当該方向別自己エントロピ画像を用いて特徴画像として総乗画像と総和画像とのうちの少なくとも一方を作成するステップ(S6,S7)とを有するようにした。
(もっと読む)
判別器生成方法、装置およびプログラム
【課題】入力画像から眼検出し、追跡する際に、追跡失敗を低減させつつ、眼の開閉状態の判別精度を向上させる。
【解決手段】眼の開閉状態を3以上の段階に分けて、該各状態にある眼を表す画像であることが分かっている複数のサンプル画像と、眼を表す画像でないことが分かっている複数のサンプル画像を用意し、前記状態毎に、該状態にある眼を表す画像であることが分かっている複数のサンプル画像を正解サンプルとして、該状態の隣の段階の状態にある眼を表す画像であることが分かっているサンプル画像は不正解サンプルとすることなく、該状態と段階が2以上離れた状態にある眼を表す画像であることが分かっている複数のサンプル画像のうち少なくとも1つと眼を表す画像でないことが分かっている複数のサンプル画像とを不正解サンプルとして学習させて、判別対象画像が該状態にある眼を表す画像であるか否かを判別する判別器を生成する。
(もっと読む)
車両接近物検知装置
【課題】車載カメラの撮影画像に対して画像認識処理を行って車両に接近する物体を検出する技術において、従来よりも画像認識処理の処理負荷を低減する。
【解決手段】車両1の作動状態を示す車両信号が、後退中を示している場合、範囲Aを物体検出範囲として選択し、停止を示している場合、範囲Bを物体検出範囲として選択し、ウインカが作動している場合、ウインカの方向に応じて範囲BまたはCを物体検出範囲として選択し、選択した物体検出範囲内に限定して画像認識処理を行うことで、車両1に接近する物体の検出を試みる。
(もっと読む)
81 - 100 / 1,697
[ Back to top ]