
国際特許分類[G06F17/28]の内容
物理学 (1,541,580) | 計算;計数 (381,677) | 電気的デジタルデータ処理 (228,215) | 特定の機能に特に適合したデジタル計算またはデータ処理の装置または方法 (34,028) | 自然言語データの取扱い (7,890) | 自然言語の処理または翻訳 (1,147)
国際特許分類[G06F17/28]に分類される特許
91 - 100 / 1,147
用例翻訳システム、用例翻訳方法及び用例翻訳プログラム
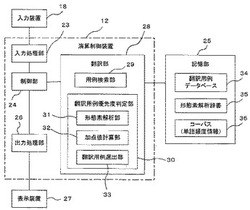
【課題】類似度の計算方法に翻訳対象の分野情報を指標の一つとして加えることで、利用者の求める翻訳結果により近い用例訳文を提供することである。
【解決手段】用例検索部は翻訳対象原文と翻訳用例データベースの翻訳用例原文との類似度を計算し類似度が予め定めた閾値以上の翻訳用例を翻訳用例データベースから検索する。形態素解析部は用例検索部により複数の翻訳用例が検索されたとき複数の翻訳用例のそれぞれの訳文を形態素解析辞書の形態素解析情報を参照して形態素解析し単語を抽出する。加点値計算部は形態素解析部で抽出された前記単語につきコーパスの単語頻度情報を参照し単語の出現頻度に応じて翻訳用例の類似度の加算値を計算する。翻訳用例選出部は用例検索部で計算された類似度に加点値計算部で計算された加算値を加算して最も大きい類似度の翻訳用例を選出する。
(もっと読む)
国際化対応画面生成システム及びプログラム

【課題】アプリケーションの画面の国際化対応に係わり、国際化対応処理の一元管理化により、修正範囲・量の削減などを実現できる技術を提供する。
【解決手段】本国際化対応画面生成システムは、画面出力機能101、UI翻訳機能102、メンテナンス機能103を有する。画面出力機能101は、画面(104)のUIオブジェクトツリーを構築する処理(111)を含む。また、翻訳対象とする翻訳位置情報をDB(118)に管理し、複数の各言語に関する翻訳辞書情報をDB(119)に管理し、組み合わせて利用する。UI翻訳機能102は、UIオブジェクトツリーに対し、割り込み処理(113)、翻訳位置情報に基づき翻訳位置を解析する処理(114)、及び翻訳辞書情報に基づき当該翻訳位置に対応する翻訳対象の値を翻訳値へ変換する処理(115)を行う。
(もっと読む)
文書処理装置、方法、及びプログラム
【課題】異なる言語の一方の文章から他方の文章には含まれない新しい情報を自動的に抽出することにより、共同支援システムにより記述された記事の編集者を支援する。
【解決手段】英語の記事(各文ei)及び中国語の記事(各文cj)を同一の言語に翻訳し、翻訳後の英語の記事の各文ei’と、翻訳後の中国語の記事の各文cj’との類似度を、ei’とcj’との全ての組み合わせについて計算し、各文ei’から最大類似度が最小の文からN個の文を抽出して、対応する翻訳前の英語の文に、新しい情報を含む文であることを示すフラグ「+1」を付与する。英語及び中国語の各文をノード、ノード間の関係を類似度に応じた重み付きエッジで表したグラフを作成し、フラグ「+1」の英語の文を表すノードにラベル1、その他に0を付与し、ラベル伝播により付与されたラベルが最大のノードに対応する中国語の文の前または後を、挿入位置として決定する。
(もっと読む)
同韻語検索装置、同韻語検索方法、同方法を実現するプログラム、及び同プログラムを記録するコンピュータ読み取り可能な記録媒体
【課題】 簡単な操作で迅速に所望の同韻語を抽出できるようにすること。
【解決手段】 母音情報及び鼻音情報が付与された文字列情報を格納する辞書機能と、辞書機能からの文字列情報または入力される文字列情報を表示する機能と、この表示される文字列情報の読み数情報を表示する機能と、この表示される読み数情報に対して所望の位置情報を指定入力する機能と、この指定入力される位置情報に関し当該位置情報を変更可能とする機能と、この変更可能な位置情報を参照して当該位置情報と相当の位置にて指定入力された位置情報に対応する文字の読みの母音情報若しくは鼻音情報と合致する文字列情報を辞書機能から検索抽出する機能と、この抽出された文字列情報を出力表示する機能とを設けたことを特徴とする。
(もっと読む)
音声言語識別装置の学習装置、音声言語の識別装置、及びそれらのためのプログラム
【課題】発話データから、その発話の言語を信頼性高く識別できる音声言語の識別装置を提供する。
【解決手段】学習装置は、言語ラベル付の音声データの記憶装置、これら音声データについて、所定時間長かつ所定シフト長の音声特徴の系列を抽出するブロック特徴生成部180、抽出された音声特徴の系列からコードブックを生成するコードブック算出部184、複数の音声データの各々について、当該音声データから得られた音声特徴の系列に含まれる音声特徴と最も近い代表ベクトルをコードブックから求め、その分布に基づいて当該音声データの言語ラベル付音声言語特徴を生成する言語音素特徴ベクトル算出部186、及びこの音声言語特徴を学習データとして、音声言語特徴から言語を推定するためのSVMを生成するSVM学習部190を含む。
(もっと読む)
文生成装置及びプログラム
【課題】文生成に用いるテンプレートの再利用性を向上させ、条件や参照先の値に応じてきめ細かな文を生成することができる文生成装置及びプログラムを提供する。
【解決手段】本発明の文生成装置は、概念や概念間の関係を示すドメイン知識を体系的に表現したオントロジーと、概念及び概念間の関係に関連付けられたものであって、少なくとも、生成する文の変数とする参照先情報の参照先と所定の文字列とを含む1又は複数の可変部を有する文テンプレートとを格納するオントロジー格納手段と、文を生成する際、オントロジー格納手段から生成する文に関する概念に関連する文テンプレートを選択する文テンプレート選択手段と、選択された文テンプレートの各可変部に含まれている参照先に基づいて取得した参照先情報を展開し、参照先情報の直前及び又は直後に文字列を合成して出力文を生成する文生成手段を備える。
(もっと読む)
対話装置
【課題】対話の自然さを保持しつつ対話内容をコントロールすることができる対話装置を提供する。
【解決手段】対話順序記憶部は、対話文のパターンを複数記憶する。出力部は、第1出力文を出力する。第1受付部は、入力文の入力を受け付ける。第2受付部は、質問文の入力を受け付ける。第1確率算出部は、第1出力文と同一または類似する対話文が出力され、更にその次に対話文記憶部に記憶された対話文のいずれかである第1対話文のそれぞれが出力される確率を表す第1確率をパターンに基づいて算出する。第2確率算出部は、パターンに基づいて、第1対話文ごとに、第1対話文の次の次に質問文と同一または類似する対話文が出力される確率を表す第2確率を算出する。選択部は、第1確率と第2確率とを重み付け加算した値が最も大きい第1対話文を第2出力文として選択する。
(もっと読む)
バイリンガルコーパスを同時セグメント化するための装置及びそのコンピュータプログラム
【課題】過学習の問題なくトークンのソース及びターゲットシーケンスを同時セグメント化する装置を提供する。
【解決手段】装置は、第1及び第2の文字シーケンスを記憶する記憶部と、第1及び第2のシーケンスのブロック対を同時セグメント化する同時セグメント装置と、各フレーズ対の発生を計数するカウンタ74と、ブロック対をランダムにサンプルするサンプル抽出器88と、サンプルされたブロック対中のフレーズ対の数から1を引く減算器100と、サンプルされたブロック対に対する可能な全同時セグメント化の確率を計算する計算器102と、計算された確率に従って、可能な同時セグメント化の1つをサンプルするサンプル抽出器106と、フレーズ対の計数を更新する更新部108と、サンプル抽出器88から更新部108までを、終了条件が満たされるまで繰返し動作させる繰返し制御部90とを含む。
(もっと読む)
対話処理装置
【課題】ユーザ感情状態の変化を促すような応答文を作成することができる対話処理装置を提供する。
【解決手段】ユーザの感情の認識と、知識データベースを用いたユーザに対する感情表現とを実行する対話処理装置であって、ユーザ感情の認識結果から、感情の種別及び感情の強さを成分とした座標系における現在点を得るとともに、この座標系において現在点よりも目標とする感情の収束状態に近い経由点を決定する処理を含み、知識データベースは、複数の語彙及び定型文のそれぞれを、感情の種別及び感情の強さに応じたパラメータに関連付けて示すものであり、前記ユーザに対する感情表現は、経由点での感情の種別及び感情の強さに応じたパラメータで知識データベースを検索することで、対話に用いるべき語彙及び定型文の少なくとも一方を得て、その取得結果を用いた応答文を作成することでなされる。
(もっと読む)
質問応答システム
【課題】利用者による質問の焦点を精度良く推定し、回答すること。
【解決手段】質問応答システム10は、利用者が質問を入力する音声入力部11と、入力された質問の構文を解析する音声認識部12と、解析結果に基づき入力された質問の種類を判定する質問タイプ同定部15と、質問タイプ同定部15により入力された質問の種類がYes又はNoで回答できる種類であると判定された場合に、入力された質問の焦点を決定する焦点解析部16と、焦点解析部16により決定された焦点に応じて、適切な回答文を生成する回答文生成部17と、あらかじめ焦点となる文節の位置が設定された解析済み文を記憶する文例データベース18と、を備える。焦点解析部16は、入力された質問文と前記解析済み文との、それぞれの最終文節の働きの比較と、当該最終文節に係る文節の機能語の比較と、当該機能語の出現順とに基づいて、入力された質問の焦点を決定する。
(もっと読む)
91 - 100 / 1,147
[ Back to top ]