
Fターム[2C150DF03]の内容
玩具 (16,863) | 音、発音 (736) | 音の出る玩具 (372) | 人の声又は人の出す音 (134) | 意味のある言葉 (92)
Fターム[2C150DF03]に分類される特許
41 - 60 / 92
オーディオ・アニメーション・システム
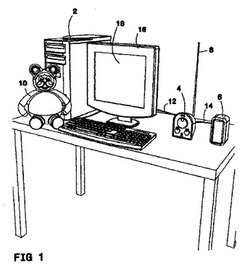
【課題】 良好な品質を与える音声アニメーションのシステムと方法を提供すること。
【解決手段】 本発明のオーディオ・アニメーション・システムは、(A)複数のフィギャーと、(B)オーディオ・プレーヤと、前記オーディオ・プレーヤは、前記複数のフィギャーに対応する複数のオーディオ・ソースを有し、前記複数のフィギャーに関連したオーディオ信号を再生し、(C)前記複数のオーディオ・ソースに対応する複数のスピーカ・ユニットとを有する。
(もっと読む)
音声合成装置、音声合成方法、および音声合成用プログラム

【課題】合成音声を聞いたユーザが、その合成音声に対応づけられたオブジェクトとの位置関係やそのオブジェクトの状況や発話の意図を想起しやすい合成音声を生成する。
【解決手段】合成パラメータ決定部21は、少なくとも方向C、距離r、相対角度のいずれか、またはその組み合わせによって示される位置関係もしくはオブジェクト01の周囲の環境に応じて、音声合成パラメータを決定する。音声合成部22は、合成パラメータ決定部21が決定した合成音声パラメータに従って、オブジェクト01に対応づける音声を合成する。合成パラメータ決定部21は、例えば、所定の制御方針に基づき各入力パラメータの値に対応する合成音声パラメータの値を登録したパラメータ決定テーブルを備え、各入力パラメータの値に応じてパラメータ決定テーブルを参照することによって、合成音声パラメータを決定する。
(もっと読む)
ロボット
【課題】本発明は、音声合成部と音声認識部の設定およびセリフとなる文字列を自動的に適切に調整し、ユーザの作業を簡易化することができるロボットを提供する。
【解決手段】出力音声を合成する音声合成部3と、入力音声の認識を行う音声認識部4と、前記音声合成部3および前記音声認識部4の設定を調整する調整部5とを備えたロボット1において、前記調整部5は、前記出力音声を前記音声認識部4の入力音声とした認識結果を基に調整するものである。
(もっと読む)
ロボット
【課題】 ロボットとの対話時に、ユーザがメモとして記録しておきたい部分を自動的に記録し、ユーザがロボットとの対話時に発する音声を基にメモを自動的に再生することにより物忘れ防止が可能なロボットの提供
【解決手段】 ロボットとモニタ対象者の対話中にメモ処理部31は、対話処理部24から正規化されたモニタ対象者の入力音声を取得する。メモ登録処理部31−1は入力音声と登録用キーワードが一致するとそれに続く音声をメモ音声としてメモ音声登録メモリに登録する。また、メモ再生処理部31−2は、入力音声が再生用キーワードと一致するとメモ音声を再生する。また、入力音声が停止用キーワードと一致するとメモ音声再生を停止する。
(もっと読む)
対話型玩具及びエンタテインメント装置
エンタテインメントシステムは、エンタテインメント装置と、対話型玩具とを備える。エンタテインメント装置は、動作中に対話型玩具の物理的能力を記述するデータを対話型玩具から受信するように構成される無線受信機と、対話信号を生成する処理手段と、動作中に対話信号を対話型玩具へ送信するように構成される無線送信機とを備え、生成された対話信号は、対話型玩具の物理的能力を記述するデータに応答する。対話型玩具は、動作中に該対話型玩具の物理的能力についての情報を要求する問い合わせ信号を受信するように構成される無線受信機と、該対話型玩具の能力を記述するデータを提供するためのデータ提供手段と、動作中に問い合わせ信号に応答して該対話型玩具の物理的能力を記述するデータを送信するように構成される無線送信機とを備える。エンタテインメント装置は、動作中にエンタテインメント装置によってプレイされているメディアコンテンツに応答する対話型玩具へ対話制御データを送信するように構成され、対話制御データは、対話型玩具から該エンタテインメントシステムへ事前に送信されている受信側対話型玩具の物理的能力にさらに応答する。 (もっと読む)
情報再生装置及び情報入力装置
【課題】 フィギアやカードを用いて多彩な出力が可能な情報再生技術を提供する。
【解決手段】 少なくとも底部にドットパターンが形成されたフィギアと、前記フィギアが載置されるステージと、前記ステージに設けられた1又は2以上の読取孔より読取光を照射してその反射光でドットパターンを読み取る光学読取手段と、前記読取結果に対応した音声情報および/又は画像情報を記憶する記憶手段と、前記記憶手段から読み出した音声および/または画像情報を出力する出力手段とを備えた台座とからなる情報再生装置としたことによって、フィギアの底面のドットパターン毎に異なる音声等を出力することができるため、ユーザに対して、あたかもフィギアのキャラクタが発声しているような親近感を抱かせることができる。
(もっと読む)
玩具型移動電話端末
【課題】幼い子供であっても簡単に発呼操作や受話操作を行うことを可能にする移動電話端末を実現する。
【解決手段】移動電話端末は、制御部と、音声入出力部と、制御部及び音声入出力部に接続された音声符号化/復号化部と、制御部及び音声符号化/復号化部に接続された無線通信回路と、無線通信回路に接続されたアンテナと、制御部に接続され、移動電話端末内の異なる位置にそれぞれ配置された1つ又は複数の第1の感圧センサーとを具備する。当該携帯電話端末はさらに、1つ又は複数の電話番号を記憶するとともに1つ又は複数の電話番号の各々と前記1つ又は複数の第1の感圧センサーの各々との対応関係を記憶する記憶部を具備する。制御部は、第1の感圧センサーの1つに加えられる圧力が第1の閾値に達したことに応答して、該第1の感圧センサーと対応づけられている電話番号宛に発呼を行う。
(もっと読む)
知育玩具
【課題】乳幼児が楽しみながら学習できるものであって、知育可能な知育モードの量が多く、長い期間飽きがこない知育玩具を提供する。
【解決手段】知育玩具1は、台座部2と、当該台座部2に開閉可能に接続された上蓋3と、基本知育モードで用いる基本シート18と、知育内容を変更する複数の交換シート19とを有し、台座部2は、方形状の薄板であって縦横等間隔に複数のセンサを備え上方に基本シート18及び交換シート19が敷設される操作パネル11と、交換シート19の種類を判別するシート判別装置56とを有し、上蓋3は、液晶表示装置53と、学習モード切替ボタンと、音声出力装置53とを有し、基本シート18或いは交換シート19上の所定の位置が押されると、押された位置に対応した画像を液晶表示装置53に表示すると共に音声を音声出力装置53から出力する。
(もっと読む)
音声再生システム
【課題】事物認識能力を向上させるための言語学習を、幼児期の子供に、自発的且つ効率的にさせること。
【解決手段】RFIDタグ200は、対象物を特定する固有ID信号を送信する。音声発生部300は、RFIDタグ200から送信される固有ID信号を受信するアンテナ311と、受信される固有ID信号により対象物を識別する信号判読部312と、対象物に関する音声情報を保存する音声情報保存部320と、信号判読部312によって識別される対象物に関する情報を音声情報保存部320から読出す音声情報読出部314と、音声情報読出部314によって読出される情報を音声として出力する音声出力部330とを具備している。RFIDタグ200は、音声発生部300からの励起信号により、固有ID信号を送信する。
(もっと読む)
会話ロボットシステム
【課題】話し相手の感情に応じた会話等を行うことができるとともに、当該会話等を使用目的や状況に応じて容易に更新できる。
【解決手段】 音声入力器2、音声出力器3、表情出力器5、および動作出力器6を備えたロボット1と、当該ロボット1とは別体に設けられてこれに無線で接続されたコンピュータ4とを備える。コンピュータ4は、音声入力器2を介して入力した音声を分析して感情パラメータを算出するステップと予め各感情パラメータに応じて定められた発話シナリオ、表情シナリオおよび動作シナリオに基づいて音声出力器2を介して所定の音声を出力するステップ、表情出力器5を介して所定の表情を創出するステップ、および動作出力器6を介して所定の動作を実現するステップとをそれぞれ実行する。上記各シナリオはコンピュータ4のメモリ42に更新可能に記憶されている。
(もっと読む)
会話ロボット
【課題】話し相手の感情に応じた会話等を行うことができる会話ロボットを提供する。
【解決手段】
音声入力器2、音声出力器3、表情出力器4、および動作出力器5、これらが接続され音声認識手段を構成する処理装置1を備えている。処理装置1は、音声入力器2を介して入力した音声を分析して複数の基本パラメータを算出するステップと、基本パラメータから複数種の感情パラメータを算出するステップと、予め各感情パラメータに応じて定められた発話シナリオに基づいて音声出力器3を介して所定の音声を出力するステップと、予め各感情パラメータに応じて定められた表情シナリオおよび動作シナリオに基づいて、表情出力器4を介して所定の表情を創出するステップと、動作出力器5を介して所定の動作を実現するステップとをそれぞれ実行する。
(もっと読む)
録音再生する模造口腔体
【課題】よりリアルに故人をしのぶことができる録音再生する模造口腔体を提供する。
【解決手段】故人の歯又は義歯と、録音再生装置を備える。上あご部と下あご部は再生する音声の音量に合わせて開閉する。汎用通信インターフェースを備え、パソコンなどの機器と通信可能であり、パソコンを使用して音声データを模造口腔体のメモリに格納したり読み出したりすることができる。模造口腔体は口腔部を模して形成されるが、仏像などの像に組み込んでも良い。
(もっと読む)
玩具体制御システム、制御プログラム、玩具体
【課題】 管理しているスケジュールを多様な形態でもってユーザに告知することで、スケジュールの告知に遊技性を持たせることを提案する。
【解決手段】 スケジュールの種類を示すコード、コードが示す種類に関連した音声データ、コードが示す種類に関連した画像データ、を関連付けて第1のメモリに格納する。スケジュールを設定した日時情報とこのスケジュールの種類を示すコードとを関連付けて第2のメモリに格納する。現在日時が日時情報が示す日時から所定期間前に達した場合、この日時情報に関連付けて格納されている種類情報に関連付けて格納されている音声データと画像データとを取得する。取得した画像データに基づいた画像を表示し、取得した音声データを音声出力装置に出力する。音声データの出力後、上記特定したコードが第1の種類を示す場合、音声出力装置による音声出力を行った旨を表示する。
(もっと読む)
アンドロイド制御システム
【課題】自然な動作を実行する擬似人間ロボットを提供すること。
【解決手段】アンドロイド制御システム10はアンドロイド12を含み、アンドロイド12は人間の代役として或る場所に配置される。通常、アンドロイド12は、制御装置14の制御に従って、人間との間で対話するなどのコミュニケーションを図る。ただし、アンドロイド12自身が対応できない場合には、その旨を遠隔オペレータに通知する。かかる場合には、遠隔オペレータの指示に従って、アンドロイド12は動作される。また、アンドロイド12は、たとえば、その近傍や周囲に人間が存在しない場合や遠隔オペレータからの指示がない場合には、制御装置14の制御に従って無意識動作を実行する。つまり、瞬きや呼吸のような生理的な動作をしたり、髪を触るなどの癖による動作をしたりする。
【効果】 無意識動作のようなアンドロイド特有の動作を実現できる。
(もっと読む)
生活リズム人形
【課題】患者が受け入れることのできる、生活リズムを保つ指示を行う、生活リズム人形の提供。
【解決手段】人形の中に、電源2と、時計を内蔵したコンピュータ3と、音声録音用のマイクロフォン4と、録音再生装置5およびスピーカー6とを内蔵させ、両方の手のひらに操作スイッチ9を設け、人形の会話によって1日の生活のリズムが指示されることにより患者はそれを受け入れることができるようにした生活リズム人形。
(もっと読む)
ロボット、音声変更方法及び音声変更プログラム
【課題】ユーザから提示される物体を視覚で認識して言葉を覚えるロボットを提供する。
【解決手段】ロボットはまず、ある対象を想定してそれを示すランダムな音声を発する。ユーザはそれに対して物体を提示し、提示された物体が想定した対象であるならば、ロボットは歓喜の声をあげ、ユーザはその物体が望みの物体であることを知る。次に、ロボットは、同じ言葉を発するが、その言葉がユーザが対象としてふさわしくない場合は物体を提示しない。するとロボットは別の言葉を発し、ユーザが言葉が希望する言葉に近づいたと判断した場合に物体を提示する。これを繰り返すことで、望みの言葉に近づける。そして最終的に2回連続する同じ言葉に対して物体を提示することで言葉を確定させる。
(もっと読む)
対話ロボットシステム
【課題】本発明はRFタグと赤外線タグを装着した複数のユーザに対し対話・サービスを行う対話ロボットに関し,ユーザが直接見えないが近傍にいる場合や,ユーザがロボットの正面にいないがロボットの方向を向いて興味を示しいる場合や,ロボットの方を向いてない場合でも,ユーザに適したサービス,コンテンツを提供することを目的とする。
【解決手段】周囲に存在するユーザが装着するRFタグを読み取って各々のIDを検出するRFタグ信号読み取り手段と対話ロボットの胴体等の身体の全周に各方向に向けた複数個の赤外線信号の送・受信手段を設ける。RFタグ信号読み取り手段により周囲の一定エリアに存在するユーザのIDを検出してメンバリストを作成し,該メンバリストに基づいて複数方向の各赤外線信号の送・受信手段からIDを含む赤外線信号の送信し,どの赤外線信号の送・受信手段で受信したかを検出して相手の方向を識別するよう構成する。
(もっと読む)
発音玩具
【課題】 歌唱や伴奏に合わせて動き、カラオケも楽しめる人形を提供することで、飽きることのない玩具を提供する。
【解決手段】 駆動機構を有する人形と、前記人形と一体とされる音声合成装置本体とスピーカ、前記音声合成装置本体内部に設置される音声混合回路から構成され、前記音声合成装置本体はスピーカとハンディマイクとが接続可能であり、前記音声混合回路は、マイク端子から入力されたアナログ信号とオーディオ端子から入力されたアナログ信号をミキサー回路により重ね合わせ、メインアンプを通してから人形の足部に設置されたスピーカから拡声するものであり、ドライバにより駆動機構の動力源への電圧の印加を行い、駆動機構により人形を動作させる発音玩具とするものである。
(もっと読む)
ロボットにおける対話相手識別方法およびロボット
【課題】安価に、かつ信頼性高く、対話相手(人またはロボット)の識別、方向判別を可能とし、対話相手に応じた対話/サービスの提供を可能とすること。
【解決手段】対話ロボット10の身体(例えば胴回り)に、複数方向に向けて配置した赤外線発受信ユニット11を設け、ユーザ(人間)20はユーザの識別信号を発信する赤外線発受信ユニット21を装着する。ロボット10は、上記赤外線発受信ユニットの、どの受信器によって相手からの赤外線が受信されたかによって、対応する相手が自分からみてどちら方向にいるかを知り、また、受信した識別信号を解読することによって、対応する相手が誰かを知る。そして、ロボット10は、その顔部(頭部)あるいは身体の向きを検出されたユーザ方向に向け、識別した相手に応じた対話/サービス内容を選択し、上記相手に対して言語・非言語に基づく対話/サービスを行う。
(もっと読む)
音声認識装置および音声認識装置を備えたロボット
【課題】 音声認識の頭切れを防止するとともに、テンポのよい会話を実現することができる音声認識装置および音声認識装置を備えたロボットを提供する。
【解決手段】 会話の台詞を組み立てる制御部53と、台詞に基づいて出力音声信号を生成する音声合成部55と、出力音声信号に基づいて出力音声を出力するスピーカ18と、ユーザ音声を少なくとも含む音声を入力信号に変換するマイクロフォン14と、入力信号から出力音声に係る信号成分を除去して入力音声信号を生成する出力音声除去部57と、入力音声信号に基づいてユーザ音声を認識し、認識結果を制御部53に出力する音声認識部59とを備え、制御部53,61が、台詞に基づいて、音声認識部59によるユーザ音声の認識開始のタイミングを、出力音声の出力開始から所定時間後、かつ、出力音声の出力終了前に制御することを特徴とする。
(もっと読む)
41 - 60 / 92
[ Back to top ]