
Fターム[5B075QM08]の内容
Fターム[5B075QM08]に分類される特許
81 - 100 / 1,166
データ分析の分析軸推薦方法、システム、及びプログラム
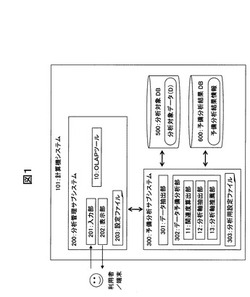
【課題】多次元データ分析における利用者(分析担当者)による分析対象とするデータ項目の組の選定に要する試行錯誤の削減などを可能とする技術を提供する。
【解決手段】本システム(101)では、多次元データ分析の分析軸を推薦する処理機能を有し、多次元データのデータ項目間のデータの関連度を算出する処理(11)と、上記関連度に基づいて、分析対象に適するデータ項目の組を抽出する処理(12)と、多次元データ分析の際、上記抽出したデータ項目の組を、分析者に対して推薦する分析軸として提示する処理(13)とを行う。上記構成により、分析対象とするデータ項目の組(分析軸)の選定を支援する。
(もっと読む)
文書インデックス作成装置

【課題】文書ファイルの記述内容に可及的に即した文書インデックスを作成する。
【解決手段】ネットワークシステムSは、文書データベース10と、この文書データベース10に対して所定の検索アルゴリズムを用いて検索処理を行う検索エンジン20と、ユーザが利用する端末装置30と、文書検索用の文書インデックスの作成処理を行うデータ処理装置40とを含む。データ処理装置40は、一の文書ファイルの文書データを複数の段落に区分すると共に、注目単語Aを含む第1単位文章(段落)と、注目単語Aを含まない第2単位文章(段落)とに区別する。そして、第1単位文章と第2単位文章との文章関連度を評価し、第2単位文章の段落重み値を求める。注目単語Aの出現頻度に基づく基礎重み値に、前記段落重み値を加算することで、当該注目単語Aの重み値を設定する。
(もっと読む)
信号処理装置および方法、並びにプログラム
【課題】入力信号から楽曲を精度良く同定する。
【解決手段】マスクパターン生成部55は、時間周波数領域に変換された入力信号の各領域における楽曲らしさに応じた重み分布であるマスクパターンを生成し、類似度算出部71は、マスクパターンによる重み付けに基づいて、時間周波数領域に変換された入力信号の各領域における特徴量と、時間周波数領域に変換された参照信号の各領域における特徴量との類似度を算出する。本発明は、入力信号から楽曲を同定する信号処理装置に適用することができる。
(もっと読む)
類似ユーザ抽出方法、類似ユーザ抽出装置、類似ユーザ抽出プログラム
【課題】協調フィルタリングにあたってコンテクストを考慮した類似ユーザを抽出する。
【解決手段】各ユーザが、コンテクストのタクソノミ中、クラス配下のサブクラスを経由してアイテムにアクセスしているかどうかを表現するベクトルの各要素を求める(S01)。この要素を各クラスに対して求め、各クラスのコサイン類似度を計算し、その合計をユーザ間のコンテクストの類似度を算出する(S02)。この類似度を各ユーザがアイテムに与えた評点に反映させる(S03)。この評点に基づきユーザ間類似度を算出する(S04)。被推薦ユーザとのユーザ間類似度の高いユーザ群から、被推薦ユーザの入力したコンテクストを持つユーザ集合を類似ユーザ集合として抽出する(S05)。
(もっと読む)
文書分析装置およびプログラム
【課題】複数のカテゴリの内容を相互に比較するのに好適な特徴語を抽出することが可能な文書分析装置およびプログラムを提供することにある。
【解決手段】単語抽出手段は、カテゴリ情報格納手段に格納されているカテゴリ情報によって示される第1のカテゴリに属する複数の文書に含まれる単語を抽出する。文書数算出手段は、抽出された単語が第1のカテゴリに属する複数の文書において出現する文書の数を示す第1の文書数および第1のカテゴリの下位に位置する第2のカテゴリに属する複数の文書において出現する文書の数を示す第2の文書数を算出する。特徴度算出手段は、第1のカテゴリに属する文書の数、第2のカテゴリに属する文書の数、第2のカテゴリの数、第1および第2の文書数に基づいて、前記抽出された単語の特徴度を算出する。特徴語抽出手段は、特徴度に基づいて前記第1のカテゴリに対する特徴語を抽出する。
(もっと読む)
クラスタリング・システム、方法及びプログラム
【課題】 クラスタの大域最適性を保証しつつ、計算量的に効率的なクラスタリング技法を提供すること。
【解決手段】 入力データ群の各データ間の類似度を与える分布に基づき計算された固定中心および固定バンド幅の多数のカーネル要素を用意し、各カーネル要素には、非負の混合重みが割り当てられる。次に、所与のカーネル要素と、それに近い固定中心および固定バンド幅をもつカーネル要素が選ばれ、混合重みの対数尤度関数の単調性の判定に基づき、一方のカーネル要素に対応する配列要素の刈り込み、他方のカーネル要素に対応する活性配列要素の刈り込み、または、一方のカーネル要素に対する一方向最適化が実行される。一対のカーネル要素に対する処理が配列要素全体に対して完了すると、その時点で、混合重みの収束が判定され、もし収束しているなら、混合重みに基づき、入力データ群のデータがクラスタリングされる。
(もっと読む)
データ分類装置、データ分類方法及びデータ分類プログラム
【課題】クラスタリングの再計算が不要で且つ既存のクラスタリング結果に影響を及ぼすことなく適切なデータの分類を行う。
【解決手段】新規データZを訓練データXから学習した変換行列Mによって固有空間に変換するデータ分類装置1であって、訓練データX間の類似度行列Kを計算する類似度計算部5と、類似度行列Kと訓練データXに対応した固有ベクトルQとに基づき類似度行列Kをその固有空間に変換するための変換行列Mを算出する固有空間学習部6と、新規データZの分類処理時に類似度計算部5によって算出された訓練データXと新規データZとの類似度行列Hと固有空間学習部6によって算出された変換行列Mとから新規データZを固有空間に変換する固有空間変換部7と備える。
(もっと読む)
表示装置、表示方法、およびプログラム
【課題】オブジェクトの分類の基準となった観点とは別の観点に基づいた類似オブジェクトを、別の観点を明示的に指示する手間をかけることなく他の分類から抽出して表示できる表示装置を提供する。
【解決手段】保持部170がオブジェクトとオブジェクトが属するグループを保持し、操作受付部110において第1のオブジェクトと第2のグループとを対応付ける操作が行われたと操作判定部120が判定した場合に、共通属性抽出部130が第1のオブジェクトが属する第1のグループに属する複数のオブジェクト間で属性値が共通な共通属性を抽出し、類似度判定部140が第1のオブジェクトと第2のグループに属する第3のオブジェクトとの類似度を判定し、類似度が所定以上であった場合に分類部150が第1のオブジェクトと第3のオブジェクトを同一のグループに分類し、提示部160が分類結果を表示するようにした。
(もっと読む)
文書分類装置及びプログラム
【課題】 より分類精度の高い文書分類を可能にする。
【解決手段】 本発明は、正解文書から処理対象となる全ての対象単語に関して、制限無単語クラス間関連度を算出する。正解文書から処理対象となるいくつかの対象単語について、条件単語制限付単語クラス間関連度を算出する(事前処理)。処理対象となる文書が入力されると、入力文書に含まれる単語群の各単語について、該単語群と制限無単語クラス間関連度と条件単語制限付単語クラス間関連度とから、単語クラス間関連度を算出し、入力文書に含まれる単語群の各単語の出現頻度と該単語の重要度との積、あるいは、頻度と重要度に関して単調増加な演算結果である重みと、該入力文書に関する単語クラス間関連度とから、文書クラス間関連度を算出し、文書クラス間関連度と事前確率を用いて、入力文書が属するクラスを決定する(分類処理)。
(もっと読む)
コンテンツ推奨装置およびその動作方法
【課題】流行に影響されにくいユーザに視聴される多様なコンテンツを推奨する。
【解決手段】コンテンツ推奨装置1は、流行影響度並びにユーザIDを含む流行影響度情報が記憶される流行影響度情報記憶部15と、ユーザ間の類似度を含む類似度情報が記憶される類似度情報記憶部16と、対象ユーザの流行影響度より低い流行影響度を含む流行影響度情報を検索し、ユーザIDを読み出すユーザID検索部17と、そのユーザIDを含む類似度情報を検索し、類似度を高く補正する類似度補正部18と、全類似度を該類似度の高さにより2分した場合の高い方に属する類似度を含む類似度情報を類似度情報記憶部16から検索し、その中のユーザIDのユーザにより視聴されたコンテンツのコンテンツIDをコンテンツID取得部11を介して取得する推奨コンテンツID取得制御部19とを備える。
(もっと読む)
情報分析装置及び方法及びプログラム
【課題】 特定分野に対する特徴把握のため、特定分野に関連する1つ以上の分野限定単語を活用して有効な分類を行う。
【解決手段】 本発明は、クエリログからクエリリストを作成し、クエリリストから分野限定単語リストに記載の特定分野に関する単語を含んでおり、その単語と共起する単語を対象単語として対象単語リストを作成し、クエリリストから1単語の頻度の高い順に並べた結果を単語データとして作成し、クエリリストから任意の2単語とその共起頻度を並べた結果を単語共起頻度データとし、対象単語リストの単語と単語データの単語との共起頻度を単語共起頻度データから求め、対象単語に対し、単語データの各単語を要素とする統計量のベクトルを作成し、単語ベクトルデータから、各対象単語のベクトルの類似度を基に所定の条件を満たすまでクラスタリングを実施して、単語グループを作成する。
(もっと読む)
検索システム
【課題】不特定の分野のデータを対象として要素値が所定の範囲内にあることを好むようなユーザの嗜好に対応し、同一セグメント又は同族の他のユーザの嗜好を考慮することができるような検索システムを提供すること。
【解決手段】データを表示させたユーザにそのユーザの判断に基づく要素値を入力させ、多くのユーザが入力した要素値に基づいてデータの要素値を準備することで、各種の要素値についての客観性を持ったデータを保持する。このデータに基づいて、ユーザの嗜好に合うようなデータが高得点になるように得点を計算し、得点に基づいた表示を行う。また、ユーザと同一セグメント又は同族の他のユーザの嗜好を考慮した得点の計算を行う。
(もっと読む)
情報処理装置、情報処理システム、情報処理プログラム、情報処理プログラムを記録したコンピュータ読み取り可能な記録媒体、及び情報処理方法
【課題】シリーズ作品群を特定できる情報処理装置、情報処理システム、情報処理プログラム、情報処理プログラムを記録したコンピュータ読み取り可能な記録媒体、及び情報処理方法を提供する。
【解決手段】情報処理装置100は、作品名を表す作品名情報を複数記憶する情報記憶部111wと、作品名情報のそれぞれに対し、作品を説明する説明文を表すコンテンツ情報を取得するコンテンツ情報取得部111cとを備える。また情報処理装置100は、取得された複数のコンテンツ情報を、それぞれのコンテンツ情報で表される説明文が類似する程度を表す類似度に基づいて、複数のコンテンツ群に分類するコンテンツ情報分類部121を備える。さらに、情報処理装置100は、同じコンテンツ群に分類された複数のコンテンツ情報の説明文でそれぞれ説明される作品が構成する作品群をシリーズ作品群と特定するシリーズ作品群特定部122を備える。
(もっと読む)
カラオケ装置および認証システム
【課題】ある登録済ユーザに対応する楽曲のパラメータが変更されている場合であっても、その楽曲に基づくユーザの認証を正しく行えるようにする。
【解決手段】あるユーザに対応づけられた楽曲データで示される楽曲のパラメータが変更されていたとしても、端末装置2から再生出力された楽曲に基づくユーザの認証に先立って、ユーザと対応づけられた楽曲データで示される楽曲それぞれのパラメータが元に戻される(s530)。その結果、端末装置2からユーザに対応する楽曲を再生出力させた場合に、この楽曲が、パラメータの変更されていない状態の同一楽曲と比較されることとなるため、ユーザの認証を正しく行えるようになる。
(もっと読む)
画像検索装置、画像検索方法及びプログラム
【課題】クエリ画像の有する特徴的な領域に注視した高精度の類似画像検索を実現すること。
【解決手段】クエリ画像内の部分画像と類似する検索対象画像内の部分画像を含む領域を切り出して、この領域とクエリ画像との間で類似度を算出する。また、この類似度には、領域内に含まれる部分画像の数と、該領域内の部分画像のうちのクエリ画像から抽出した部分画像と類似する部分画像の数との比が重み付けされるため、クエリ画像と類似する部分画像に注視した類似度が算出される。
(もっと読む)
情報処理装置、情報処理システム、情報処理プログラム、情報処理プログラムを記録したコンピュータ読み取り可能な記録媒体、及び情報処理方法
【課題】ユーザの嗜好に合致した作品を特定できる情報処理装置、情報処理システム、情報処理プログラム、情報処理プログラムを記録したコンピュータ読み取り可能な記録媒体、及び情報処理方法を提供する。
【解決手段】情報処理装置100は、第1ユーザを識別するユーザ識別情報と、第1ユーザが提供される作品の作品名を表す作品名情報とを対応付けて記憶するとともに、第2ユーザのユーザ識別情報と、第2ユーザが提供される作品の作品名情報と、作品の特徴を表す作品特徴情報とを対応付けて記憶する情報記憶部150を備える。また、情報処理装置100は、第1ユーザが提供される作品と、第2ユーザが提供される作品とが同一の作品である場合に、第2ユーザの嗜好に合致する作品の作品特徴情報に対応付けられた作品名情報で表される作品名の作品を、第1ユーザの嗜好に合致する作品であると特定する嗜好作品特定部132を備える。
(もっと読む)
サジェスチョンクエリ抽出装置及び方法、並びにプログラム
【課題】ジェネリックパターンの存在に起因して生ずる意味ドリフトを抑制し、サジェスチョンクエリの抽出の精度の向上を図ること。
【解決手段】インスタンスパターン行列生成部62のうち、正規化自己相互情報量演算部71は、インスタンスパターン行列の各要素毎に、正規化自己相互情報量を演算する。エッジカット部72は、正規化自己相互情報量の値が閾値th以下である要素のエッジを削除する。正規化ラプラシアン行列演算部63は、このようなインスタンスパターン行列生成部62によって生成されたインスタンスパターン行列を用いて、正規化ラプラシアン行列を演算し、カーネルとして正規化ラプラシアン行列保持部43に保持させる。
(もっと読む)
マイクロブログテキスト分類装置及び方法及びプログラム
【課題】 利用者が与える任意の指定文字列に関連するか否かをにより入力テキスト(マイクロブログテキスト)を分類する。
【解決手段】 本発明は、入力テキストに指定文字列が含まれるか否かを判定し、指定テキスト記憶手段に格納されているテキスト集合を連結した指定連結テキストと、該指定連結テキストと入力テキストを連結したテキストと、比較テキスト記憶手段に格納されているテキスト集合を連結した比較連結テキストと、該比較連結テキストと該入力テキストを連結したテキストを連結テキスト記憶手段に出力し、連結テキスト記憶手段に格納されている連結したテキストをそれぞれデータ圧縮し、圧縮後のデータサイズを求め、これを基に、入力テキストの、指定文字列への関連スコアを求めスコア出力手段の関連スコアに基づいて、入力テキストを指定文字列に関連するか否かを分類する。
(もっと読む)
同一の共有コンテンツに興味を持つ視聴者の属性の観点を推定する最適観点推定プログラム、装置及び方法
【課題】同一の共有コンテンツに興味を持つ他の視聴者の属性の観点を推定すると共に、その観点に基づいて視聴者属性を推定するプログラム等を提供する。
【解決手段】ツリー状の観点及び属性単語を含む観点リストを記憶した観点リスト記憶手段と、各属性単語に関連する多数の学習文章情報を記憶した学習文章情報記憶手段とを有する。また、共有コンテンツから複数のキーワードを抽出する。次に、共有コンテンツについて、キーワードを要素とし且つその出現頻度を値とする第1のベクトルを導出し、キーワード毎に、当該キーワードと一致する属性単語における学習文章情報について、当該学習文章情報に含まれる単語を要素とし且つその出現頻度を値とする第2のベクトルを導出する。両ベクトルの類似度を算出し、類似度を対応付けた類似度付き観点リストを生成し、観点リストのレイヤ毎に、類似度の分散が最も大きい観点及び属性単語を導出する。
(もっと読む)
情報処理装置、電子メールの返信文抽出方法、及びそのプログラム
【課題】受信したメール本文に対する最適な検索範囲を設定し、返信文候補の抽出精度を上げることで、メール機能の利便性を高める。
【解決手段】電子メール作成機能を備えた情報処理装置であって、受信したメール本文を分割機能部(8)で複数の部分文字列に分割する。1又は連続する複数の部分文字列の全てに対して、記憶部(12)を参照し、一致し又は最も類似する受信文候補を受信文として選択する。記憶部は、1又は連続する複数の部分文字列に対応する受信文候補と、受信文候補に関連付けた返信文情報を記憶する。そして、分割した全ての部分文字列が連続し、且つ、前記メール本文に対して最も類似する受信文の組み合わせを検索範囲に設定し、この検索範囲に基づいて、記憶部に記憶した受信文に対応する返信文情報を抽出する。
(もっと読む)
81 - 100 / 1,166
[ Back to top ]