
Fターム[5B080CA05]の内容
Fターム[5B080CA05]の下位に属するFターム
ビットブロック転送 (6)
Fターム[5B080CA05]に分類される特許
21 - 40 / 70
描画制御装置
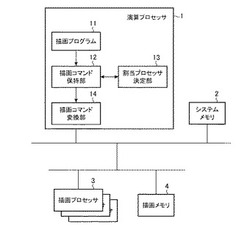
【課題】描画プログラムから発行される描画コマンドの種類に偏りが生じても、現在使用されていないハードウェアリソースを有効に活用して、高速に描画処理を実施することができるようにする。
【解決手段】複数の描画プロセッサ3の負荷状況を判定し、その負荷状況と描画コマンド保持部12により保持されている描画コマンドの種類に応じて、その描画コマンドを割り当てる描画プロセッサ3を決定する割当プロセッサ決定部13を設け、割当プロセッサ決定部13により決定された描画プロセッサ3が、本来、その描画コマンドを処理する描画プロセッサではない場合、その描画コマンドを上記描画プロセッサ3が対応可能な描画コマンドに変換する。
(もっと読む)
テクスチャ情報をコード化するための方法および装置

【課題】ピクセルに対するピクセル値が、記憶しているテクセル値から生成され、そのピクセルを生成したピクセル値に応じて表示させる。
【解決手段】ピクセルが、第1のテクセル基準値、第2のテクセル基準値、および第1のテクセル基準値、第2のテクセル基準値およびそれにより1つのテクセル・ブロックを表すための第3のテクセル基準値の3個からなる集合にテクセルをマッピングするために動作するテクセル値を記憶することによりテクスチャリングされる。他の実施形態の場合には、あるピクセルに対する第1のミップマップ値が、一組の最も近い隣接するテクセルに対する検索したテクセル値から二線補間される。ピクセルに対する第2のミップマップ値は、一組の最も近い隣接するテクセルに対する検索したテクセル値を平均することによって生成される。ピクセルに対するピクセル値は、第1および第2のミップマップ値の間で補間を行うことにより生成される。
(もっと読む)
画像処理方法、画像処理装置、および画像処理システム
【課題】3次元オブジェクトのレンダリング処理を柔軟性や互換性を保ちながら、並列処理により高速化することは難しかった。
【解決手段】オブジェクト記憶部52はオブジェクトの3次元データと、オブジェクトの占有する空間領域を包含するB−boxの配列データとを記憶する。分類部44はオブジェクト記憶部52からB−box配列を読み込み、オブジェクトの属性やLOD情報にもとづいてB−boxをグループに分類する。描画処理部46は、同一グループに属するB−boxを包含するブリックを算出し、ブリックごとに独立した描画処理を行って画像データを生成し、画像記憶部54に格納する。統合部48は、画像記憶部54に格納されたブリックごとの画像データを統合して最終的に表示すべき出力画像データを生成する。
(もっと読む)
単一パステセレーション
【課題】 テセレーションシェーダープログラムを実行するための改良されたシステム及び方法を提供する。
【解決手段】 グラフィックプロセッサを通して単一パスでテセレーションを実行するシステム及び方法は、グラフィックプロセッサ内の処理リソースを、異なるテセレーションオペレーションを実行するためのセットへと分割する。頂点データ及びテセレーションパラメータは、メモリに記憶されるのではなく、1つの処理リソースから別の処理リソースへ直接ルーティングされる。それ故、表面パッチ記述がグラフィックプロセッサに与えられ、そしてメモリに中間データを記憶せずに、グラフィックプロセッサを通して単一の非中断パスでテセレーションが完了される。
(もっと読む)
画像処理装置
【課題】低コストで処理性能を向上することができる画像処理装置を提供すること。
【解決手段】画像処理装置100は、ビデオ入力部140と描画部150とビデオ出力部160がアクセスするバンクを複数のフレームメモリ120,130に分けて割り当て、ビデオ入力部140と描画部150とビデオ出力部160といったマスタ部からのアクセス要求を調停し、それぞれのフレームメモリ120,130に複数のマスタ部が並行にアクセスできるようにデータ転送を制御するメモリコントローラ部190を備える。
(もっと読む)
画像処理システム
【課題】転送元メモリからの素材のロード回数を減らして全体的な転送時間の短縮を図りつつ、転送処理間における調停を可能にする。
【解決手段】素材の転送過程で複数種の処理が併存し、素材の特性に応じて処理を使い分ける画像処理システムにおいて、ディスプレイリスト解析部2bは、ディスプレイリスト10を解析して、それぞれの素材の転送命令を順次出力する。転送処理部2c〜2eは、ディスプレイリスト解析部2bからの転送命令によって自己が指定された場合、転送命令に係る素材の取得要求を出力する。この取得要求を管理する調停部5は、取得要求に係る素材がキャッシュメモリ4に格納されているか否かを判定し、必要に応じて、取得要求に係る素材をNANDメモリ3からキャッシュメモリ4にロードする。
(もっと読む)
混合精度命令実行を伴うプログラマブルストリーミングプロセッサ
本開示は、異なる実行ユニットを使用して、混合精度(例えば完全精度、半精度)命令を実行することが可能なプログラマブルストリーミングプロセッサに関する。様々な実行ユニットは、それぞれがグラフィックスデータを使用して指定の精度レベルで命令を実行することが可能である。例示的なプログラマブルシェーダプロセッサは、コントローラと、複数の実行ユニットとを含む。コントローラは、実行のための命令を受け取り、命令の実行に対するデータ精度の指示を受け取るために構成されている。コントローラは、また、実行されると、命令に関連付けられたグラフィックスデータを、示されたデータ精度に変換する個別の変換命令を受け取るために構成されている。実施可能な場合、コントローラは、示されたデータ精度に基づいて実行ユニットのうちの1つを選択する。コントローラは、その後、選択された実行ユニットに、命令に関連付けられたグラフィックスデータを用いて、示されたデータ精度で命令を実行させる。 (もっと読む)
仮想参照ビュー
様々な実装について記載する。幾つかの実装は仮想参照ビューに関する。一態様によれば、第1のビュー画像についての符号化情報にアクセスする。第1のビューとは異なる仮想ビュー位置からの第1のビュー画像を表す参照画像にアクセスする。参照画像は第1のビューと第2のビューとの間の位置についての合成画像に基づいている。参照画像に基づいて符号化された第2のビュー画像についての符号化情報にアクセスする。第2のビュー画像が復号される。別の態様によれば、第1のビュー画像にアクセスする。第1のビュー位置とは異なる仮想ビュー位置についての仮想画像が第1のビュー画像に基づいて合成される。第2のビュー画像は仮想画像に基づいて参照画像を使用して符号化される。第2のビューは仮想ビュー位置とは異なる。符号化は符号化された第2のビュー画像を生成する。 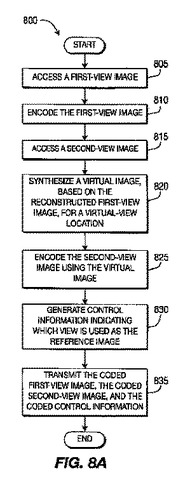 (もっと読む)
(もっと読む)
グラフィック遠隔化アーキテクチャ
リモートクライアントにおいて、グラフィック画像をレンダリングするためのグラフィック遠隔化アーキテクチャを実装するシステム及び方法が開示される。一実装において、リモートサーバー上にホストされるD3Dアプリケーションがリモートクライアントによって使用されるとき、D3Dアプリケーションに関連付けられたグラフィックが、リモートクライアントにおいて生成され、レンダリングされる。これに関連し、グラフィックに対応するD3Dコマンド及びD3Dオブジェクトが、リモートサーバーにおいて、データストリームの中に抽象化される。データストリームが、その後、リモートクライアントに送信される。リモートクライアントにおいて、D3Dコマンド及びD3Dオブジェクトが、データストリームから抽出され、実行され、グラフィック画像を生成する。グラフィック画像は、その後、リモートクライアントにおいてレンダリングされ、出力装置を使用し表示される。 (もっと読む)
一般作業負荷およびグラフィックス作業負荷を処理するための統合プロセッサアーキテクチャ
1つ以上の制御ユニットと、複数の第1の実行ユニットと、1つ以上の第2の実行ユニットとを備えるプロセッサである。プロセッサ命令セットに適合するフェッチされた命令が、第1の実行ユニットに送られる。第2の命令セット(プロセッサ命令セットとは異なる)に適合するフェッチされた命令が、第2の実行ユニットに送られる。第2の実行ユニットは、グラフィックス演算を実行するように構成され、またはJavaバイトコード、マネージドコード、ビデオ/オーディオ処理演算、暗号化/復号化演算などの実行のような他の特殊な機能を実行するように構成されてもよい。第2の実行ユニットは、コプロセッサのように動作するように構成されてもよい。単一の制御ユニットが、すべての実行ユニットに対するフェッチ、デコード、およびスケジューリングを処理してもよい。他の形態として、マルチ制御ユニットが、実行ユニットの異なるサブセットを処理してもよい。 (もっと読む)
複数のグラフィックサブシステムおよび低電力消費モードを有するコンピューティングデバイス用ドライバアーキテクチャ、ソフトウェアおよび方法
現在、多くのコンピューティングデバイスが2つ以上のグラフィックサブシステムを備えることがある。複数のグラフィックサブシステムは、能力が異なり、電力消費量が異なることがあり、例えば、あるサブシステムが別のサブシステムよりも多くの平均電力を消費することがある。電力消費の高いグラフィックサブシステムがデバイスに結合されて、低電力消費グラフィックサブシステムの代わりに、またはこれに追加して使用されることがあるが、性能向上と付加の能力が得られるが、全体的な電力消費が増大してしまう。電力消費の高いグラフィックサブシステムを低電力消費モードに設定しつつ、電力消費の高いグラフィックサブシステムの使用から低電力消費グラフィックサブシステムへ切り替えることによって、全体的な電力消費が低減される。プロセッサがアプリケーションソフトウェアおよびドライバソフトウェアを実行する。前記ドライバソフトウェアは、前記第1のグラフィックサブシステムの動作を制御する第1のドライバコンポーネントと、前記第2のグラフィックサブシステムの動作を制御する第2のドライバコンポーネントとを含む。第1のグラフィックシステムおよび第2のグラフィックシステムのいずれが使用中であるかに応じて、別のプロキシドライバコンポーネントが、第1のドライバコンポーネントおよび第2のドライバコンポーネントのいずれかにコール(例えばAPI/DDIコール)を転送する。  (もっと読む)
(もっと読む)
タイルベース・レンダリング・システムにおけるマルチコアの形状処理
多数の独立型タイルベース・グラフィック・コアを組み合わせるための方法及び装置が提供される。入ってくる形状ストリームは、複数のストリームに分割され、それぞれのタイルベースのグラフィックス処理コアに送られる。それぞれが別個のタイリングされた形状リストを生成する。これらは、マスター・タイリング・ユニットに組み合わせることができ、或いは代替的に、マーカーをタイリングされた形状リストに挿入することもでき、このマーカーがラスター化段階で用いられ、異なる形状処理コアからのタイリング・リスト間で切り替えを行なう。 (もっと読む)
グラフィックス・システムにおける可変長の圧縮と関連付けのための方式
無線デバイスは、可変長について、第1のレベルのコンパイラ圧縮処理と、第2のレベルのハードウェア圧縮処理とを実行する。コンパイラ圧縮処理は、その成分の合計がMである2つ以上のシェーダ変数(可変長と属性)を、共有M次元(MD)ベクトル・レジスタに圧縮する。ハードウェア圧縮は、頂点キャッシュまたは他の記憶媒体に、シェーダ変数(可変長と属性)のM個の成分と任意の残りの変数を、連続的に圧縮する。  (もっと読む)
(もっと読む)
アプリケーションの変更前にコマンドの変更のパフォーマンスを解析するためのグラフィックコマンド管理ツールおよびその方法
アプリケーションのためにビデオフレームレンダリング特性の最適化を可能にする方法、システム、グラフィカルコンピュータインタフェース、および計算機可読媒体が開示される。前記方法は、ビデオフレームをレンダリングするステップと、前記ビデオフレームの前記レンダリングを表すプッシュバッファ設定をキャプチャするステップと、を有する。また、前記方法は、前記アプリケーションをバイパスすることにより前記プッシュバッファ設定のアスペクトを変更するステップと、前記変更されたアスペクトにより前記フレームを再レンダリングするステップと、も有する。更に、前記方法は、前記レンダリングを前記再レンダリングと比較するステップと、比較結果を提示するステップと、を有する。アプリケーションのコードを変更せずに、パフォーマンス、レンダリングおよび処理の効率に関して、可能な変更の、アプリケーションに対する寄与を評価するための機能を可能にするグラフィカルユーザインタフェースが提供される。 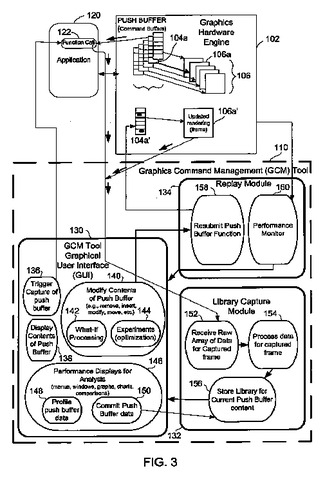 (もっと読む)
(もっと読む)
マルチテクスチャリングのための動的に構成可能なテクスチャキャッシュ
テクスチャキャッシュを動的に構成するための技術を開示する。三次元(3D)グラフィックスパイプラインのテクスチャマッピング処理の間に、バッチがシングルテクスチャマッピングに対するものである場合には、テクスチャキャッシュは、nウェイのセットアソシエイティブテクスチャキャッシュとして構成される。しかしながら、バッチがマルチテクスチャマッピングに対するものである場合には、nウェイのセットアソシエイティブテクスチャキャッシュは、1組のM個のn/Mウェイのセットアソシエイティブサブキャッシュへと分割され、ここで、nとMは1より大きい整数であり、nはMによって割り切れる。 (もっと読む)
3次元製品提供システム
【課題】印刷のレイアウトが限定されることなく所望の情報を3次元形状物に印刷する。
【解決手段】選択された印刷情報を3次元形状物のうち指定された領域に配置する印刷情報配置部23において、印刷情報を配置する領域として、3次元形状物のうち複数面に跨る領域が指定された場合、選択された印刷情報を、その印刷情報が指定された複数面に跨って印刷されるように配置し、また、複数面のそれぞれに沿うように立体表示する。
(もっと読む)
電子回路、電子機器、プロジェクタ、画像生成方法
【課題】コストを抑制しつつ、高速に画像の合成を行うことが可能な電子回路等を提供すること。
【解決手段】電子回路100が、画像データを記憶するメモリ130と、画像合成用の演算を行う演算回路140と、画像データの少なくとも一部を読み込んで演算回路140に転送するCPU110とを含んで構成され、演算回路140が、CPUによって転送された画像データに基づき、画像合成用の演算を行って合成データを生成し、CPU110が、当該合成データをメモリ130に転送するように構成される。
(もっと読む)
画像処理システム及び画像処理方法
【課題】GPUの負荷のバランスがとれ、且つ消費電力及び回路面積の増大が抑制された画像処理システム及び画像処理方法を提供する。
【解決手段】グラフィックデータ処理により、複数の描画コマンドを生成するソフトウェアを実行する中央演算処理装置(CPU)10と、複数の描画コマンドで描画処理を行って、複数に分割された画面の各領域の画像描画用データを並列に生成するGPU21及びGPU22とを備え、GPU21及びGPU22が、対象とする各領域を互いに動的に変更する。
(もっと読む)
マルチグラフィックスプロセッサシステム、グラフィックスプロセッサおよびデータ転送方法
【課題】マルチグラフィックスシステムにおいてデータ転送の効率化を図ることが必要である。
【解決手段】マルチグラフィックスプロセッサシステム400は、CPU300と、CPU300と入出力インタフェース180を介して接続された第1GPU100と、第1GPU100に第2GPU用インタフェース140を介して接続された第2GPU200とを含む。第1GPU100内に、CPU300が第2GPU用インタフェース140を経由して第2GPU200と通信するための第2GPU用バス170が設けられる。CPU300は、第1GPU100内の第2GPU用バス170を経由して第2GPU200とデータ通信を行う際、データ通信のタイミングを通知するための信号の受信を待ってから、データ通信を行う。
(もっと読む)
グラフィックスプロセッサの複数のディスプレイヘッドを用いたアンチエイリアシング
【課題】1つのグラフィックスプロセッサの複数のディスプレイヘッドを利用してアンチエイリアシングおよび他の処理タスクを行うシステムおよび方法を提供する。
【解決手段】同じグラフィックスプロセッサの2つのディスプレイヘッドが、画素転送パスを介してマスター/スレーブ形式で互いに結合されている。「マスター」ディスプレイヘッドは、それ自体の画素に加えて「スレーブ」ディスプレイヘッドから画素を受け取り、マスターディスプレイヘッド中の画素選択論理回路がこの2画素を混合するか、いずれか一方を選択して他方を除外する。2画素が同じ画像の異なるサンプリング位置に対応する場合には、混合した画素がアンチエイリアシング処理画素となる。
(もっと読む)
21 - 40 / 70
[ Back to top ]