
Fターム[5B005KK13]の内容
階層構造のメモリシステム (9,317) | 適用環境 (907) | 要求元 (807) | CPU (641) | マルチCPU (447)
Fターム[5B005KK13]の下位に属するFターム
共有外部メモリを有するもの (262)
Fターム[5B005KK13]に分類される特許
21 - 40 / 185
情報処理装置、情報処理方法、半導体集積回路、及びストリーム再生システム

【課題】マルチスレッド実行制御方式でデータ処理を行う情報処理装置は、スレッドプライベート宣言された変数の全てが必ずしも利用されるわけではないため、結果的に、スレッド用に確保された領域への書き込み動作のうちの一部の動作が無駄になってしまう場合がある。
【解決手段】スレッド1で利用されるスレッドプライベート変数に対応付けられた第1論理アドレスで指定される領域と、その変数に対応するスレッド2で利用されるスレッドプライベート変数に対応付けられた第2論理アドレスで指定される領域とは、いずれかのスレッドプライベート変数への書き込みが行われるまでは、共通の第1物理アドレスで指定される領域を利用し、いずれかのスレッドプライベート変数への書き込みが行われた後は、それぞれ、第1物理アドレスで指定される領域と第2物理アドレスで指定される領域とを利用する。
(もっと読む)
共有メモリシステム及びその制御方法

【課題】処理時間の短縮及び消費電力の低減が可能な共有メモリシステムを提供すること。
【解決手段】共有メモリシステムは、アクセス監視機構112に対し、動画属性用のクラスタをクラスタメモリ1、2とする定義を行う。アクセス監視機構112は、DSP(2)104が画像の属性情報を付加してメモリアクセスを行うと、クラスタメモリ1、2に対してアクセス許可を示す制御情報131をクラスタメモリ空間選択装置119に出力する。クラスタメモリ空間選択装置119は、制御情報131に従って、DSP(2)104からのアクセスをクラスタメモリ1もしくは2に振り分ける。GPU105からのアクセスも同様である。複数のクラスタ111に分割された共有メモリ110を複数のマスタが共有することで、キャッシュメモリのコヒーレンシを保つ。
(もっと読む)
キャッシュコントローラ及びその制御方法
【課題】キャッシュコントローラ内のキャッシュデータを破棄する際、プロセッサによる処理の負荷を軽減することができるキャッシュコントローラを提供する。
【解決手段】マスタからのアクセスが無効化範囲設定部121の条件に合致すると判定された場合、キャッシュコントローラ110は、無効化判定回路120及びタグメモリ改変部122により、タグメモリ111内の該当するアドレスのVALIDフラグ113を強制的にリセットする。これにより、VALIDフラグがリセットされた、該当するアドレスのキャッシュデータはメモリ104に書き戻されることなく破棄される。そして、マスタによってアクセスされるデータが該当するアドレスに従って上書きされる。
(もっと読む)
DMAセキュリティチェック回路及びDMAセキュリティチェック方法
【課題】IO TLB(I/O Translation Look aside Buffer)でキャッシュミスした場合にDMAが待たされることを防止する。
【解決手段】IOV(I/O Virtualization) HBA(Host Bus Adapter)に対応したDMA(Direct Memory Access)セキュリティチェック回路が、HBAからのDMAリード要求に対しディスクリプタフェッチを検知した場合に、当該DMAリード要求のリプライデータの中から抽出した論理アドレスと、当該リプライデータに含まれるリクエストIDとが同じゲスト空間のものであるかを判定し、同じゲスト空間のものである場合に当該リプライデータに含まれるアドレスが適切であると判断する。
(もっと読む)
仮想アドレスキャッシュメモリ、プロセッサ及びマルチプロセッサシステム
【課題】TLBの機能をキャッシュメモリ上で実現して、回路量の削減を図ることができ、さらにタスク切り替えの応答性が向上したプロセッサを提供する。
【解決手段】仮想アドレスキャッシュメモリは、TLBの書き換えが発生したときにエントリデータの書き換えを行うTLB仮想ページメモリ21と、仮想ページタグ又はページオフセットをキャッシュインデックスとしてキャッシュデータを保持するデータメモリ23と、キャッシュインデックスに対応して前記データメモリに記憶された前記キャッシュデータのキャッシュステートを保持するキャッシュステートメモリ24と、TLBの書き換えが発生したときに、保持している物理アドレスの書き換えを行う第1の物理アドレスメモリ22と、TLBの書き換えの発生後、データメモリへの前記キャッシュデータを書き込むときに保持している物理アドレスの書き換えを行う第2の物理アドレスメモリ25とを有する。
(もっと読む)
メモリ管理装置
【課題】不揮発性半導体メモリをメインメモリとする場合において、キャッシュメモリのヒット率を向上することが可能なメモリ管理装置を提供する。
【解決手段】不揮発性半導体メモリ(9,10)は、データを記憶する。揮発性半導体メモリ(8)は、複数の領域を含み、少なくとも一部が不揮発性半導体メモリのキャッシュメモリとして用いられる。制御部(1)は、不揮発性半導体メモリ又は揮発性半導体メモリに書き込まれるデータの特性に基づいて生成され、データの不揮発性半導体メモリ又は揮発性半導体メモリ上の配置領域を決定するヒントとなる配置ヒント情報に基づき、揮発性半導体メモリの複数の領域からデータの配置領域を決定する。
(もっと読む)
仮想化処理システムにおけるアドレスマッピング
アドレススヌープ方法及びマルチプロセッサシステム
【課題】本発明は、アドレススヌープ方法及びマルチプロセッサシステムに関し、多数のI/Oブロックをプロセッサブロックから独立させてマルチプロセッサシステムに容易に実装可能とすると共に、マルチプロセッサシステムの性能の上限の低下(レイテンシの増加)を防止可能とすることを目的とする。
【解決手段】複数のプロセッサと複数のメモリからなるプロセッサブロックが複数個アドレス結合装置を介して複数のI/Oブロックと接続された構成のマルチプロセッサシステムにおけるアドレススヌープ方法において、任意の1つのプロセッサブロックからアクセスリクエストが発生したときに、前記アクセスリクエストに対して応答するか否かを判断するアドレススヌープ処理を、各I/Oブロックに代わって前記アドレス結合装置において行うように構成する。
(もっと読む)
マルチプロセッサシステム
【課題】プロセッサが動作停止状態に移行した場合、キャッシュデータの一貫性を保持しつつ、キャッシュメモリの消費電力を削減できる。
【解決手段】第1及び第2のプロセッサ101、111と、共有メモリ123と、第1及び第2のキャッシュメモリ102、112と、第1及び第2のキャッシュメモリが記憶しているデータの一貫性を管理する一貫性管理回路120と、一貫性管理回路から第1及び第2のキャッシュメモリに対して、データ更新を要求する要求信号を伝達するための要求信号線SCOPと、第1及び第2のキャッシュメモリから一貫性管理回路に対して、データ更新が完了したことを通知する通知信号を伝達するための通知信号線SCCOREREADYと、要求信号と通知信号とに応じて、第1及び第2のキャッシュメモリへのクロック信号及び電源の供給を制御するキャッシュ電力制御回路103、113と、を備えるマルチプロセッサシステム。
(もっと読む)
マルチコアプロセッサアーキテクチャにおけるデータ記憶およびアクセス
キャッシュに記憶されたデータブロックを送るためのシステムに関する技術が一般に記載されている。本明細書中に記載される幾つかの実施例では、システムが第1のタイルの第1のプロセッサを備えてもよい。第1のプロセッサは、データブロックの要求を発生させるのに有効であり、前記要求がデータブロックのための宛先タイルを識別する宛先識別子を含み、宛先タイルが第1のタイルと異なる。幾つかの実施例のシステムは、要求を受けるのに有効な第2のタイルを更に備えてもよく、第2のタイルは、データブロックを含むデータタイルを決定するのに有効であるとともに、要求をデータタイルへ送るのに有効である。幾つかの実施例のシステムは、第2のタイルから要求を受けるのに有効なデータタイルを更に備えてもよく、データタイルはデータブロックを宛先タイルへ送るのに有効である。  (もっと読む)
(もっと読む)
情報処理装置
【課題】キャッシュメモリからメインメモリへのデータの書き戻し時間を短縮することができる情報処理装置を提供する。
【解決手段】 情報処理装置1は、キャッシュメモリ7,8を有するコア2,3が内蔵されたマルチコアCPU4と、マルチコアCPU4と接続されたDRAM6とを備えている。キャッシュメモリ7,8には、キャッシュデータを含む情報と当該情報をコア2,3の何れに移動させるかを示すバランス情報とがキャッシュライン毎に記憶されている。マルチコアCPU4は、バランス情報を参照してキャッシュメモリ7,8のキャッシュ使用量を平均化するようにキャッシュメモリ7,8間で情報を移動させるキャッシュバランス制御部13と、その情報の移動が行われた後に、キャッシュメモリ7,8に記憶されたキャッシュデータをDRAM6に書き戻すキャッシュ書き戻し制御部14とを有している。
(もっと読む)
ドメインベースのキャッシュ・コヒーレンス・プロトコル
簡単にいうと、ドメインベースのキャッシュ・コヒーレンス・プロトコルを用いてキャッシュ内のデータブロックにアクセスするための技術が概説される。第1のタイル、第1のドメインの第1のプロセッサはデータブロックにアクセスするよう求める要求を評価するように構成することができる。第1のドメインの第2のタイルのキャッシュは、データブロックが第2のタイルにキャッシュされているときに、第1のタイルにデータブロックを送るように構成することができる。第1のプロセッサは、キャッシュされた位置が第1のプロセッサのドメインの外部にあるときに、別のドメインの第3のタイルに要求を送るように構成することができる。第3のプロセッサは、データブロックのキャッシュされた位置と関連付けられたデータドメインを判定し、そこに要求を送るように構成することができる。第4のタイルは、要求を受け取り、第1のタイルにデータブロックを送るように構成することができる。  (もっと読む)
(もっと読む)
バッファリングストアを利用してトランザクションを高速化するための機構
一実施例では、本発明は、第1スレッドにおいてトランザクショナルメモリ(TM)トランザクションを実行し、プロセッサのキャッシュメモリの第1バッファにデータのブロックをバッファリングし、第1バッファのブロックの位置におけるデータが更新されるエンカウンタタイムにブロックのオーナシップを取得するため、ブロックに対してライトモニタを取得する方法を含む。他の実施例が、開示及び請求される。 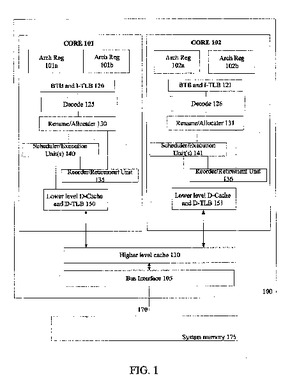 (もっと読む)
(もっと読む)
動的なシステムの再構成
【解決手段】 一部の実施形態によると、複数のプロセッサコアを含むシステムの動的ハードウェア再構成を実行するために用いられるシステム再構成用のコードおよびデータをキャッシュして、動的ハードウェア再構成の間、直接メモリアクセスまたは間接メモリアクセスを禁止する。複数のプロセッサコアのうち一のプロセッサコアが、キャッシュされたシステム再構成用のコードおよびデータを実行して、ハードウェアを動的に再構成する。他の実施形態も説明および請求している。 (もっと読む)
キャッシュメモリにおけるキャッシュラインの置き換え
【課題】キャッシュメモリにおけるキャッシュラインの置き換えを改善し、必要とするデータが利用不可能となる可能性が生じ、データの取得に長いレイテンシが生じるのを防ぐ。
【解決手段】タグフィールドをそれぞれ持つ複数のキャッシュラインを含むキャッシュメモリを備え、タグフィールドは、ラインに記憶されたデータのキャッシュコヒーレンシステートを記憶するステート部分と、前記データの相対的重要度に応じたウェイトを記憶するウェイト部分とを含み、ウェイトは、キャッシュコヒーレンシステート及びデータ使用の最新性に基づく。
(もっと読む)
バッファを用いて高効率でロード処理を実行する方法および装置
【課題】高い電力効率および時間効率でロードを処理する方法および装置を提供する。
【解決手段】コンパイラは、プロデューサーロード、コンシューマー再利用ロード、コンシューマー転送ロード、および、プロデューサー/コンシューマハイブリッドロードを特定する。この特定結果に基づき、ロードの実行をロード値バッファ、ストアバッファ、データキャッシュ等に指示することによって高効率化を図る。このような構成とすることによって、ロード値バッファおよびストアバッファから直接ロードさせることによってキャッシュに対するアクセスを低減し、ロードの処理を高効率化する。
(もっと読む)
データ処理装置
【課題】2次キャッシュにおけるキャッシュヒット率を向上させることが可能なデータ処理装置を提供すること。
【解決手段】L2制御部32は、タグメモリ34を参照して、1次キャッシュ12および22のいずれかからの要求データがデータメモリ33に格納されていると判断した場合、データメモリ33から当該データを読み出して要求があった1次キャッシュに出力し、タグメモリ34に格納される当該データに対応するタグ情報の追い出し優先順位を所定よりも高い値に設定する。したがって、2次キャッシュ31にそのデータがしばらく残ることになり、複数のCPUが同じデータに対して集中してアクセスするような場合であっても、2次キャッシュ31におけるキャッシュヒット率が低下するのを防止することが可能となる。
(もっと読む)
情報処理装置及び情報処理装置のデータキャッシング方法並びにマルチプロセッサシステム
【課題】メモリ装置を共有する複数プロセッサからなるシステムで、プリフェッチ命令によるキャッシュ機構の効果が、メモリ装置への競合アクセスに起因して無効となることを、簡単な回路構成で防止すること。
【解決手段】通常必要とするキャッシュ22以外に、メモリ装置から返却されたリプライデータを一定期間保持するためのプリキャッシュ23をキャッシュ22の前段に設け、Snoop命令は、既成の情報処理装置と同じく、キャッシュ22に対してのみ実行可能とし、プリキャッシュ23は該命令の実行対象外とする。キャッシュのエントリフルによるSwap-out処理も、キャッシュ22からのみ実行されるものとする。プロセッサ2のCore21から発行される命令に対しては、プリキャッシュ23もキャッシュ22の一部としてリード及びライトを可能とする。プリキャッシュ23内に保存したデータは、一定期間保持した後、キャッシュ22に移動させる。
(もっと読む)
スレッド移送におけるキャッシュのプレフィル
スレッドを第1のコアから第2のコアに移送する前に、第2のコアに関連するキャッシュをプレフィルするための技法が、全般的に開示される。本開示は、一部のコンピュータシステムが複数のプロセッサコアを有することがあり、スレッドを適切なコアに割り当てるために一部のコアが別のコアとは異なるハードウェア能力を有することがあり、スレッド/コアのマッピングを利用することがあり、いくつかの場合にはスレッドがあるコアから別のコアに再割り当てされ得ることを考慮する。スレッドが第1のコアから第2のコアに移送され得るという確率的な予測では、第2のコアに関連するキャッシュがプレフィルされ得る(例えば、スレッドが第2のコアで再スケジュールされる前に何らかのデータでフィルされ得る)。そのようなキャッシュは、例えば、第2のコアへのローカルキャッシュおよび/または関連するバッファキャッシュであってよい。  (もっと読む)
(もっと読む)
処理ユニットのローカルメモリ読み出し
【解決手段】
処理ユニットのローカルメモリに対する効率的な読み出しを可能にするためのシステム、装置及び方法がここに開示される。ある実施形態においては、処理ユニットは、インタフェース及びバッファを含む。インタフェースは、(i)他の処理ユニットのローカルメモリの領域におけるデータの一部分に対する要求を送ると共に(ii)要求に応答して領域からの全てのデータを受信するように構成される。バッファは、他の処理ユニットのローカルメモリの領域からのデータを記憶するように構成される。
(もっと読む)
21 - 40 / 185
[ Back to top ]