
Fターム[5B057CH02]の内容
画像処理 (340,757) | 処理部 処理装置、処理システム (15,018) | 演算器 (6,373) | マルチプロセサ (674)
Fターム[5B057CH02]の下位に属するFターム
Fターム[5B057CH02]に分類される特許
81 - 100 / 245
画像処理装置及び画像処理システム

【課題】処理負荷が高い画像処理であっても、処理性能を高めることが可能な画像処理技術を提供する。
【解決手段】OCRアプリは、画像処理装置がマスタ機となる場合、OCR処理を複数のジョブに細分化し、細分化したジョブを実行させる画像処理装置をケイパビリティ情報に基づいて選定する。そして、OCRアプリは、選定した画像処理装置のOCRエンジンを起動させてOCR処理を実行させ、処理後に、当該OCRエンジンを停止させる。また、OCRアプリは、画像処理装置がスレーブ機となる場合、マスタ機からの要求に応じてOCR処理を実行し、当該OCR処理の結果をマスタ機に送信する。
(もっと読む)
再構成可能モジュールと、モルフォロジー演算を実行するために同モジュールを実施する方法
本発明は、モルフォロジー演算を画像処理に対し実行できるようにする再構成可能モジュールに関する。モジュールは、5入力(A,B,C,D,E)、3出力(S0,S1,S)、3つの加算器/減算器(add1,add2,add3)および4つの論理ブロック(muxA/B,muxD/E,muxE/S,muxABC)を含む演算ブロックを含む。論理ブロック(muxA/B,muxD/E,muxE/S,muxABC)は、出力(S0,S1,S)が5入力(A,B,C,D,E)に対し実行された基本演算(加算、減算、最小値、最大値)の結果を送出できるように3つの加算器/減算器(add1,add2,add3)間の様々な経路を提供する。本再構成可能モジュールは、部品数の低減と、様々なモルフォロジー演算(そのパラメーターは変更可能である)を実行可能にすること、とにより特徴付けられる。さらに、本再構成可能モジュールは、より複雑なモルフォロジー演算を実行するために直列結合可能である。本発明はまた、原画像を起点として原画像の積分画像、浸蝕画像、拡張画像、距離画像、または行と列に沿った投射を決定できるようにする再構成可能モジュールを実施する方法に関する。 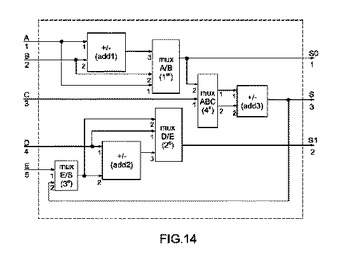 (もっと読む)
(もっと読む)
画像処理コントローラおよび画像処理装置

【課題】画素毎に階調表現した画像データを所定量ずつ連続処理する処理系に対し、所定転送速度のバスを介して前記画像データを入力する場合に、前記処理系の前段におけるデータ生成速度による前記処理系の処理速度に対する影響を防止しつつ、前記連続処理を遅滞させず、且つ前記処理系に入力される画像データの階調表現での不連続性を目立たなくする。
【解決手段】画像データDの各色下位所定数ビットを冗長化してそのビット数情報を画像データDに含ませ、冗長化後の画像データを圧縮してメモリに記録する圧縮部23と、RAM31に記録された画像データが所定量に達するとバス29を介して取得して伸張する伸張部24と、伸張後の画像データの下位所定数ビットを非冗長データに置換してPWM部に入力するスクリーン処理部25と、を具備する。
(もっと読む)
信号処理装置及び信号処理方法
【課題】 信号処理の処理内容に応じて、効率的に信号処理モジュール間のデータ転送を行う信号処理装置を提供する。
【解決手段】 信号処理を行なうための複数の信号処理モジュール1〜nと、信号処理モジュール間のデータ転送のための汎用バス21と、信号処理モジュール1〜n間におけるデータ転送を行なうための信号処理バス20とを備え、信号処理モジュール1〜nは、汎用バス21または信号処理バス20の選択回路11,15を有し、信号処理モジュール1〜nでの処理に応じて使用するバス20,21を選択して信号処理モジュール1〜n間の接続を行なう。
(もっと読む)
画像処理装置及びプログラム
【課題】ページ記述言語データが、使用する変換処理系に応じて変換結果のラスター画像に差異が出るようなものであるか否かを検証するための装置を提供する。
【解決手段】画像処理装置100は、ページ記述言語データをラスター画像データに変換する互いに異なる複数の変換処理系A,B,Cに検査対象のページ記述言語データをそれぞれ変換させる制御を行う検査制御部102と、各変換処理系A,B,Cの変換結果のラスター画像データ同士の間に差異がある場合に、差異情報を出力する差異検出部116とを備える。
(もっと読む)
SIMD型マイクロプロセッサ
【課題】回路規模やレイアウト規模を増大させることなく、また、データ転送時の処理能力の低下を起こすことなく、より多くの画像データを高速に同時処理することができるSIMD型マイクロプロセッサを提供する。
【解決手段】PE内のローカルレジスタ書き込みバスB1、ローカルレジスタ読み出しバスB2を、2ポートレジスタまたはPE間接続バスB6、B7を介して隣接するPE内のALU入力バスB3、隣接するPEのALU出力バスB4に接続し、PE内のALU入力バスB3、ALU出力バスB4を、PE間接続バスB6、B7を介して隣接するPE内のローカルレジスタ書き込みバスB1、ローカルレジスタ読み出しバスに接続し、GP部2が、2ポートレジスタ4とPEアレイ部3とのデータ転送の際にこれらのバスを経由するように経路を切替える。
(もっと読む)
GPUシーン構成およびアニメーション
グラフィックス処理ユニット(GPU)上で完全に実行することができる形式でシーン構成およびアニメーションを表すアーキテクチャー。このアーキテクチャーは、保持グラフ情報(例えばシーングラフ情報およびアニメーション情報)をテクスチャー情報として記憶し、(例えば頂点およびピクセル)シェーダーを使用して時間情報を評価し、アニメーションを評価し、変形を評価し、パスをラスタライズする。さらに、このアーキテクチャーは、プリミティブごとにCPUが介入することなく、もっぱらGPU上でアニメーションの位置を計算し、再描画する能力を提供する。 (もっと読む)
コプロセッサの性能を強化するシステムおよび方法
【課題】コプロセッサ長時間停止状態を最小にすると同時に他のスケジューリング効率を可能にすることによってコプロセッサの性能を強化するシステムおよび方法を提供すること。
【解決手段】コプロセッサ「長時間停止状態」を最小にする技法、およびより高い効率および威力のためにコプロセッサ内の処理の効果的なスケジューリングの技法。実行リストが設けられて、コプロセッサが、CPU介入を待たずにあるタスクから別のタスクに切り替えられるようになる。「サーフェスフォールト」と称する方法によって、コプロセッサが、タスクの途中の場所ではなく、大きいタスクの初めにフォールトを発生できるようになる。DMA制御命令すなわち「フェンス」、「トラップ」、および「コンテキスト切り替え許可/禁止」を処理ストリームに挿入して、コプロセッサに、コプロセッサの効率および威力を強化するタスクを実行させることができる。
(もっと読む)
複数のハードウェア・ドメイン、データ・タイプ、およびフォーマットの処理を統合し抽象化するフレームワーク
【課題】メディア・オブジェクトを処理するためのポータブルな開発および実行フレームワークの提供。
【解決手段】フレームワークは、メディア処理機能を実行する命令を受け入れ、メディア処理機能と関連付けるメディア・オブジェクトを受け入れ、メディア・オブジェクトのタイプおよびフォーマットを指定する属性と、メディア・オブジェクトと関連付けられたハードウェア・ドメインでメディア・オブジェクトをラップし、メディア・オブジェクト上においてメディア処理機能を実行ドメインに遂行させることを含む。メディア処理機能を実行する命令は、メディア・オブジェクトと関連付けられたハードウェア・ドメインには依存しない形態で表現され、メディア・オブジェクトのタイプおよびフォーマットにも依存しないこともできる。メディア・オブジェクトは、画像とすることができ、メディア処理機能は、GPU上で実行する画像処理機能を含むことができる。
(もっと読む)
動画像処理方法、プログラム、及び装置
【課題】簡単な構成でOSの機能に大きく依存することなく、デコード処理を効率的且つ円滑に行うことができる動画像処理方法、プログラム、及び、装置を提供する。
【解決手段】動画像のフレームを、複数の処理部の個数の倍数ではない個数の複数のスライスに分割するステップと、複数のスライスの各々に割り当てられて、複数のスライスの各々を処理する処理ステップと、処理ステップにおいて、処理するスライスを切り替えるスライス・スイッチングを実行するスイッチング・ステップと、を実行する、複数の処理部を用いて動画像を処理する方法を提供する。本方法によると動画像の処理に限らず、処理部を複数用いて処理を行う場合、スライスの数が処理部の個数の整数倍ではない個数であっても、簡単な構成でOSの機能に大きく依存することなく、効率的に処理を実行できる。
(もっと読む)
ローカル及びグローバルのデータ共有
【解決手段】
1つ以上のSIMD処理ユニットと、1つ以上のSIMD処理ユニットに対応するローカルデータシェアとを有するプロセッサと、グローバルデータシェアとを有するグラフィックス処理ユニットが開示されており、ローカルデータシェアは、1つ以上の実行ウエーブフロントに割り当てられた複数スレッドの各群のための1つ以上の小さい待ち時間のアクセス可能なメモリ領域を備えており、グローバルデータシェアは、スレッドの各群のための1つ以上の小さい待ち時間のメモリ領域を備えている。
(もっと読む)
画像処理方法及び画像処理装置とその制御方法
【課題】 複数のプロセッサに対して適切な負荷分散を実現することによって、入力される画像データの傾向に依存せず高速に画像処理可能な画像処理方法及び画像処理装置とその制御方法を提供する。
【解決手段】 1つの画像領域の画像処理を複数のプロセッサで分担して行う画像処理装置で、入力される前記画像領域でのピクセル情報の重ね合わせの傾向を解析し、解析結果に基づいて、複数のプロセッサで行う処理の分担を決定し、決定した処理の分担に従って、複数のプロセッサへの処理の分担を制御する。例えば、重ね合わせる各レイヤのピクセル情報の生成処理を行う第1プロセッサと、生成したピクセル情報を重ね合わせる第2プロセッサである場合に、重ね合わせ処理の有無や、重ねあわせ処理の複雑度や、重ねあわせ処理を行う領域の広さを解析し、第1プロセッサと第2プロセッサの処理の分担や通信方法を制御する。
(もっと読む)
画像処理方法、画像処理プログラム、および画像処理装置
【課題】ページ画像データの作成に必要な合成処理をより効率的に並列化することにより、合成処理時間の短縮化を図ることができる画像処理方法、画像処理プログラム、および画像処理装置を提供する。
【解決手段】複数の処理部を有する画像処理装置としてのプリンタコントローラは、複数のオブジェクトに対し、重なりのある複数のオブジェクトを1つのグループとし且つ他のオブジェクトと重ならない単独のオブジェクトを1つのグループとするグループ分けを行う(S103)。そして、プリンタコントローラは、グループ分けで得られた複数のグループの各々について描画面積を算出し、算出された各グループの描画面積に基づいて、複数のグループを複数の処理部による並列処理数に振り分ける(S104)。
(もっと読む)
ハードウェア方式のベクターグラフィックアクセラレータ
【課題】
本発明は、アプリケーションプロセッサにおいてオープンベクターグラフィックの各パイプラインをハードウェアで設計することにより、ベクターグラフィック処理の実行性能を高め、また、標準として制定されたOpenVG APIを支援することにより、従来にソフトウェアレンダリング処理で使用していたOpenVGベクターコンテンツを別途の変換なしに使用できるハードウェア方式のベクターグラフィックアクセラレータ、そのアクセラレータを含むアプリケーションプロセッサ、及びそのプロセッサにおいてグラフィック加速方法を提供する。
【解決手段】
ハードウェアグラフィックアクセラレータは、制御部と連結されて動作するグラフィック処理モジュールを含む。前記グラフィック処理モジュールは、前記制御部から受けた一つ以上の命令語に従って2Dベクターグラフィック加速を行うために、パイプライン構造によって共に連結されるラスタライズセットアップモジュール、シザーテストモジュール、ペイントジェネレーションモジュール、アルファマスクモジュール及びブレンディングモジュールのうち少なくとも一つを含む。
(もっと読む)
描画コマンド生成装置、描画処理装置、描画コマンド生成方法および描画処理方法
【課題】無駄サイクルの発生を抑えて、高速な描画処理を実現するための描画コマンド生成処理と提供すること。
【解決手段】描画コマンド生成装置100は、 図形の特徴をあらわす属性情報と、当該属性情報を反映した図形を描画するための描画コマンドとが対応付けて書き込み可能なテンプレートが属性の種類に応じて用意されたテンプレート群111に対して、それぞれ任意の属性情報と当該属性情報に対応した描画コマンドを書き込む。そして、比較器112によって描画対象図形系1の入力データ101の属性情報とテンプレート群111の各テンプレートに記録された属性情報とをそれぞれ比較して、一致した属性情報を出力する。コマンド構築器112では、比較器112によって出力された属性情報が記録されたテンプレートから描画コマンドを読み出して、描画対象図形を描画させるための描画コマンドを構築し、出力データ102として出力する。
(もっと読む)
積和演算回路
【課題】固定サイズの正方行列だけではなく、異なる行列サイズの積和演算を連続実行でき、さらに回路の利用効率および演算性能を向上させることを目的とする。
【解決手段】第1の行列の行ベクトルと、第2の行列の列ベクトルとの積算を並列に実行する所定数の乗算器と、所定の要素数と同じ数量設けられた乗算器の次段に、乗算器の乗算結果を取得して加算をする乗算器用加算器と、乗算器用加算器の次段に、乗算器用加算器の加算結果を取得して加算をする加算器用加算器と、最終段の加算器用加算器のレイテンシを計測するレイテンシカウンタと、レイテンシカウンタが最終段の加算器用加算器のレイテンシを計測するごとにカウントして、所定の累算回数までカウントすると行列積の演算結果が取得可能状態であることを示す信号を出力する可変カウンタと、可変カウンタのカウント値の設定をする可変カウンタ設定部と、を備える積和演算回路である。
(もっと読む)
情報処理装置、及び画像処理装置
【課題】 処理対象の情報を各処理単位毎にその処理負荷に対応可能な処理能力を有するプロセッサに割当てることで、省電力化を図りながら処理効率を高める。
【解決手段】 画像処理装置の制御部101において、処理負荷予測部133は、クライアント端末からの印刷ジョブに含まれる各頁毎の処理負荷情報に基づき、演算係数管理部131が管理する各プロセッサの処理能力に対応する演算係数を用いて各頁毎に各プロセッサの処理能力別の予測処理負荷を算出する。処理割当制御部134は、算出された各プロセッサの処理能力別の予測処理負荷と、処理負荷閾値管理部132が管理する各プロセッサの処理能力別の処理負荷閾値とに基づき、算出された予測処理負荷に対応可能な処理能力を有するプロセッサに当該各頁の処理を割当てて該処理を実行させる。
(もっと読む)
演算処理ユニット及びその制御方法
【課題】性質の異なる第1演算処理装置と第2演算処理装置とにより構成された演算処理ユニットにおいて、処理の高速化を図る。
【解決手段】演算処理ユニットは、逐次処理に適した演算器で構成された、第1演算処理装置と、大量の単純計算処理に適した演算器で構成された1又は複数の第2演算処理装置と、複数の処理工程に分割された第1特定処理と第2特定処理を実行するにあたり、前記第1特定処理における逐次処理を主とした1つの処理工程を、前記第1演算処理装置で実行している間に、前記第2特定処理における単純計算処理を主とした別の処理工程を、前記第2演算処理装置で実行するように制御する、制御手段と、を備えるとともに、前記第1特定処理及び前記第2特定処理の分割された各処理工程は、それぞれの処理時間が、同程度になるように分割されている。
(もっと読む)
画像処理方法
【課題】入力画像中における連結画素成分に対するラベリング処理を高速に実行可能な画像処理方法を提供する。
【解決手段】ラベリング処理を1次元SIMD型プロセッサおよび汎用プロセッサを用いて行う画像処理方法であって、1次元SIMD型プロセッサの複数のプロセッサエレメント(PE)に対して、入力画像30の画素配列32における行方向または列方向の複数の画素ライン(PL)を並列に割当て、各PL上での画素成分同士の連結関係を判定し、各PL上の連結画素ブロック(ブロック)毎に、画素配列上での開始位置および終了位置を示す位置情報を取得する第1の仮ラベリング処理と、汎用プロセッサを用いて、位置情報に基づいて、隣接するPL間でのブロック同士の連結関係を判定し、ブロック毎に、画素配列上での開始位置にある画素成分に連結関係に基づく仮ラベルを付する第2の仮ラベリング処理と、を含む。
(もっと読む)
宣言型プレゼンテーション・フレームワークのためのシェーダーベースの拡張
シェーダーを宣言的に制御するための様々な技術及び技法が開示される。宣言型のプログラミング・モデルは、宣言型プレゼンテーション・フレームワークにおいてシェーダーのインスタンス化を制御する宣言文が使用されることを可能にする。宣言的に指定されたシェーダーベースの効果は、ソフトウェア・アプリケーションに対してグラフィック効果をレンダリングするためにプログラムによって例示化される。ソフトウェア・アプリケーションに対してグラフィック効果カスタマイゼーションをシェーダーがレンダリングすることを可能にするために、宣言文はシェーダー・プロセッサーへ送信される。本方法はまた、複数パス動作中に実行されるべき1組のシェーダーを制御しカプセル化する複数パス効果として宣言型のプログラミング・モデルを利用するために記述される。  (もっと読む)
(もっと読む)
81 - 100 / 245
[ Back to top ]