
国際特許分類[G10L15/00]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声認識 (6,879)
国際特許分類[G10L15/00]の下位に属する分類
音声認識のための特徴抽出;認識単位の選択 (203)
セグメンテーション,または語区切れ検出 (272)
標準パタンの作成;音声認識システムの学習,例.話者適応 (725)
音声の識別または探索 (1,500)
不利な環境に特に適した音声認識技術,例.雑音またはアクセントのある音声 (334)
音声認識処理中の手順,例.マン・マシン対話 (884)
音響以外の特徴を用いる音声認識,例.唇の位置 (190)
音声をテキストに変換するシステム (3)
音声認識システムの構造上の細部 (875)
国際特許分類[G10L15/00]に分類される特許
1,871 - 1,880 / 1,893
ダイアログシステムの駆動方法
本発明は、音声信号を処理する音声インタフェースを有するダイアログシステムを駆動する方法を記載する。本方法は、予想される音声入力信号の特性を推定し、当該特性に従って音声インタフェース制御パラメータを生成する。音声インタフェースの動作は、この音声インタフェース制御パラメータに基づき最適化される。さらに本発明は、音声インタフェースと、ダイアログ制御ユニットと、予想される音声入力信号の特性を推定する予測モジュールと、前記特性に基づき音声入力制御パラメータを生成することにより、前記音声インタフェースの動作を最適化する音声最適化装置とを有することを特徴とするダイアログシステムを記載する。 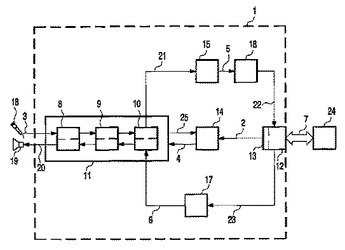 (もっと読む)
(もっと読む)
対話プロセス制御方法
現在状況パラメータが自動決定され、対話プロセスの制御が、現在状況に対話プロセスが適応されるように状況パラメータに基づき実行される対話プロセス制御方法が説明される。  (もっと読む)
(もっと読む)
VXMLコンプライアントボイスアプリケーションと対話する発呼者の行為特徴を識別するための行為適応エンジン
ボイスアプリケーション創出および配置システムが統合された行為適応エンジンが、データに添付された音声ファイルを含むXMLベースクライアント対話データを受信するための少なくとも1つのデータ入力ポートと、外部データシステムおよびモジュールにデータを受信し、かつそれからデータを受信するための少なくとも1つのデータポートと、受信されたデータを処理するためのXML読取装置、ボイスプレーヤ、および分析装置を含む論理処理構成要素と、1つまたは複数の制約に対して結果データを処理するための決定論理構成要素とを有する。エンジンは、提供されるボイスアプリケーションとのクライアント対話からのダイアログを含むクライアントデータを実時間で傍受し、行為パターン、および添付されていれば音声ファイルのボイス特徴について受信データを処理し、その際に、エンジンは、結果および1つまたは複数の有効な制約に従って、対話中にクライアントに戻される可能な企業応答の1つまたはセットを識別する。 (もっと読む)
ネットワーク装置でセキュリティモードに入る方法
本発明は、データ処理装置(2)の無線ネットワーク(10)における通信を確保するために、特に共通鍵のようなセキュリティコードを入力する方法に関する。音声記録ユニット(3、6)は、オーディオデータの形式でユーザ(1)により発声されたパスフレーズを記録する。音声分析ユニット(4)は、検索セキュリティコードを表す音素又は音素のグループにオーディオデータを再分割する。  (もっと読む)
(もっと読む)
キャッシュ機能を有する分散音声認識システムおよび方法
音声入力(404)は、格納(416)するために受け取られて処理される(406−414)。結果モデルは、セルラ電話機のような通信装置での使用のために送信されうる(418)。認識された音声は、ネットワークにおける幾つかの望まれる動作を遂行するために使用されうる(420)。  (もっと読む)
(もっと読む)
ハンドヘルド携帯装置のための音声入力メソッド・エディタのアーキテクチャ
【課題】 携帯情報端末などのハンドヘルド携帯装置に用いる音声入力メソッド・エディタのためのアーキテクチャ及び方法を提供する。
【解決手段】 音声入力メソッド・エディタは、少なくともマイクロフォン状態/トグル・ボタン(104)を有する音声ツールバー(102)を含むことができる。音声入力メソッド・エディタはまた、口述テキストがターゲット・アプリケーションに転送されるまで一時的口述ターゲットとして用いられる選択可能な口述ウィンドウ領域(108)と、口述された単語を訂正するための代替候補リスト(120)、アルファベット(114)、スペースバー(116)、スペル・モード・リマインダ(118)、又は仮想キーボード(122)のうちの少なくとも1つを有する選択可能な訂正ウィンドウ領域(112)とを含むことができる。音声入力メソッド・エディタは、選択可能な訂正ウィンドウ領域を使用し、かつ、口述テキストをターゲット・アプリケーションに転送している間、作動状態のままとすることができる。音声入力メソッド・エディタはさらに、音声入力メソッド・エディタを使用している間、口述ウィンドウ領域又はターゲット・アプリケーションの少なくとも1つにおいて非音声編集を可能にするのに用いられる代替入力メソッド・エディタ・ウィンドウ(112b)を含むことができる。
(もっと読む)
音声制御ナビゲーションシステムの操作方法
地理的基準(GK)を考慮して自動的に進行される対話において入力要求(P)が生成されてユーザーに向けて出力され、前記ユーザーによって話された応答(S)が検出される、音声制御ナビゲーションシステム(1)を操作する方法が記載される。音声応答(S)は前記地理的基準(GK)を考慮に入れて自動音声認識法を使って位置データの認識のために解析される。さらに、対応するナビゲーションシステム用音声データユーザーインターフェースが記載される。 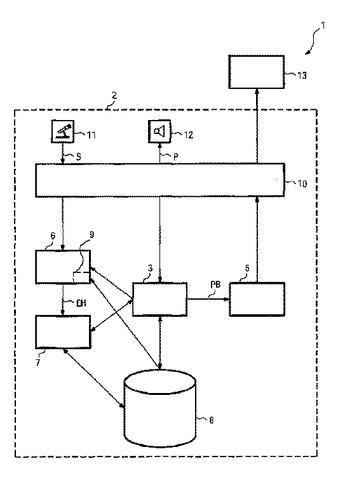 (もっと読む)
(もっと読む)
音声信号の復元装置及びコンピュータプログラム
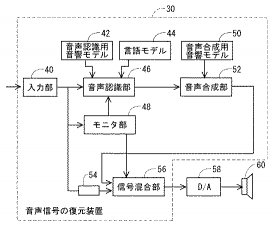
【課題】長い消失区間に対しても音声を復元する事ができる音声信号の復元装置を提供する。
【解決手段】音声信号の復元装置は、入力される音声信号データ列に消失区間があるか否かを判定し、判定結果を示す第1の信号を出力するモニタ部48と、音響モデル42と言語モデル44とを用いて音声認識を行なう音声認識部46と、音声認識部46の認識結果から音声合成を行なう音声合成部52と、モニタ部48により制御され,消失区間では音声合成部52の出力を、それ以外では入力音声データを、それぞれ選択する信号混合部56とを含む。
(もっと読む)
無線通信システムにおいてリンクを確立する方法および装置
音声認識辞書の作成方法及び音声認識辞書作成システム

【課題】ユーザの発声に整合するように発音データを蓄積した音声認識辞書を生成する。
【解決手段】辞書生成制御部5は、地名データベース1に蓄積された地名を表すテキストをスペル変換部3に供給する。スペル変換部3は、供給されたテキストのスペルを変換ルールテーブル2に記述されたルールに従って、”−”、”?”、”+”、”;”、”/”、”(”、”)”などの記号文字を” ”(スペース)に置き換えることにより変換し、TTSエンジン4に供給する。TTSエンジン4のテキスト解析部7は、テキストを解析しテキストを読み上げた音声を特定するための発音データ8を作成する。辞書生成制御部5は、TTSエンジン4で生成された発音データ8を読み込み、先に地名データベース1より読み込んだテキストと対応づけて音声認識辞書6に格納する。
(もっと読む)
1,871 - 1,880 / 1,893
[ Back to top ]