
Fターム[4B063QS03]の内容
酵素、微生物を含む測定、試験 (178,766) | 処理,操作 (34,251) | 試薬の作製,保存 (2,111) | 化学反応,酵素反応によるもの (2,024) | 標識,発色団等の導入 (974)
Fターム[4B063QS03]に分類される特許
841 - 860 / 974
高感受性エンドヌクレアーゼを生産する方法、新規なエンドヌクレアーゼ調製物、及びそれらの使用
本発明は、高感受性を有する組換えエンドヌクレアーゼを生産する方法、当該方法により得られるエンドヌクレアーゼ調製物、及び特にミスマッチの検出のためのそれらの使用に関する。
【配列表】
SEQUENCE LISTING
<110> GENOPLANTE-VALOR
INSTITUT NATIONAL DE LA RECHERCHE AGRONOMIQUE
BENDAHMANE, Abdelhafid
STURBOIS, Benedicte
TRIQUES, Karine
CABOCHE, Michel
<120> METHOD FOR PRODUCING HIGHLY SENSITIVE ENDONUCLEASES, NOVEL
PREPARATIONS OF ENDONUCLEASES AND USES THEREOF.
<130> MJP/bv1516-19
<150> PCT/EP2004/009159
<151> 2004-07-30
<150> PCT/EP2004/009166
<151> 2004-07-30
<160> 25
<170> PatentIn version 3.3
<210> 1
<211> 2640
<212> DNA
<213> Arabidopsis thaliana
<220>
<221> misc#feature
<223> ENDO 1 Gene At1g11190
<400> 1
aaattcgatg aggttgttat agacaagaga agacattttt atacaaaaga gtttatcatt 60
atataagttt caaactttga agatatggca tcggctttta gatcatccac gaggttgatt 120
cttgtattag gtatactgat tttgtgttcg gtttcttctg tccgaagctg gagcaaagaa 180
ggtcatattc ttacttgtag aattgctcag gtaattaagt taatgatcta ttgtttgaag 240
caactatttt ggttattctt gtcttatata tgtattagtg agatatacct acaaattttt 300
aattaggatt gacttttaaa ttgctatacg ttaccatgcc taacatctca tgtagatgat 360
catgaataca aacatgtcta atggcatatc aaattccaag tttttttggt agagatctga 420
gtcatttgac cgttataaga ttcataacaa aagttcgtat gtgtgtgttt ttgtggtgtg 480
accagaatct tttagaagcc ggaccagcac atgtagtaga gaatctgtta ccggattacg 540
tgaaaggaga tttatcagca ttgtgtgtgt ggcctgacca gatccgacat tggtacaagt 600
atcgttggac cagccatctc cattacatcg acactcccga ccaagcctgc tcttacgaat 660
actctagtaa gtcacaaccg agacattttc agataacctt aatccgtttt ctaattatct 720
tgaaccggag ttaaccaaaa aatcaattac aaataccaaa ccggattaaa aacaggggat 780
tgtcatgatc aacatggatt gaaggatatg tgtgtggatg gagcaatcca gaatttcacg 840
tctcagcttc agcattacgg tgaaggaaca tctgatcgta gatgtatgtc atcattttca 900
tttatttcat ataatgatga tatccaaagt gtaactgcgt attttgtatt ttgatgcata 960
acttaagttt ttaaaattat aatatatcct tgttcaatca catagataac atgaccgaag 1020
cccttttgtt cttgtctcat ttcatgggag atattcatca ggtttattac tcatcatcga 1080
ttcatttcac acctccacac atatagctct atttccatgt taaatattta attaacatgg 1140
tttttttttt tttccttaaa aagccgatgc atgtgggatt cacaagtgat gaaggaggaa 1200
acacgataga tttacgttgg tacaaacaca aatccaatct acatcatgta agcttcttct 1260
tttgtctctt tcaactttaa atttcatcat gaaaacaaaa aaaaaattaa cgaaggaaac 1320
aaaatatgta ggtatgggat agagagatca ttctcacggc tctaaaagaa aactacgaca 1380
agaacttgga tcttctccaa gaggatcttg agaagaacat caccaatgta atagacacta 1440
atttattcat attttactat aattttaaga atctttataa tggttatcat atattaggga 1500
ttatggcacg acgatctatc ttcgtggaca gaatgcaacg atcttatcgc ttgtccacac 1560
aagtaagttt taaattactt ggtttaagat tggcttgacg ctcgtttgaa gctagctaca 1620
aattttgata ctttttctgg tccaaaaatc ttacaaagat actgaaaata aaataatagg 1680
ttttaaactt ttaatttatt tggagttgga taggattaag tttcactaac ttccaattca 1740
aagtcaatta atagtagttt accatgatta gtgggttgac taatgtacca tatatattac 1800
cttatatcac atcttatttc cgatgtgaga tttcttatga aacataatta gactcgaacc 1860
ttttgtgttt cgatatatgt agtgtattca tgatcagaat cttattaagt ttacaactga 1920
aaactaaaat attaacatca taattataga ttcttaagta ggttttgttt gggtggagaa 1980
aatatccaat ttcgaataac attatataaa atattgaact aattttaatt gtatacgcag 2040
gtatgcttca gagagtataa agttagcttg taaatgggga tacaaaggcg tcaagtctgg 2100
tgaaacgtta tcaggtacgt tgtttgcttc ttctttttct cgtacgctaa caaaaatatt 2160
taaaaataaa cccgaccaaa tgaagtttaa ttaatcggat taatgatttt taatagtcac 2220
tacttttttt gtgtgggata tatgactgtc taatatataa ttttataaga aagctaaagg 2280
atttgtttaa taatttccga taaataattt tgcagaagaa tatttcaata caaggttgcc 2340
aatagtgatg aagagaatag ttcagggagg agttagacta gccatgatac taaaccgggt 2400
ttttagtgac gatcatgcta ttgctggtgt tgctgccact tgaaccaaac ccgacatacc 2460
ggggcatcaa agcatttgat taagagatta tttgatacat tcacaaaatt aattaaggct 2520
gatcagacat tcttttcttt tagtagcttt atctatgtga cagctaatgc ctgtggactg 2580
ctttgtttag aagtgtttag cattagatca tatgctaatt caatgttatt aattcatcgt 2640
<210> 2
<211> 305
<212> PRT
<213> Arabidopsis thaliana
<220>
<221> misc#feature
<223> Protein ENDO 1 At1g11190
<400> 2
Met Ala Ser Ala Phe Arg Ser Ser Thr Arg Leu Ile Leu Val Leu Gly
1 5 10 15
Ile Leu Ile Leu Cys Ser Val Ser Ser Val Arg Ser Trp Ser Lys Glu
20 25 30
Gly His Ile Leu Thr Cys Arg Ile Ala Gln Asn Leu Leu Glu Ala Gly
35 40 45
Pro Ala His Val Val Glu Asn Leu Leu Pro Asp Tyr Val Lys Gly Asp
50 55 60
Leu Ser Ala Leu Cys Val Trp Pro Asp Gln Ile Arg His Trp Tyr Lys
65 70 75 80
Tyr Arg Trp Thr Ser His Leu His Tyr Ile Asp Thr Pro Asp Gln Ala
85 90 95
Cys Ser Tyr Glu Tyr Ser Arg Asp Cys His Asp Gln His Gly Leu Lys
100 105 110
Asp Met Cys Val Asp Gly Ala Ile Gln Asn Phe Thr Ser Gln Leu Gln
115 120 125
His Tyr Gly Glu Gly Thr Ser Asp Arg Arg Tyr Asn Met Thr Glu Ala
130 135 140
Leu Leu Phe Leu Ser His Phe Met Gly Asp Ile His Gln Pro Met His
145 150 155 160
Val Gly Phe Thr Ser Asp Glu Gly Gly Asn Thr Ile Asp Leu Arg Trp
165 170 175
Tyr Lys His Lys Ser Asn Leu His His Val Trp Asp Arg Glu Ile Ile
180 185 190
Leu Thr Ala Leu Lys Glu Asn Tyr Asp Lys Asn Leu Asp Leu Leu Gln
195 200 205
Glu Asp Leu Glu Lys Asn Ile Thr Asn Gly Leu Trp His Asp Asp Leu
210 215 220
Ser Ser Trp Thr Glu Cys Asn Asp Leu Ile Ala Cys Pro His Lys Tyr
225 230 235 240
Ala Ser Glu Ser Ile Lys Leu Ala Cys Lys Trp Gly Tyr Lys Gly Val
245 250 255
Lys Ser Gly Glu Thr Leu Ser Glu Glu Tyr Phe Asn Thr Arg Leu Pro
260 265 270
Ile Val Met Lys Arg Ile Val Gln Gly Gly Val Arg Leu Ala Met Ile
275 280 285
Leu Asn Arg Val Phe Ser Asp Asp His Ala Ile Ala Gly Val Ala Ala
290 295 300
Thr
305
<210> 3
<211> 28
<212> DNA
<213> Artificial sequence
<220>
<223> Primer 4-960
<400> 3
gtgtttgtcc agtaatagtg tcagcata 28
<210> 4
<211> 26
<212> DNA
<213> Artificial sequence
<220>
<223> Primer 4-721
<400> 4
aggaacctga gaaaagactc gccagc 26
<210> 5
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> CEL N Terminal
<400> 5
tatcgttcta gagggaatga cgcgattata ttctgtgttc 40
<210> 6
<211> 27
<212> DNA
<213> Artificial sequence
<220>
<223> CEL C Terminal
<400> 6
tatctgaatt catgccaaag aatgatc 27
<210> 7
<211> 50
<212> DNA
<213> Artificial sequence
<220>
<223> CEL C terminal 8 His
<400> 7
aattcaatgg tgatggtggt gatggtgatg tgccaaagaa tgatctgcgg 50
<210> 8
<211> 25
<212> DNA
<213> Artificial sequence
<220>
<223> Primer (R21)
<400> 8
gacatatgga ctacagaagc ttggg 25
<210> 9
<211> 25
<212> DNA
<213> Artificial sequence
<220>
<223> Primer (R22)
<400> 9
gttcacgggt cacatcatgc attcc 25
<210> 10
<211> 22
<212> DNA
<213> Artificial sequence
<220>
<223> Primer 4m118
<400> 10
ttggttggac ttcactttga gc 22
<210> 11
<211> 22
<212> DNA
<213> Artificial sequence
<220>
<223> Primer 4m984
<400> 11
cacaacaatc agcaatgaca gc 22
<210> 12
<211> 23
<212> DNA
<213> Artificial sequence
<220>
<223> Primer 4-347
<400> 12
gtgattgctc cacctccgcc acc 23
<210> 13
<211> 30
<212> DNA
<213> Artificial sequence
<220>
<223> Primer 4-134
<400> 13
tacagcgatt gatataatat aaaattatcc 30
<210> 14
<211> 27
<212> DNA
<213> Artificial sequence
<220>
<223> Primer le 2462
<400> 14
tgatattgtc gtgcaatatg atgaaac 27
<210> 15
<211> 25
<212> DNA
<213> Artificial sequence
<220>
<223> Primer le 3082
<400> 15
atacctattt agcccacttg gacac 25
<210> 16
<211> 27
<212> DNA
<213> Artificial sequence
<220>
<223> Forward Primer for ENDO5
<400> 16
aaggatccga aagctctgtg tttcaga 27
<210> 17
<211> 28
<212> DNA
<213> Artificial sequence
<220>
<223> Reverse Primer for ENDO5
<400> 17
ggagttgtta cgtgggttct caaggatc 28
<210> 18
<211> 28
<212> DNA
<213> Artificial sequence
<220>
<223> Forward Primer for ENDO4
<400> 18
ctggatccct gtttttaact ttggaaag 28
<210> 19
<211> 26
<212> DNA
<213> Artificial sequence
<220>
<223> Reverse Primer for ENDO4
<400> 19
ggatgttcaa gtgattctcc tggatc 26
<210> 20
<211> 27
<212> DNA
<213> Artificial sequence
<220>
<223> Forward Primer for ENDO3
<400> 20
aaggatccat tcgacaaact ttgtaac 27
<210> 21
<211> 28
<212> DNA
<213> Artificial sequence
<220>
<223> Reverse Primer for ENDO3
<400> 21
agagtggtct tgggaatatt tatctcag 28
<210> 22
<211> 26
<212> DNA
<213> Artificial sequence
<220>
<223> Forward Primer for ENDO2
<400> 22
acggatccca tttcaaagaa ctctga 26
<210> 23
<211> 26
<212> DNA
<213> Artificial sequence
<220>
<223> Reverse Primer for ENDO2
<400> 23
gaccaatcat tatgctgtaa cttcag 26
<210> 24
<211> 25
<212> DNA
<213> Artificial sequence
<220>
<223> Forward Primer for ENDO1
<400> 24
caggatccaa gtttcaaact tgaag 25
<210> 25
<211> 26
<212> DNA
<213> Artificial sequence
<220>
<223> Reverse Primer for ENDO1
<400> 25
cggtatgtcg ggtttggttc aagtgg 26
(もっと読む)
タンパク質分解酵素の基質であって、細胞透過性蛍光発生性の基質及びカスパーゼ活性指標マーカーを用いた、細胞性細胞障害活性の可視化及び定量
本発明は、細胞障害性Tリンパ球(CTLs)によって活性化される標的細胞の殺傷をモニターし及び定量するための非放射性アッセイを提供する。本アッセイは、アポトーシス経路の活性化及び、特にカスパーゼの活性が、細胞障害性エフェクター細胞の活性の計測を与えるという発見に基づいて予想される。ある態様では、標的細胞におけるCTLが引き起こすカスパーゼの活性化の測定は、蛍光発生性のカスパーゼの基質を特異的に切断することの計測を通して達成される。本発明は、抗原特異的にCTLが標的細胞を殺傷することを確かに検出し、そしてCTL反応を定量するために最もよく使われる標準51Cr放出アッセイに代わるより感受性が高く、より情報価値が高く、及びより安全な代替方法を提供する。本アッセイは、異なる細胞系列の初期宿主標的細胞のCTL依存的殺傷を研究するために使われうるし、リアルタイムで細胞一つのレベルで抗原特異的細胞性免疫反応を研究することを可能にする。このように、本アッセイは、感染性疾患の病原の価値ある研究ツールを提供しうるし、新しいワクチン及び免疫療法の開発を提供しうる。 (もっと読む)
パニック病の遺伝学的検査方法
【課題】 発作型不安神経症はパニック不安神経症ともいうが、激しい不安が理由もなく突発し、死の恐怖に圧倒されて、なすすべを失ってしまうタイプで、神経症の中では−番劇的なタイプのパニック発作、パニック病と呼ばれる、一般人にとっては理解しにくい症状を呈する病を検査する方法を提供する。
【解決手段】 境界としてのD15S925(近位端)とD15S736(遠位端)とによって限定される15q24-25任意のゲノム配列の重複を使用すること、あるいは、ヒト染色体の重複領域である15q24-25内の任意のゲノム配列によってコードされる、又は15q24-25の重複の結果としてゲノムのその他の領域から発現されるポリペプチドの過剰発現されたタンパク質を使用することを特徴とする、家族性及び散発性に発症する場合を含む不安病及びその関連疾患、主に広場恐怖症、社会恐怖症、パニック発作およびパニック病の検査方法。
(もっと読む)
アルツハイマー病で使用するためのSrcキナーゼの阻害剤
本発明は、Srcキナーゼ阻害剤の同定、このような同定に有用な分析および方法、ならびに、アルツハイマー病を治療するための医薬を製造するためのSrc阻害剤の使用に関する。  (もっと読む)
(もっと読む)
薬物有害反応(ADR)および薬効を診断するための予測ツールとしての一塩基多型
本発明は、ヒト個体がスタチン治療後に薬物有害応答を受ける危険性あるかどうか、またはヒト個体がスタチンの高応答者、または低応答者か、または良い、もしくは悪い代謝体であるかどうかを決定する診断法、およびオリゴおよび/またはポリヌクレオチドまたは誘導体を含み、ならびに抗体を含むキットを提供する。さらに本発明は、ヒト個体が心血管疾患の危険性があるかどうかを決定する診断法および抗体を含むキットを提供する。さらに本発明は、多型配列および他の遺伝子を提供する。本発明はさらに、治療薬を同定する方法に有用で、そして心血管疾患を処置するか、または医薬剤応答に影響を与えるための薬剤の調製に有用である表現型関連(PA)遺伝子ポリペプチドをコードする単離されたポリヌクレオチドに関し、該ポリヌクレオチドは:PA遺伝子ポリペプチドに関する完全長のcDNAのような機能的周囲に含まれる、配列のセクションに示される対立遺伝子変異を含み、そしてPA遺伝子プロモーター配列を含むか、もしくは含まない配列番号1〜131を含む群から選択される。配列:配列セクションには、全ての表現型関連(PA)SNPおよび隣接するゲノム配列を含む。関連研究(baySNP)で使用した多型位置が示される。時々別の変異体が周辺ゲノム配列に見出され、各々ICUPACコードによってマークされる。それらの取囲んでいるSNPを明確に分析しなかったが、それらはbaySNPとして表現型と同様の関連性を示すようである(連鎖不均衡のため:Reich D.E. et al. Nature 411, 199-204. 2001)。 (もっと読む)
結合組織刺激ペプチド
【課題】 なし
【解決手段】
”PG”、”GP”、”PI”、及び”IG”からなる群から選択されたアミノ酸モチーフを含み、かつ該アミノ酸モチーフの上流域、及び/又は下流域に、10個までのアミノ酸を有し、ここで、該モチーフの”P”は、プロリン、又はヒドロキシプロリンであり、かつ骨、軟骨、及び付随する結合組織の成長、維持、及び修復を刺激する、新規ペプチドを記述する。本発明は、さらに、これらのペプチドの医薬組成物、並びにこのようなペプチドの治療上、及び予防上の使用に関するものである。
(もっと読む)
RNA安定化剤ならびにこのRNA安定化剤を用いたRNA安定化方法および複合体安定化方法
【課題】 生体内外に関わらず、RNAの立体構造を安定化させるRNA安定化剤およびRNA安定化方法を提供する。また、生体内外に関わらず、RNAとRNAとの結合能を有する分子とからなる複合体を安定化させる複合体安定化方法を提供する。さらに、RNAを生体内において追跡可能なRNAトレーサーおよびRNA追跡方法を提供する。
【解決手段】 4級ポリアミンを有効成分とするRNA安定化剤を、RNAおよび複合体に結合させる。また、4級ポリアミンを安定同位体元素により標識したRNAトレーサーをRNAに結合させて、このRNAトレーサーを検出する。
(もっと読む)
トリ組織サンプル中のウイルスの検出用アッセイ方法

クロライドチャンネル伝導性を測定する方法
本発明は、機能性クロライドチャンネルについてアッセイするための非放射性方法を提供する。該方法はクロライドチャンネルにより伝導されるヨウ化物の量を比色分析で検出する。それらはハイスループットアッセイもしくはスクリーニングに容易に適応することができる。 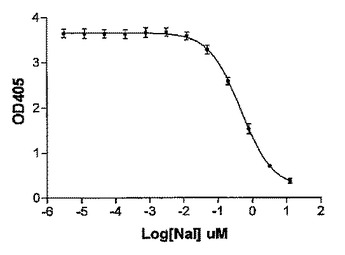 (もっと読む)
(もっと読む)
塩基多型の同定方法
【課題】 煩雑な操作を必要としないので、迅速で容易に再現性の良い結果が得られる、塩基多型を明確にまた簡便に検出できる方法を提供する。
【解決手段】 特定の核酸配列を含む試料溶液にオリゴヌクレオチドを用いた増幅反応と同時およびまたは増幅反応後、該核酸配列に特異的に結合する第一のリガンドが結合したオリゴヌクレオチドおよび第二のリガンドが結合した塩基多型領域を特異的に認識するオリゴヌクレオチドを接触させ、塩基多型を検出する方法において、上記第二のリガンドの補捉剤が結合された固相担体および、上記第一のリガンドに結合する標識された生理活性物質を用いることを特徴とする塩基多型の同定方法。
(もっと読む)
核形態型に基づく幹細胞を同定するための方法
幹細胞ならびに胚形成および発癌に特異的な他の細胞を同定し、組織試料を分類し、前癌および癌またはアテローム硬化症病変を診断し、制癌剤の価値を検査し、特定の細胞型で特異的に発現される高分子を発見し、回復組織療法において幹細胞を使用する方法、ならびに異形性核形態型がインタクトであるように組織試料を調製する方法が、開示される。  (もっと読む)
(もっと読む)
塩基多型の同定方法
【課題】 迅速で容易に再現性の良い結果が得られる、塩基多型を明確にまた簡便に検出できる方法を提供。
【解決手段】 特定の核酸配列を含む試料溶液に第一のリガンドが結合した該特定核酸配列増幅用オリゴヌクレオチドを用いて、増幅反応後、第二のリガンドが結合された結合体を接触させ、特定の核酸配列と結合した第二のリガンド結合体との複合体を検出することによって塩基多型を同定する方法において、上記第一のリガンドの補捉剤が結合された通液性フィルターに滴下して、該複合体の第一のリガンド部分を、該リガンド補捉剤に結合させる工程;該通液性フィルターの表面に、上記第二のリガンドに結合する、標識された生理活性物質の溶液を滴下して、この標識を持つ生理活性物質を、第一のリガンド補捉剤とリガンド部分とを介して通液性フィルターに結合している第二のリガンドに結合させる工程;通液性フィルターに結合した標識を測定する工程、からなる塩基多型の同定方法。
(もっと読む)
IGFR経路のモディファイヤーとしてのP4HAsおよび使用方法
ヒトP4HA遺伝子はIGFR経路のモジュレーターとして同定されており、したがってこれらは欠陥IGFR機能に関連する疾患の治療上の標的である。P4HAの活性を調節する作用剤をスクリーニングすることを含む、IGFRのモジュレーターを同定する方法が提供される。 (もっと読む)
新規抗原結合ポリペプチド及びそれらの使用
新規抗原結合ポリペプチド(ABP)及びそれらの使用を提供する。 (もっと読む)
西ナイルウィルスを検出するための、組成物および方法
本発明の第1の態様は、核酸検出用のハイブリダイゼーションアッセイプローブに関する。このハイブリダイゼーションアッセイプローブは、塩基の標的相補的配列を有するプローブ配列を含み、検出しようとする核酸に相補的でない1つ以上の塩基配列を任意に含む。塩基の標的相補的配列は、配列番号101の配列またはその相補体内に含まれた12〜87個の連続的塩基からなり、RNA等価物、DNA等価物、ヌクレオチドアナログの存在を、および10%まで、またはさらに20%までの塩基の差異を考慮に入れたものである。一般に、本発明のハイブリダイゼーションアッセイプローブは、100塩基までの長さを有することができる。 (もっと読む)
遺伝子検出方法
【課題】 特定の配列を有する遺伝子を高感度に検出する方法を提供する。
【解決手段】 電極上に固定された核酸プローブと、遺伝子サンプルとをハイブリダイズさせる工程と、二本鎖核酸に特異的に挿入し、かつ光照射により該二本鎖核酸と共有結合を形成する二本鎖核酸結合部位と、電気化学活性を有する電気化学活性部位と、前記二本鎖核酸結合部位と前記電気化学活性部位とを連結する連結部位と、を有する化合物からなる挿入剤を添加する工程と、前記二本鎖核酸と前記挿入剤とを共有結合させる光照射工程と、前記二本鎖核酸と共有結合した挿入剤を電気化学的な測定により検出する検出工程と、を含む遺伝子検出方法において、前記挿入剤の電気化学活性部位は、官能基が導入された複素環系化合物を配位子に有する金属錯体である、ことを特徴とする。
(もっと読む)
IGF経路のモディファイヤーとしてのALDOsおよび使用方法
ヒトALDO遺伝子はIGF経路のモジュレーターとして同定されており、したがってこれらは欠陥IGF機能に関連する疾患の治療上の標的である。ALDOの活性を調節する作用剤をスクリーニングすることを含む、IGFのモジュレーターを同定する方法が提供される。 (もっと読む)
塩基多型の同定方法
【課題】塩基多型を明確にまた簡便に検出する方法を提供する。
【解決手段】特定の核酸配列を含む試料溶液に第一のリガンドが結合した該特定核酸配列増幅用オリゴヌクレオチドを用いて、増幅反応し、該核酸配列の塩基多型部位に特異的に結合する第二のリガンドが結合された結合体を接触させ、特定の核酸配列と結合した第二のリガンド結合体との複合体を検出する方法であって、上記第二のリガンドの補捉剤が結合された通液性フィルターの表面に滴下して、該複合体の第二のリガンド部分を、該リガンド補捉剤に結合させる工程;該通液性フィルターの表面に、上記第一のリガンドに結合する、標識された生理活性物質の溶液を滴下して、この標識を持つ生理活性物質を、第二のリガンド補捉剤とリガンド部分とを介して通液性フィルターに結合している第一のリガンドに結合させる工程;そして通液性フィルターに結合した標識を測定する。
(もっと読む)
IGF経路のモディファイヤーとしてのACACsおよび使用方法
ヒトACAC遺伝子はIGF経路のモジュレーターとして同定されており、したがってこれらは欠陥IGF機能に関連する疾患の治療上の標的である。ACACの活性を調節する作用剤をスクリーニングすることを含む、IGFのモジュレーターを同定する方法が提供される。 (もっと読む)
癌における新規な組成物および方法
本発明は、癌、特にリンパ腫の検出、診断、および治療で使用するための新規の配列に関する。本発明は、その発現が癌に関連する癌関連(CA)ポリヌクレオチド配列を提供する。本発明は、癌に対する新規の治療標的を提示する癌に関連するCAポリペプチドを提供する。本発明は、さらに、癌の診断用組成物および癌の検出方法を提供する。本発明は、CAポリペプチドに特異的なモノクローナル抗体およびポリクローナル抗体を提供する。本発明はまた、診断ツールおよび治療組成物ならびに癌をスクリーニングし、防止し、治療する方法を提供する。 (もっと読む)
841 - 860 / 974
[ Back to top ]