
Fターム[5B042JJ03]の内容
デバッグ、監視 (27,428) | 動作監視、異常又は誤りの検出 (3,508) | 監視 (1,259) | 集中監視 (355)
Fターム[5B042JJ03]に分類される特許
41 - 60 / 355
故障予測・対策方法及びクライアントサーバシステム
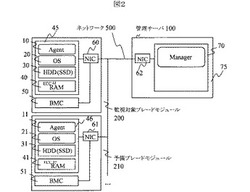
【課題】装置の情報を収集して劣化の度合いを算出し、劣化の度合いにより早期に故障対策を行って、予測を早回る故障発生による被害を抑えることを可能とする。
【解決手段】保守対象とする装置200にネットワーク500を介して接続された管理サーバ100を有し、管理サーバ100は、前記保守対象とする装置から一定の周期で当該装置の情報を取得して当該装置を管理する管理手段70を有する。管理手段70は、取得した保守対象とする装置の情報に基づいて、保守対象とする装置の劣化進行度を算出し、算出した劣化進行度が予め定めた進行度となった場合、あるいは、保守対象とする装置から取得した情報が予め定めた事象を示している場合、前記保守対象とする装置に対する故障対策を実施する。故障対策は、予備の装置210とのミラーリング、予備の装置210への運用切り替えである。
(もっと読む)
分散処理状態可視化システム、分散処理状態可視化装置、分散処理状態可視化プログラム及び分散処理状態可視化方法

【課題】複数のノードによって構成された分散処理システムの状態を、より好適に表示可能とする。
【解決手段】通信ログ収集サーバ30によって、分散処理システムAのノードの通信状態を示す通信ログを収集し、実行ログ収集サーバ60によって、分散処理システムAのノードの処理実行状態を示す実行ログを収集する。そして、表示クライアント70のログ同期部71によって、通信ログと実行ログとを同期させた同期済みログを生成し、ログ表示処理部72によって、同期済みログに基づいて表示画像を生成する。ログ表示処理部72は、生成した表示画像をディスプレイ80に表示する。このように、通信ログと実行ログとを同期させ、同期済みログに基づいて表示画像を生成することにより、分散処理システムにおける通信状態と各ノードの処理実行状態とが同時に表示される。
(もっと読む)
計算機システムの動作状態解析方法
【課題】複数の計算機を含む計算機システムにおける保守効率を向上させることができる計算機システムの動作状態解析方法を提供する。
【解決手段】複数の計算機を含む計算機システムの動作状態を解析する計算機システムの動作解析方法であって、計算機システムを管理する統合管理アプリケーションが搭載された統合管理サーバが各計算機から取得した構成情報とログ情報とを保存し、統合管理アプリケーションの動作を模擬する模擬アプリケーションを実装したシミュレータ装置が、統合管理サーバに保存された構成情報とログ情報とにもとづいて、統合管理アプリケーションの動作を模擬することによってログ情報を解析する。
(もっと読む)
異常検知装置、監視制御システム、異常検知方法、プログラムおよび記録媒体
【課題】 重要インフラストラクチャ等における制御システムをセキュリティ保護すること。
【解決手段】本発明の異常検知装置150は、制御ネットワーク130内で発生したイベント情報を受信して、制御システム102を含むリソース(110,120など)およびプロセス間の依存関係を維持する構成管理データベース170に照会し、イベント情報に関わるリソースが属するグループを識別する識別部152と、異常が疑われる状況を規定する条件と1以上のアクションとを対応付ける1以上のポリシを記憶するポリシ記憶部160と、1以上のポリシを適用する上で必要となるグループ関連情報を取得してイベント情報に付加する付加部156と、1以上のポリシに対しイベント情報を適用し、合致する条件に対応付けられるアクションを実施するべきアクションとして決定する決定部158とを含み、制御ネットワーク130の異常を検知する。
(もっと読む)
情報処理装置並びに情報処理装置の管理方法及び管理プログラム
【課題】複数のプロセッサを備える情報処理装置において新規に追加したプロセッサの運用初期に発生する故障によってシステム全体に障害が発生することを防止する。
【解決手段】複数のプロセッサP0〜P6と、複数のプロセッサP0〜P6を監視し、監視結果から得られた情報を記録し、記録された情報から複数のプロセッサP0〜P6の障害発生確率を計算するサービスプロセッサ110とを備え、新規に追加されたプロセッサP7と、計算手段によって相対的に障害発生確率が低いと計算されたプロセッサP1とを多重化する情報処理装置100である。
(もっと読む)
障害情報・装置情報蓄積装置
【課題】検出対象の装置に発生した障害に関する情報および障害が発生した装置に関する情報を効率的に収集する。
【解決手段】検出対象の装置の障害を検出する障害検出部42,82、および、障害検出部42,82により検出された障害および当該障害が発生した装置に基づいて、当該障害に関する情報の外部サーバ2への蓄積に対する優先度を決定する優先度決定部45,85を有する制御装置4,8と、優先度決定部45,85により決定された優先度に基づいて、障害情報および対応する装置情報を外部サーバ2に送信する通信装置7とを備え、優先度決定部45,85は、障害検出部42,82により検出された障害が致命的なものである場合に、優先度を高く設定する。
(もっと読む)
電子機器のラックマウントシステム及び電子機器の監視方法並びにラックマウント型電子機器
【課題】管理用LANポートを有さないユニットに対してもワイヤレスでの障害監視手段及び停止処理手段や、シリアル情報・ロット情報の管理手段を実施すること。
【解決手段】ラック電源ユニット1内に、RFIDアクティブタグ101,103及びパッシブタグ102を搭載し、該電源ユニット内で異常を感知した場合、該電源ユニットの異常通知401やID番号(型番・ロット情報403)をRFIDアクティブタグ101,103から発信する。発信した情報は、RFIDリーダ/ライタ202を介して監視サーバに201に通知され、該監視サーバは当該電源ユニットに対してRFIDリーダ/ライタ202を介して停止信号402(電波)を発信する。この停止信号をRFIDパッシブタグ102が受け取ると、該電源ユニットの制御IC105へ停止信号を送出し、該電源ユニットを停止させる。
(もっと読む)
システム分析支援プログラム、システム分析支援装置、およびシステム分析支援方法
【課題】バッチ処理にかかるメッセージを判別すること。
【解決手段】システム分析支援装置は、DBサーバ104との通信で使用されるプロトコルのメッセージのオブジェクト(データベースに対する操作を表す命令文の一部または全部)ごとに、該オブジェクトの集計期間T内のメッセージのうち親が存在するメッセージの出現率を求める。そして、システム分析支援装置は、集計期間Tに対する直上層のプロトコルの占有期間の占有率と、オブジェクトごとの出現率とに基づいて、バッチ処理のオブジェクトを判断する。このように、システム分析支援装置は、直上層のプロトコルの占有率の増加に伴って親が存在する割合が増加するというバッチ処理のオブジェクトの特徴を利用して、バッチ処理のメッセージを判別するための情報を作成する。
(もっと読む)
プログラム、情報処理装置、及び情報処理方法
【課題】コンピュータシステムの障害検知のための作業負担を軽減させること。
【解決手段】プログラムは、情報処理システムの構成要素の識別情報に対応付けて該構成要素の種別情報を記憶する構成情報記憶部を用いて、前記情報処理システムより出力され、前記識別情報を含むメッセージに対応する種別情報を判定し、複数のメッセージが含まれる第一のメッセージ群と、他の情報処理システムの構成要素の種別情報をメッセージごとに関連付けてメッセージ群記憶部が記憶する第二のメッセージ群とを照合し、一致しないメッセージ同士については、それぞれに係る種別情報に関して照合を行う処理をコンピュータに実行させる。
(もっと読む)
異常検知方法およびそれを用いた情報処理システム
【課題】予想しないソフトウェアの異常動作に対しても、ソフトウェアの稼働中に状態遷移モデルに基づく状態遷移毎の遷移確率を利用して異常を検知し、さらにソフトウェアの異常箇所を特定する。
【解決手段】ソフトウェアの状態遷移モデル202に基づいた状態遷移確率モデルにおいて、基準となる第1の状態遷移確率モデル203と、ソフトウェアの運用中に、状態遷移確率を算出して求めた第2の状態遷移確率モデル215と、あらかじめ設定した状態遷移毎の遷移確率を比較することにより異常度を求め、異常判定手段216は、異常度としきい値情報204とを比較し、異常度が異常を示す値か否かを判断し、異常と判断された状態遷移に対応したソフトウェアの実行箇所を特定する。
(もっと読む)
状態量表示装置、状態量表示方法およびプログラム
【課題】情報処理装置の状態量を表示する状態量表示装置が、情報処理装置の全体的な状況を直感的に把握可能な表示を行えるようにする。
【解決手段】状態量表示装置300において、通信部310が、サーバ装置の各々から第1の状態量と第2の状態量と第3の状態量とを取得する。そして、表示部320が、第1の状態量に応じた高さと、第2の状態量に応じた横幅と、第3の状態量に応じた奥行きとを有する立体図形を表示する。状態量表示装置300のユーザは、表示された立体図形の大きさおよび形状によって、各状態量を直感的に一括して把握することができる。
(もっと読む)
管理装置、管理方法および管理用プログラム
【課題】機器の構成や設定が変更された場合にも、メッセージパターンに基づく障害検知を適切に行う。
【解決手段】情報処理システム605に障害が発生したときに、情報処理システムから一定期間に受信したメッセージを含むメッセージ群を示す第1のメッセージパターンが検出された検出回数を記憶した障害共起情報601から検出回数を読み出し、検出回数に基づいて障害と第1のメッセージパターンとの共起確率を算出し、共起確率が閾値以上の場合に前記障害が発生したと判別する判別手段602と、構成要素が変更されると、変更された構成要素が出力するメッセージを第1のメッセージパターンから除いたメッセージ群を示す第2のメッセージパターンを作成し、障害共起情報に記憶された第1のメッセージパターンを第2のメッセージパターンに更新する更新手段603と、を備える。
(もっと読む)
端末ログ利用システム及び端末ログ利用システムの制御方法
【課題】ユーザの利便性を維持しつつ、端末ログの送信に関する通信データ量の削減を実現することができる端末ログ利用システムを提供する。
【解決手段】端末ログ利用システム10は、端末装置20に端末ログの送信を行わせるためのログ送信要求を所定周期で送信する要求送信部32と、端末装置20がログ送信要求を受信したことを示す受信通知を送信する通知送信部23と、受信通知を受信する通知受信部33と、端末ログの送信の可否及び端末ログを送信する場合の端末ログの内容を判定するログ送信制御部24と、端末ログを送信すると判定した場合に、送信内容が決定された端末ログをログ利用サーバ30へ送信するログ送信部25と、通知受信部33で受信する受信通知及びログ受信部34で受信する端末ログの受信結果に基づいて端末ログの内容を決定する受信ログ処理部35と、を備える。
(もっと読む)
障害検知装置、情報処理方法、およびプログラム
【課題】異常検知のための分析処理にかかる時間を短縮するとともに、異常発生個所の誤検出を防止可能にした障害検知装置を提供する。
【解決手段】複数のシステムのそれぞれに対応する物理機器の情報を示す設定ファイルが予め登録され、物理機器の性能種目毎の時系列データである性能データを記憶する記憶部と、一定の時間間隔で設定ファイルを参照して性能データをシステム単位に分割する分析領域分割部と、分割された性能データ間に存在する相関関係を分析し、分析した相関関係毎に異常があるか否かを判定する分析部と、分析された相関関係のうち、異常があると判定された相関関係の割合を性能データ毎に算出し、割合の高い方が表示順の上位になるように、割合と物理機器の名称との組み合わせを記述したテーブルを複数のシステム毎に出力する分析結果出力部と、を有する。
(もっと読む)
障害監視装置、障害監視システム、障害監視方法およびプログラム
【課題】ユーザへの不要な障害発生の通知を軽減する。
【解決手段】複数の処理装置を含む処理システムの障害を監視する障害監視装置であって、いずれかの処理装置に障害が発生していることを示す情報を含む障害発生情報を受信する障害検知部1と、障害通知情報を出力する出力部2と、複数の処理装置の中のいずれかが自動復旧作業を開始したことを示す情報を含む自動復旧情報を受信する自動復旧検知部3と、障害検知部1が障害発生情報を受信すると、複数の処理各々に、当該処理を行う処理装置を対応付けて記憶する対応付け記憶手段を参照し、障害発生情報で特定される処理装置が行う処理を特定するとともに、当該処理と、自動復旧情報で特定される処理装置が行う処理との関係に基づき、障害通知情報の出力を制限するか否かを決定し、出力部2を制御する出力制御部4とを有する障害監視装置。
(もっと読む)
ネットワークシステム、サーバ、情報処理装置、ログ登録方法、及び、プログラム
【課題】クラウドコンピューティングでのインスタンスの総起動時間を減らしログ登録の運用コストを削減すること。
【解決手段】サーバコンピュータ群102の登録予約要求受付部1201は、クライアント(103or104)から送信されるログの登録予約要求を受け付け、ジョブログ保存部804に最後に登録されたログのLog IDをクライアントに返信する。クライアントは、返信されたLog IDに基づいて登録要求するログを選択し、選択したログを登録要求受付部801に送信する。登録要求受付部801は、クライアントから送信されたログの登録要求を受け付け、該ログを圧縮データ一時保存部803に保存し、メッセージを第一実行命令データ保存部803に登録する。登録処理部805は、第一実行命令データ保存部803からメッセージを取得し、圧縮データ一時保存部803に保存されたログをジョブログ保存部804に登録する。
(もっと読む)
電子装置、状態グラフを圧縮する方法、及び製品
【課題】インタラクティブ型クライアント−サーバ・アプリケーションのクローリングにおける状態情報の圧縮のための電子装置等を提供する。
【解決手段】電子装置は、状態グラフを有するメモリと、メモリへ結合されるプロセッサとを有する。状態グラフは、クロールされるインタラクティブ型クライアント−サーバ・アプリケーションの複数の状態を含む。複数の状態及び遷移は、クライアント−サーバ・アプリケーションのクローリングから得られる。複数の状態は、1又はそれ以上の初期状態ノードを有する初期状態と、1又はそれ以上の第2状態ノードを有する第2の状態とを有する。プロセッサは、初期状態と第2の状態との間の差を決定し、その差を用いて初期状態に対して第2の状態を圧縮して、圧縮された状態を生じるよう構成される。
(もっと読む)
複数のログ・エントリをマージする技術
【課題】不確定なコンディションのもとで生成されるログ・エントリから、高度のイベント情報を自動的に収集する。
【解決手段】エージェント104内のパーサ102が、複数デバイスおよびいくつかのソフトウェアからログ・エントリを受け取る。パーサ102は、ログ・エントリを構文解析してトークンをグルーピング・トラッカー・モジュール110に出力する。グルーピング・トラッカー・モジュールは、マージ・プロパティを使用して、被マージイベントを構築し、特定の被マージイベントに関連するログ・エントリをマッピング・モジュール120に出力する。マッピング・モジュールは、マッピング・プロパティ122に従って、ログ・エントリを被マージイベント内にマッピングし、複数ログ・エントリに起因する一つ以上の被マージイベントとして出力する。
(もっと読む)
情報処理装置、運用管理方法および運用管理プログラム
【課題】管理対象に対する複数の運用管理装置の制御を最適化することが可能な情報処理装置、運用管理方法および運用管理プログラムを提供する。
【解決手段】情報処理装置201は、複数の運用管理装置の各々から、管理対象と、管理対象に対して制御を実行する条件と、実行すべき制御内容とを示す1または複数のルールを取得するためのルール収集部10と、ルール収集部10が取得した各ルールから、各運用管理装置間で管理対象および条件が一致する複数のルールを特定するための重複特定部30とを備える。
(もっと読む)
情報処理装置、故障部位判別方法および故障部位判別プログラム
【課題】マルチプロセッサ構成の情報処理装置において立ち上げ処理を迅速に行い、かつ、インターフェース障害が発生しても故障部位を正確に判別することが可能な情報処理装置を提供する。
【解決手段】例えばCPU11上で動くBIOS61が障害を検出した場合、CPU11のステータスレジスタ21の解析結果によるエラーコードとインターフェース回路5の通信先のCPU12の調査依頼とからなる障害検出通知をBMC3に送信し、BMC3上で動くBMCFW7は、受信した障害検出通知のエラーコードに基づき障害被疑部位の可能性を示す割合を第1の被疑割合として決定し、かつ、通信先のCPU12のステータスレジスタの読み取り結果に基づき障害被疑部位の障害の可能性を示す割合を第2の被疑割合として決定し、決定した第1、第2の被疑割合をあらかじめ定めた規則にしたがってマージして最終的な被疑割合を求めることにより故障部位を判別する。
(もっと読む)
41 - 60 / 355
[ Back to top ]