
Fターム[5B075NK32]の内容
検索装置 (67,127) | 検索キー情報 (8,147) | 検索キー情報の自動抽出 (2,419) | 自然言語解析による検索キーの抽出 (1,229)
Fターム[5B075NK32]の下位に属するFターム
不要語辞書 (35)
限定辞書 (43)
類義語拡張を伴うもの (357)
Fターム[5B075NK32]に分類される特許
21 - 40 / 794
主題抽出装置、方法、及びプログラム
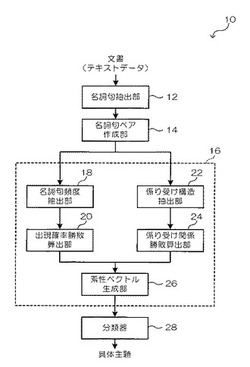
【課題】文書から主題を抽出する。
【解決手段】名詞句抽出部12で、具体主題の候補となる名詞句を抽出し、名詞句ペア作成部14で、名詞句ペアを作成する。名詞句頻度抽出部18で、名詞句各々の出現頻度、及び名詞句ペア各々の共起頻度を抽出し、出現確率勝敗算出部20で、名詞句各々の出現頻度及び名詞句ペアの共起頻度から求まる名詞句各々の出現確率を求め、名詞句ペアで出現確率に基づく勝敗を示す第1の素性を算出する。また、係り受け構造抽出部22で、名詞句ペアの係り受け構造毎の出現頻度を抽出し、係り受け関係勝敗算出部24で、名詞句ペアで係り先になり易さによる勝敗を示す第2の素性を算出する。素性ベクトル生成部26で、第1の素性及び第2の素性を並べた素性ベクトルを生成し、具体主題が既知の学習用文書に含まれる名詞句の素性ベクトルを用いて学習された分類器に入力して、具体主題を示す名詞句を抽出する。
(もっと読む)
具体主題分類モデル学習装置、方法、プログラム、具体主題抽出装置、方法、及びプログラム

【課題】文書中の任意の数の具体主題を抽出する。
【解決手段】学習用名詞句抽出部14で、具体主題が既知の学習用文書から学習用名詞句を抽出し、学習用素性抽出部16で、各名詞句の学習用素性を抽出し、閾値生成部18で、正例の素性の平均と負例の素性の平均の平均を、具体主題を示す名詞句か否かを判定するための閾値として生成する。正例の素性を1位、閾値を2位、負例の素性を3位とする学習データでランキング型の分類モデルを学習する。具体主題が未知の文書が入力されると、分類用名詞句抽出部34で、分類用名詞句が抽出され、分類用素性抽出部36で、各名詞句の分類用素性が抽出され、分類モデルに、閾値及び各名詞句の分類用素性を入力し、閾値とのランキング比較で1位となる分類用素性に対応する名詞句を、具体主題を示す名詞句として抽出する。
(もっと読む)
インタビュー支援装置、方法及びプログラム
【課題】インタビューすべき項目の漏れを少なくするインタビュー支援技術を提供する。
【解決手段】インタビュー支援装置は、インタビューの少なくとも一部の内容を示すテキストデータを品詞毎に分割する手段と、分割された複数の単語の中からキーワードを抽出する手段と、上記インタビューにおいて聴取されるべき項目毎に、当該項目に関するインタビューで聴取される内容に含まれる可能性の高い単語である代表語をそれぞれ保持する手段と、上記キーワードと上記代表語とを比較することにより当該キーワードに対応する項目を抽出する手段と、インタビューにおいて聴取されるべき各項目を示すデータと、抽出された項目と、を比較することにより、上記インタビューにおいて未だ聴取されていない項目を特定する手段と、この特定された未だ聴取されていない項目を示す情報が出力されるように制御する手段と、を備える。
(もっと読む)
文書管理装置、文書管理方法および文書管理プログラム
【課題】 閲覧者に周知な部分と周知でない部分とを異ならせた文書を生成すること。
【解決手段】 ファイルサーバは、予め記憶された文書がアクセスされることに応じて、アクセス履歴情報をアクセスされた文書に関連付けて記憶する文書管理部67と、閲覧先情報を受け付ける閲覧先情報受付部53と、処理対象文書からキーワードを抽出するキーワード抽出部51と、抽出されたキーワードを含む1以上の文書を抽出するために記憶された文書を検索する文書検索部65と、文書検索部65による検索によって抽出された1以上の文書に関連付けられたアクセス履歴情報に基づいて、受け付けられたキーワードに関連する関連ユーザを特定する関連ユーザ特定部69と、特定された関連ユーザと受け付けられた閲覧者情報とに基づいて、キーワードが閲覧先に周知か否かを判断する判断部81と、を備える。
(もっと読む)
トピックモデリング装置、トピックモデリング方法、及びプログラム
【課題】従来よりも人間にとって理解し易く、確率的に解釈可能なトピック情報を得ることができ、パラメータ数が少ないトピックモデルを生成する。
【解決手段】入力された各テキストデータに含まれる各文字列に対して語義を付与し、語義gが付与された文字列を含むテキストデータの集合をテキストデータ集合dg、テキストデータ集合dgが含む文字列の集合を文字列集合wg、テキストデータ集合dg中の文字列vの出現回数をn(dg,v)、p(v|z)=βzv、(z|dg)=ηgz、トピック情報zの全体集合をZとした場合におけるトピックモデルp(vg|dg)=Πv{Σz βzv・ηgz}n(dg,v)の多項分布パラメータβzvを得る。
(もっと読む)
複合語生成装置、複合語生成方法、および複合語生成プログラム
【課題】 学習テキストなどを利用することなく、複合語を生成することができる複合語生成装置および複合語生成方法を提供することを目的とする。
【解決手段】 テキスト分割部101が入力されたテキストを、空白文字に基づいて複数の文字列に分割し、文字列生起回数集計部102が、テキスト分割部101により分割された文字列の各々について生起回数を計数するとともに、分割された文字列を候補文字列として含む文字列集合を作成する。そして、文字列生起回数集計部102により作成された文字列集合に含まれる候補文字列に基づいて、要素文字列組合せ抽出部103は、複合語の要素となる要素文字列を複数連結して候補文字列を構成可能な要素文字列の組み合わせを文字列集合から抽出する。
(もっと読む)
特徴語抽出装置、プログラム及び方法
【課題】テキストマイニングの対象となる文書のデータに対して適切な語の区切りを自動的に設定する。
【解決手段】本特徴語抽出装置は、複数の文書のデータが格納されている文書格納部と、当該複数の文書のデータのうち第1の文書のデータにおける文節の各々を、区切り位置及び区切りの数を変化させつつ分割し、当該分割により得られた文字列をデータ格納部に格納する生成部と、データ格納部に格納されている文字列の各々について、当該文字列が第1の文書のデータに出現する回数と文書格納部に格納されている複数の文書のデータのうち当該文字列が出現する文書のデータの件数とを用いて特徴度を算出する算出部と、第1の文書のデータにおける文節の各々について、当該文節についての文字列のうち特徴度が最も高い文字列を特定し、特徴語格納部に格納する特定部とを有する。
(もっと読む)
番組情報収集装置、映像表示装置、番組情報収集方法
【課題】ネット上の書き込み記事の内容は、言葉が変わっているため、適当なキーワードを見つけにくい。このため、テレビ番組に関するユーザの興味等を調査する際の、適当なキーワードを見つけることが課題となっていた。
【解決手段】実施形態の番組情報収集装置は、インターネットから抽出された記事から前記記事に関連する第1のキーワードを抽出する第1のキーワード抽出部を備える。また、番組情報から前記番組情報に関連する第2のキーワードを抽出する第2のキーワード抽出部を備える。また、前記抽出された前記第1のキーワードと前記第2のキーワードの部分一致を第3のキーワードとして抽出する第3のキーワード抽出部を備える。また、前記抽出された前記第3のキーワードをキーワードとして、キーワード検索によって前記インターネットから該当する記事を抽出する記事抽出部を備える。
(もっと読む)
検索装置、検索方法、及びプログラム
【課題】主観表現を含む自然文を条件に用いた検索の効率化を実現すること。
【解決手段】数値範囲に変換すべき主観表現を含む自然文が入力された場合に、前記自然文を構成する要素の中で前記主観表現を除く要素を検索の条件にして検索を実行する暫定検索部と、前記暫定検索部による検索の結果を対象に、前記主観表現に対応する数値の分布を取得する分布取得部と、前記主観表現に予め対応付けられた相対値に基づいて前記分布取得部により取得された数値の分布から数値範囲を選択する数値範囲選択部と、前記自然文を構成する要素の中で前記主観表現を除く要素、及び前記数値範囲選択部により選択された数値範囲を検索の条件にして検索を実行する本検索部と、を備える、検索装置が提供される。
(もっと読む)
計算機、文書提示方法及び文書提示プログラム
【課題】情報の取捨選択の有効な判断材料となる見出しを付与した文書を提示する計算機を提供する。
【解決手段】文書を格納する文書データベースに接続された計算機であって、プロセッサは、文書データベースに格納された文書に含まれる単語間の因果関係を抽出し、抽出された単語間の因果関係をネットワーク構造で表した因果ネットワークデータを作成し、因果ネットワークデータから、利用者が興味を持っている単語である興味語と因果関係にある単語を抽出し、興味語を第1ワード、抽出された単語を第2ワードとした場合における第1ワードと、第2ワードとに基づいて、文書の見出しを作成し、作成された見出しが付与された文書を、出力装置を介して利用者に提示するためのデータを生成する。
(もっと読む)
情報取得装置
【課題】 質問と回答の対で構成されるテキストデータから有用な情報を抽出する。
【解決手段】 質問と回答の内容をそれぞれ解析し、それらの解析結果を組合せることで有用な情報を抽出する。具体的には、質問と回答の対から成るテキストデータを入力する入力手段と、前記テキストデータから情報を抽出する情報抽出手段と、前記情報抽出手段が抽出した結果を出力する出力手段とを備え、前記情報抽出手段は、上記入力手段による入力の質問部分テキストを解析する質問テキスト解析手段と,同入力の回答部分テキストを解析する回答テキスト解析手段と,上記質問テキスト解析手段と上記回答テキスト解析手段の解析結果からテキストの適合判定を行う適合テキスト判定手段を含む、情報取得装置とする。
(もっと読む)
擬似会話装置及びコンピュータプログラム
【課題】人工無脳による擬似会話の内容をユーザの好みに合わせた内容に調整することができる擬似会話装置及びコンピュータプログラムを提供する。
【解決手段】人工無脳の処理を実行する擬似会話装置1は、ユーザから入力される会話文と応答文とでなる擬似会話を特徴付けるための複数の数値からなる個性ベクトル(特徴データ)を記憶部14に記憶する。擬似会話装置1は、ユーザから入力された会話文に応じて、個性ベクトルと同数の数値からなる文特徴ベクトル(文特徴データ)が個性ベクトルに近い文を文データから抽出し、抽出した文から、会話文に対する応答文を生成する。このように、個性ベクトルに基づいて応答文を生成することにより、人工無脳に個性を付与する。個性ベクトルは、ユーザの指示に応じて設定され、ユーザの好みに合わせて成長させることができる。
(もっと読む)
データ抽出装置、データ抽出方法、及びプログラム
【課題】効率的にセマンティックドリフトを軽減する。
【解決手段】正例エンティティとその属性とのペアの素性と、負例エンティティとその属性とのペアの素性とを教師あり学習データとした学習処理によって識別モデルを生成し、対象エンティティと対象属性とのペアの素性を識別モデルに入力して、対象エンティティが正例エンティティを識別する。この際、対象属性が正例か否かの判定結果を出力し、人手による修正内容の入力を受け付ける。人手による修正内容を利用して正例属性を定める。
(もっと読む)
医用レポート作成支援装置
【課題】読影医等の判断に依ることなく自動的に関連する症例レポート検索を行い、新たに医用レポートを作成するにあたり、医療情報分野における過去作成の症例レポートから症例に関する単語又は単語列をキーワード検索により所望する関連医用レポートを検索して得た情報を同一画面表示又は別画面表示で行い、これを参考にして新たな所見等の情報を入力して医用レポート作成精度の向上、記載漏れのチェック、誤診の解消、信頼性の高いレポート作成の向上とともにレポート作成作業の能率向上等に資する医用レポート作成支援装置を提供する。
【解決手段】医用レポート作成支援装置は、検査目的欄、所見欄、診断欄を含む過去の医用レポートの文章の中から関連症例レポートを自動検索するための症例に関する発生頻度と重要度により重み付けされた単語又は単語列をキーワードとして、過去の医用レポートから関連性の高い医用レポートを自動検索する手段を備える。
(もっと読む)
発話抽出プログラム、発話抽出方法、発話抽出装置
【課題】対話時の発話から特定の発話を抽出する発話抽出プログラム、発話抽出方法、発話抽出装置を提供する。
【解決手段】第1の話者および第2の話者の発話区間を抽出して、日時または経過時間に関連付けて記録させる処理と、特徴操作記憶部を参照して、対話中に機器を第1の話者が操作した機器の状態を、日時または経過時間に関連付けて記録した操作情報から、特徴操作テーブルに合致する操作情報を抽出し、抽出した操作情報の発生した日時または経過時間を示す特徴操作時刻情報を取得させる処理と、発話抽出条件を参照して、発話抽出条件に合致する区間を、第1の話者および第2の話者の抽出した発話区間と抽出した特徴操作時刻情報を用いて抽出し、抽出した合致する区間から発話抽出条件に関連付けられている時間範囲に存在する第1の話者の発話区間に対応する発話を抽出させる処理と、をコンピュータに実行させる発話抽出プログラム。
(もっと読む)
端末装置、表現出力方法、およびプログラム
【課題】Web等の多量の文書から対立する評価表現を出力できない。
【解決手段】評価語句と評価極性とを有する評価語句情報を1以上格納し得る評価語句辞書と、トピックに関連する文から評価語句辞書に格納されている評価語句を用いて、評価語句を含む1以上の語句の集合である評価表現を2以上抽出する評価表現抽出部と、評価表現抽出部が抽出した2以上の各評価表現に含まれている1以上の語句から、2以上の評価表現をクラスタリングし、1以上の評価表現を含む2以上の評価表現グループを取得する評価表現クラスタリング部と、一のトピックに関する肯定的な評価表現と否定的な評価表現を取得する対立評価表現取得部と、肯定的な評価表現、否定的な評価表現を出力する対立評価表現出力部とを具備する端末装置により、Web等の多量の文書から対立する評価表現を出力できる。
(もっと読む)
画像処理装置、有識者情報蓄積方法および有識者情報蓄積プログラム
【課題】キーワードに関する知識を有するユーザを特定する。
【解決手段】MFPは、文書を処理するためのジョブを受け付けるジョブ受付部53と、ジョブを実行するジョブ実行部55と、ジョブ実行部により実行されたジョブの対象となった文書からキーワードを抽出するキーワード抽出部57と、ジョブ実行部によるジョブの実行に応じて、ジョブの対象となった文書から抽出されたキーワードと、ジョブの実行を指示した指示者を識別するユーザ識別情報または/およびジョブの対象となった文書の作成者を識別するためのユーザ識別情報とを含むジョブ履歴情報91を記憶するジョブ履歴記憶部116と、を備える。
(もっと読む)
行動支援情報提供装置、方法、及びプログラム
【課題】ユーザが予定している行動に関するメッセージを閲覧するときに、その予定している行動を支援する情報を提供する。
【解決手段】ユーザ端末から受信したメッセージに含まれている、ユーザが予定している行動を特定する語句である行動特定語を抽出し、この行動特定語に基づいて、ユーザが予定している行動を支援する情報である行動支援情報を取得する。そして、取得した行動支援情報に対応するアイコンデータを、受信したメッセージを記述した文書データに埋め込み、行動支援メッセージデータとして、受信ユーザのユーザ端末に対して送信する。
(もっと読む)
検索ログに応じた関連情報を配信する検索配信サーバ、プログラム及び方法
【課題】広告主の観点から、ユーザの検索ログに応じた広告情報(関連情報)を配信することができる検索配信サーバ、プログラム及び方法を提供する。
【解決手段】情報検索エンジン手段と、検索ログ蓄積手段と、分析対象キーワード抽出手段と、分析対象キーワードリスト手段と、分析対象検索ログ抽出手段と、検索セッション分割手段と、検索セッションクラス抽出手段とを有する検索配信サーバであって、関連情報キーワードを記録する関連情報キーワードリスト手段と、関連情報キーワードを、分析対象キーワードリストに付加する関連情報キーワード付加手段と、k個の検索セッションクラスの中で、関連情報キーワードが含まれたクラスを帰属クラスとして検出するキーワード帰属クラス算出手段と、帰属クラスに含まれる検索ログのユーザ識別子を抽出し、当該ユーザ識別子に対応する端末へ、関連情報を配信する配信先決定手段とを有する。
(もっと読む)
電子機器、人物相関図出力方法、人物相関図出力システム
【課題】電子書籍コンテンツの内容にあった人物相関図を表示し、視覚的にも楽しみたいというユーザの要求があった。また、視覚的に表示された内容がコンテンツ本文のどこに書いてあるかを知りたいというユーザ要求があり、これらを解決する電子機器の提供が課題となっていた。
【解決手段】実施形態の電子機器は、電子書籍コンテンツの本文に係る情報から、登場人物の視覚化に係る情報である人物視覚化情報と、前記登場人物間の関連に係る情報である人物関連情報と、前記人物視覚化情報または前記人物関連情報あるいはその両方の前記電子書籍コンテンツの本文に係る情報の参照先に係る情報である本文参照情報を解析する情報解析手段を備える。また、前記解析された人物視覚化情報と人物関連情報に基づいて、前記登場人物間の相関を示す人物相関図を出力する人物相関図出力手段を備える。
(もっと読む)
21 - 40 / 794
[ Back to top ]