
Fターム[5B091CA21]の内容
Fターム[5B091CA21]の下位に属するFターム
Fターム[5B091CA21]に分類される特許
81 - 100 / 152
言語変換装置、言語変換方法、及びコンピュータプログラム

【課題】現時点において実際に使用される方言に対応することを可能にする言語変換装置、言語変換方法、及びコンピュータプログラムを提供すること。
【解決手段】方言辞書を有する言語変換装置20であって、コンテンツに含まれるテキスト情報をユーザから指定を受けた指定方言に変換する指定方言変換部32と、指定方言に変換したテキスト情報である方言テキストをネットワークを介して接続されるユーザ装置10に送信して表示させる方言テキスト表示部と、方言テキストに対して、複数の寄稿者からのコメントを受け付けるコメント受付部34と、を有する。
(もっと読む)
翻訳装置、クラスタ生成装置、クラスタの製造方法、およびプログラム

【課題】従来の翻訳装置においては、精度の高い翻訳ができない、という課題があった。
【解決手段】n種類の区別された言語モデルを格納しており、翻訳対象の第一の言語の文を受け付け、当該文を1以上の用語に分割する文分割部と、各言語モデルを読み出し、当該各言語モデルを用いて、文分割部が取得した1以上の各用語が、各言語モデルが有する1以上の対訳文対中に出現する確率に関する情報である翻訳原文出現確率を、言語モデル毎に算出する翻訳原文出現確率算出部と、言語モデル毎に算出されたnの翻訳原文出現確率を用いて、最も出現する確率が高い言語モデルを決定する言語モデル決定部と、言語モデル決定部が決定した言語モデルを読み出し、当該読み出した言語モデルを用いて、前記受付部が受け付けた文を第二の言語の文に翻訳する翻訳部を具備する翻訳装置により、精度の高い翻訳ができる。
(もっと読む)
音声翻訳装置及びその方法
【課題】音声認識や機械翻訳の失敗の可能性があることを利用者にわかるように翻訳結果を音声で出力できる音声翻訳装置を提供する。
【解決手段】音声翻訳装置10は、音声入力部11、音声認識部12、機械翻訳部13、パラメータ設定部14、音声合成部15、音声出力部16からなり、音声認識・機械翻訳によって得られる複数の尤度から出力する音声データの音声ボリューム値を決定し、尤度の低い語彙に関してユーザに対して音声ボリューム値を小さくして伝わりにくくし、逆に尤度の高い語彙に関してユーザに対して音声ボリューム値を大きくして、特に強調されて伝えられるようにする。
(もっと読む)
機械翻訳装置及び機械翻訳プログラム
【課題】翻訳辞書に登録されていない未知語であっても、精度の高い訳語を出力することができる機械翻訳装置を提供することである。
【解決手段】綴り対応表106には、未知語に対応できるようにするために、あらかじめ第一言語の語句中の一文字以上の文字からなる字句及びこれに対応する第二言語の文字による綴りの一以上の字句が対応づけられて記憶されている。未知語処理部105は、入力処理部102で分解された語句が翻訳辞書部104に存在しないときは、その未知語をさらに一文字以上の文字からなる字句に分解し、その分解した字句を綴り対応表106から検索して第二言語の字句を抽出する。そして、その抽出した第二言語の字句を合成して未知語の訳語を求める。
(もっと読む)
文変換処理システム,文変換機能付きの翻訳処理システム,文変換機能付きの音声認識処理システム,および文変換機能付きの音声合成処理システム
【課題】 日本語の受身文・使役文を能動文に変換する際に機械学習方法を用いて変換後の格助詞を高精度に推定するシステムを提供する。
【解決手段】 解データ分割部101は,解データの問題から格助詞を特定し格助詞ごとの部分データを作成する。解−素性対生成部103は,部分データのもとの解データから素性を抽出し,部分データごとに素性の集合と解との組を生成する。機械学習部105は,所定の機械学習法により,部分データの素性の集合と解との組について,どのような素性の集合の場合にどのような解になりやすいかを学習し学習結果を学習結果データベース107に保存する。入力文分割部110は,対象の入力文3を格助詞で分割して入力文部分データを作成する。素性抽出部112は,入力文3から素性を抽出し,入力文部分データごとに素性の集合を生成する。解推定部は,学習結果をもとに,入力文部分データについて素性の集合の場合になりやすい解を推定し,変換文生成部116は,推定解をもとに変換文4を生成し出力する。
(もっと読む)
機械翻訳装置、機械翻訳方法、および生成規則作成装置、生成規則作成方法、ならびにそれらのプログラムおよび記録媒体
【課題】翻訳精度を向上させることのできる機械翻訳技術を提供する。
【解決手段】機械翻訳装置2は、同期文脈自由文法における生成規則の右辺の翻訳先言語の記号列が終端記号から始まるように制約された生成規則を格納したルールテーブル114から部分仮説に対して生成規則を探索する生成規則探索手段241と、その生成規則に対して生成規則の非終端記号が被う入力文の範囲を示す単語範囲を付加する単語範囲付き生成規則生成手段242と、単語範囲付き生成規則に含まれる翻訳済み単語と単語範囲とを新たな部分仮説として作成し、生成規則をトップダウンに適用し且つ生成規則の翻訳先言語側の非終端記号が文頭から文末に亘って並べられた順序で新たな部分仮説を順次拡張し、部分仮説スコアを算出する部分仮説スコア算出手段243と、適用可能な仮説のうちで部分仮説スコアが最大となる仮説を探索する仮説探索手段244とを備える。
(もっと読む)
機械翻訳装置及びコンピュータプログラム
【課題】 複数の機械翻訳部で得られた翻訳候補から最良の翻訳候補を選択する際に、曖昧さのレベルを下げることにより、最終的な翻訳品質を改善する。
【解決手段】機械翻訳システム130は、中国語による共通の入力文に対し、各々が英語による翻訳候補を出力する機械翻訳装置30A及び30Bと、これら翻訳候補を受け、互いに異なる性格のパラレルテキストコーパス142及び144から得られた言語モデル群150A及び翻訳モデル群152A、並びに言語モデル群150B及び翻訳モデル群152Bを用いた判定基準により、各翻訳候補の双方のスコアを算出し、そのスコアに基づいて、機械翻訳装置30A及び30Bの出力する翻訳候補のいずれかを入力に対する翻訳文出力160として選択し出力するセレクタ182とを含む。
(もっと読む)
機械翻訳装置、その方法およびプログラム
【課題】原言語の文を語順が大きく異なる別の目的言語の文に機械翻訳する際に、より自然で文法的に正しい翻訳を可能とすること。
【解決手段】近似的に求めたN−best句対応付けの初期値から翻訳モデル推定手段3により句翻訳確率と句並び替え確率を求め、その句翻訳確率と句並び替え確率と言語確率を用いてN−best句対応付け手段4によりN−best句対応付けを求め、さらにこのN−best句対応付けから翻訳モデル推定手段3により句翻訳確率と句並び替え確率を求めるという手順を繰り返すことによって句翻訳確率と句並び替え確率を精度良く推定し、こうして推定した句翻訳確率と句並び替え確率を用いて翻訳デコーディング手段8により、原言語文の文を句に分割し、各々の句の対訳となる目的言語の句を列挙し、これを並べ替えることにより目的言語の文を生成する。
(もっと読む)
機械翻訳システム
【課題】訳文の一部として翻訳メモリが適用された場合にも、文全体の整合性が保たれるようにして翻訳精度を向上させることである。
【解決手段】制御部6は訳文される第二の言語の一部に対し、第一言語の原文と第二の言語の訳文とを文単位で対にしたデータを記録する翻訳メモリ4に記録されたデータを適用できるか否かを判断し、適用できる場合は、翻訳メモリ適用部5により翻訳メモリ4のデータが訳文の文全体として整合するように翻訳メモリのデータの一部を変化させて翻訳する。一方、適用できないときは、翻訳部3により第一言語の構文を解析して第二言語に翻訳する。
(もっと読む)
ゲーム装置及びゲーム制御方法
【課題】娯楽性の高いゲーム装置を表現する。
【解決手段】ゲーム端末10において、RSS取得部41はウェブサーバからRSSを取得し、アイテム選択部42は対象となるアイテムを選択し、形態素解析部43は選択されたアイテムのタイトルを形態素解析する。単語取得部45は、候補抽出部44により抽出された単語の中からユーザが選択した単語を取得する。学習部46は、選択された単語の情報をユーザから受け付ける。辞書登録部47は、受け付けた単語の情報をユーザ辞書記憶部64のユーザ辞書に登録する。クイズ制御部51は、コンテンツに関するクイズゲームを行う。
(もっと読む)
非構造化リソースの構文解析方法
1つ以上のデータ部を含む非構造化リソースを処理する方法及び装置が説明される。この方法は、非構造化リソースをメモリ内に読み込むステップと、該非構造化リソースに関連するデータ構造にアクセスするステップとを含む。該データ構造は1つ以上のエレメントを含み、各エレメントは該非構造化リソースにおけるデータ部の位置情報を含む。この位置情報を用いて、データ部は前記非構造化リソースから探索及び処理され、この探索及び処理のステップはデータ構造におけるエレメント毎に繰り返される。 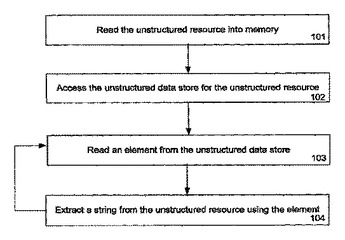 (もっと読む)
(もっと読む)
部分翻訳装置
【課題】 ユーザーにとって翻訳が困難な文、もしくは翻訳をできでも十分に理解することができない文を自動判定して抽出し、抽出された文を翻訳する部分翻訳装置を提供する。
【解決手段】 翻訳装置は、入力文30に対して、ユーザーが難易度レベルを設定すると、翻訳判定器40は、そのレベルに応じて、入力文が設定レベル内かどうかを自動的に判定し、難易度レベルより上の入力文のみ機械翻訳し、難易度レベル以下の入力文を原文のまま出力する。
(もっと読む)
機械翻訳の方法およびシステム
言語間の解析モデルを生成し、目的言語にソース言語を機械翻訳するモデルを使用するためのシステムおよび方法が提供される。システムおよび方法は、ソース言語の文の受容、および、各々が目的言語の単語、統語上のラベル、および、要素間の関係を示す役割ラベルで分類される要素を有する候補解析の言語間の解析モデルでの検索および統計学的なランク付けを含む。統計学的に高ランクの解析は、ソース言語の文の言語間の解析を生成するため、目的言語の語順規則に従って統語上のおよび役割ラベルを用いて選ばれ、再配置される。  (もっと読む)
(もっと読む)
文章構造解析装置、およびプログラム
【課題】従来の文章構造解析装置においては、構造解析を高精度に行うことができない、という課題があった。
【解決手段】文章情報を分割して取得した1以上の各節情報に対して、一の節情報が含む最終の文節情報を除く文節情報が、当該一の節情報以外の他の節情報が有する文節情報にかかるか否かを、前記被係受文節情報を用いて判断し、一の節情報が含む最終の文節情報を除く文節情報が、当該一の節情報以外の他の節情報が有する文節情報にかかるとの判断の場合、当該一の節情報を単独で構文解析し、前記他の節情報が有する文節情報にかかると判断された文節情報と対になる被係受文節情報を取得し、取得した被係受文節情報を、対応する被係受文節情報に置き換え、出力する1以上の文節情報と被係受文節情報との組を1組以上得て、当該得た情報を出力する文章構造解析装置により、構造解析を高精度に行うことができる。
(もっと読む)
応答生成装置、方法及びプログラム
【課題】コストをかけることなくユーザと円滑に対話を行う。
【解決手段】応答生成装置は、複数の発話候補を生成する応答生成部14と、複数の発話候補から1つの応答発話を選択する応答選択部15と、概念毎に「話題の豊富さ」及び「感情」を定義する概念データベース16と、を備えている。応答選択部15は、概念データベース16を参照して、発話候補に含まれる概念の「話題の豊富さ」及び「感情」を用いて、発話候補の優先度を決定し、最も優先度の高い発話候補を応答発話する。
(もっと読む)
機械翻訳編集装置、機械翻訳編集プログラム及び機械翻訳編集方法
【課題】マークアップ記号とテキスト部分とが混在する文書の編集の効率化を図る。
【解決手段】タグ種別判定部222は、テキスト原文から分離された単語がタグの場合、当該タグの種別を判定する。単語リスト生成部223は、分離された単語の各々を、当該単語がタグまたはテキスト部分のいずれであるかを示すと共に、タグの場合にはタグ種別を示す種別情報と関連付けてバッファ部34に格納する。原文/訳文単語リスト生成部225は、テキスト原文の訳文の生成時に、当該訳文内に反映されるタグを文内タグに制限し、文外タグを除く単語の群を含む原文単語リスト、及びテキスト部分としての単語の訳語と当該訳語のうち文内タグが付加された単語の訳語に付加されるタグとを含む訳文単語リストを生成してバッファ部34に格納する。システム制御部は、原文単語リスト及び訳文単語リストに基づいてそれぞれ原文及び訳文を編集可能に表示する。
(もっと読む)
機械翻訳における文法上問題のある文章の翻訳精度向上
【課題】 現在の機械翻訳は構成文法に従って句単位で翻訳されるため、文法上正しくない文章は翻訳精度が著しく低下する。しかし、実際に公開されている文章や電子メール、ホームページなどにおいて文法上正しい文章というものはほとんど存在しておらず、翻訳精度の向上の障害となっている。
【解決手段】構成文法に拠らない翻訳を行う。WardGrammar理論に従い、句よりも小さな単位である語を用い、語の相互関係から文法上正しくない文章についての翻訳精度を向上させる。
(もっと読む)
応答生成装置、方法及びプログラム
【課題】コストをかけることなくユーザと円滑に対話を行う。
【解決手段】応答生成装置は、ユーザ発話から音声信号を生成するマイクロホン11と、マイクロホン11から出力された音声信号を認識する認識部12と、ユーザ発話を解析して述語及び格要素を抽出する解析部13と、抽出された述語又は格要素を確認するための応答を生成する応答生成部14と、応答発話を音声出力するスピーカ21と、応答発話を画像出力するディスプレイ22と、を備えている。
(もっと読む)
翻訳プログラム
【課題】従来の翻訳プログラムでは、特殊分野の特定用語や、特定の文法用法について適切に翻訳をすることが困難であった。
【解決手段】本発明の翻訳プログラムは、翻訳対象文章に対し、翻訳前に、特定単語DB4によってコード化を実行し、特定用法DB5によって文体に応じた修正を行う。そして、翻訳後に、コード化がされている場合は逆コード化を実行し、また、修正のために加筆した特定文字がある場合は、当該特定文字を削除する。
(もっと読む)
分散収集された知識を用いる自動文法生成
【課題】文法創作プロセスを自動化するシステム及び方法を提供する。
【解決手段】本発明は、分散データベースから受け付けた応答に基づく第1のタスクを示す第1のデータを受け付けるステップと、第1のタグ付けされたデータを形成するために前記第1のデータに品詞を自動的にタグ付けするステップと、前記第1のタグ付けされたデータから、繋ぎ語及びコア語を識別するステップと、第1の組の規則を使用して前記第1のタグ付けされたデータに基づく文章構造をモデル化するステップと、前記コア語の同義語を自動的に識別するステップと、前記モデル化された文章構造、第1のタグ付けされたデータ及び同義語を使用して、前記第1のタスクのための文法を創作するステップと、を有する、前記第1のタスクに関連付けられた文法を自動的に生成するためのコンピュータベースのシステム又は方法を含む。
(もっと読む)
81 - 100 / 152
[ Back to top ]