
Fターム[5K027HH20]の内容
Fターム[5K027HH20]に分類される特許
141 - 158 / 158
PTTサービスのための移動通信端末機の発言権管理装置及び方法

【課題】 使用者により入力される音声を認識するためにPTT端末が使用する資源を最小化できる、PTTサービスのための移動通信端末機の発言権管理装置及び方法を提供する。
【解決手段】 音声認識プロセッサを有するPTT端末に、マイクから音声が入力されるとトリガ信号を発生する音声活性検出器を含ませて、音声認識プロセッサを、入力される音声によりトリガ信号が発生する時点から所定時間駆動して、入力される音声を確認する。ここで、入力される音声が発言権の要求又は解除に関する音声であると、PTT端末のメインプロセッサ部が発言権要求メッセージ又は発言権解除メッセージをPTTサーバーに転送する。
(もっと読む)
アプリケーションに対するマルチモーダルアクセスを可能にするフレームワーク

【課題】オーディオ対応デバイスをスピーチ駆動アプリケーションにリンクさせる方法および装置を提供する。
【解決手段】一実施形態において、これは、オーディオ対応デバイス独立およびスピーチアプリケーションプラットフォーム独立パラメータのうちの特定のものを指定することなく、デジタル化スピーチオーディオを受け取り、送出する音声フレームワーク110を使用することにより達成される。音声フレームワーク110は、受け取ったデジタル化スピーチオーディオをコンピュータ読取可能テキストに変換する。さらに音声フレームワーク110は、スピーチ駆動アプリケーション独立およびスピーチアプリケーションプラットフォーム独立パラメータのうちの特定のものを指定することなく、コンピュータ読取可能テキストを受け取り、スピーチ駆動アプリケーションに送出する。音声フレームワーク110は、次に、コンピュータ読取可能テキストを変換する。
(もっと読む)
携帯型通信装置及び携帯型通話装置
【課題】 音声認識機能を用いると共に、簡単な操作で多様な処理を実行させ得るようにすること。
【解決手段】 記憶部24には操作部で操作した一連の操作をマクロとして記憶すると共に、音声入力部から入力した音声を前記マクロに対応付けたキーワードとして記憶する。制御部21は、音声入力部22から入力された音声が記憶部24に記憶された音声に一致するとき、該音声に対応付けられたマクロを実行する。また、着信後所定時間経過したときに伝言メモ機能を実行して伝言受付状態とし、前記伝言受付状態のときに通信回線を介して受信した音声が記憶部24に記憶された音声キーワードに一致すると判断したとき、自己の位置情報を所定のメールアドレスに送信する。
(もっと読む)
移動通信サービスシステム
【課題】安価に移動通信を行うことができる移動通信サービスシステムを提供することにある。
【解決手段】移動通信サービスシステム1において、複数の携帯電話200は、少なくとも1つのMMSSサーバ100によってインターネット400を介して通信可能に接続可能である。複数の携帯電話200は、各々、マイク220が音声を抽出して音声信号とし、無線通信部250がインターネット400を介してMMSSサーバ100との間で音声信号を送受信する。MMSSサーバ100は、ポータルサーバ110の通信部113がインターネット400を介して音声信号を複数の携帯電話200との間で送受信し、MMSSサーバ100のメッセンジャーサーバ150の通信部152は、音声信号をインターネット400を介して互いに送受信する。
(もっと読む)
通話装置,中継処理装置,通信認証システム,通話装置の制御方法,通話装置の制御プログラム,および通話装置の制御プログラムを記録した記録媒体
【課題】 特定個人の音声を認識するために、該特定個人に、音声の登録を要求するなどの煩雑な処理を必要とすることなく、特定個人の音声の認証を高精度に行える安価な通話装置を提供する。
【解決手段】 本発明の携帯電話2は、音素辞書33に基づき、入力された音声がユーザの音声であるか否かの認証を行う適合率計測確認部45と、特定個人の通話中の音声を取得する音声入力部25と、取得された音声に基づき、特定話者サンプル情報36を作成し音素辞書33を更新するサンプル作成部44とを備えている。
(もっと読む)
電話機
【課題】 素早く発信者を特定することができる電話機を提供する。
【解決手段】 受信部により受信された着信信号から発信電話番号を取得し(S21)、その発信電話番号と記憶部に記憶されている許可電話番号とを比較する(S22)。それらが一致しなかった場合(S22のN)、受信部による音声信号の受信を許可し(S23)、受信部により受信した音声信号から個人性特徴データを抽出して(S26)、その個人性特徴データと記憶部に記憶されている話者モデルとを比較する(S27)。その比較結果に応じて呼出音Aを呼出音B又は呼出音Cに変更し(S28,S29)、その呼出音で呼出部に呼出動作を実行させるようにした(S31)。
(もっと読む)
個人認証システム
【課題】 セキュリティレベルの更なる向上が可能であり、かつ、生きた本人が直接操作しない限り、セキュリティ突破することが困難な個人認証システムを提供する。
【解決手段】 接触式生体特徴情報検出部342,343、顔撮影カメラ341、骨伝導音検出部340及び気導音検出部304の4種類を認証用特徴情報取得部の母群として、これから少なくとも2種を選択して携帯電話1に設ける。そして、電話使用把握保持状態にて、指定された少なくとも2つの認証用特徴情報取得部による認証用特徴情報の取得を同時に実行し、それら認証用特徴情報の取得が同時になされていない場合には、認証処理対象者の受理認証(例えば、正規ユーザであるとの認証)を行なわないようにする。
(もっと読む)
電話機
【課題】 送話者が特定の送話内容について文字化を行いたい場合、特定の送話内容のみを文字化して受話者に対して表示する電話機を提供する。
【解決手段】 送信側電話機からの通話内容を示す音声データに付加された、識別情報により文字化するかどうかを判断する制御手段と、音声データを音声として出力するスピーカ手段と、音声データを音声認識する音声認識手段と、制御手段は、識別情報により音声データを文字化すると判断した場合、音声認識手段により音声認識されたデータを、文字として文字表示手段に表示するための文字データに変換し、文字データを文字表示手段に送り、文字表示手段にて文字として表示する。
(もっと読む)
通話送受信方法および通話端末
【課題】特殊なマイクロフォンなどを用いることなく、話し手や聴き手の周囲に騒音が存在する場合の通話の明瞭度を向上させる。
【解決手段】送話音声信号とともに、話し手の口唇1を送話用のマイクロフォン124の近傍に設けたカメラ126によって撮影して得た口唇動画像信号を送信し、受信側で表示部218上に口唇1の動きを動画像2として表示する。口唇動画像信号の代わりに、これから口唇1の動きを検出して生成した動きパラメータを送信し、受信側で、CGによって口唇1の動きを示す絵柄または図形を生成表示し、または表示部218を点滅させてもよい。送話音声信号の代わりに、送話音声信号の音声認識結果のテキスト情報、または、このテキスト情報からテキスト音声合成によって生成した合成音声信号を送信し、受信側で合成音声信号による音声を出力させてもよい。
(もっと読む)
携帯端末装置
【課題】 従来は各機能画面毎に異なる入力キーによる画面遷移先処理を行い、該当の機能画面を表示する処理を行うことはできない。また、複数の機能画面をユーザの使い勝手に合わせて集約することができない。
【解決手段】 携帯端末装置における制御部3は、キー入力部1より入力されたキーコードあるいは通話部2より入力された音声データにより、キーコード認識部3aでは、入力されたキー操作により、音声処理部3dでは通話部2より入力された音声データにより処理し、ユーザメニュー処理部3cで登録されたデータに基づき、該当の機能画面を表示させるように処理する画面制御部3bにより、表示部4に表示する。制御部3は設定したデータに付随して音声データと機能名称を登録することにより、キー操作だけでなく音声入力により該当の機能画面を表示部4に表示させることができる。
(もっと読む)
ハンズフリー・プレス・トーク方式の機能のための装置および方法
ハンズフリー・プレス・トーク方式の機能のための装置は、前もってセットされた可聴信号、センサまたはスイッチの予め決められた動き、空気圧などの少なくとも1つにより動作するプレス・トーク方式のセンサまたはスイッチを含む。この装置はプレス・トーク方式のセンサまたはスイッチからの信号に応じて通信装置の動作を制御する手段を含んでもよい。  (もっと読む)
(もっと読む)
ショートメッセージサービスを通じる音声
移動体通信デバイスによる音声メッセージの送信方法に関する。この方法には、移動体通信デバイスのユーザから発話を受信する工程と、受信した発話の非文字表現を生成する工程と、非文字表現を文字メッセージの本体へ挿入する工程と、無線メッセージングチャネルを通じて移動体通信デバイスから受信者のデバイスへ文字メッセージを送信する工程とが含まれる。  (もっと読む)
(もっと読む)
マルチモーダル埋め込み型インタフェースの交換可能なカスタマイズ用の方法及び装置
本発明の一定の態様では、移動体音声通信デバイスは、聴覚的な情報及びデータを送受信するための無線トランシーバ回路と、プロセッサと、プロセッサ上で実行されると移動体音声通信デバイスに、ユーザインタフェースと関連付けられている選択可能な個性を移動体音声通信デバイスのユーザに対し提供させる実行可能な命令を記憶するメモリとを備える。実行可能な命令には、選択可能な個性を有する異なるユーザプロンプトを用いるユーザインタフェースを移動体音声通信デバイス上に実装することが含まれる。異なるユーザプロンプトの選択可能な個性の各々は移動体音声通信デバイスにおける1つ以上のデータベースに記憶されているデータに対し規定及びマッピングされる。この移動体音声通信デバイスは、発声されたユーザ入力を認識し、対応する認識された語を出力するデコーダと、認識された語に対応する語を合成する発声シンセサイザとを含み得る。このデバイスはデバイスに対し無線送信されるか、コンピュータインタフェースを通じて送信されるか、又はメモリカードとしてデバイスに対し提供されるユーザ選択可能な個性を含む。  (もっと読む)
(もっと読む)
ノイズの大きい環境における電話機の拡張された使用
電話機(100)の使用を拡張する方法が提供される。本方法は、着信通話を受信するステップと、周囲のノイズレベルを検出するステップと、前記検出された周囲のノイズレベルが所定の閾値ノイズレベルより大きい場合に、前記着信通話が前記着信通話の受信者によってより理解可能となるように該着信通話を強調するステップとを含む。前記強調するステップは、前記着信通話の受信者に対する前記着信通話の音量を自動的に増幅するステップ、及び/又は前記着信通話をテキストに変換し前記着信通話の受信者に対して前記テキストを表示するステップを含んでも良い。 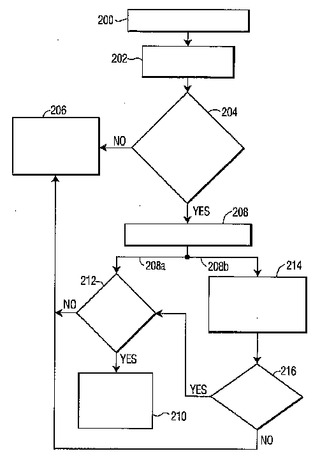 (もっと読む)
(もっと読む)
携帯電話機に関連するカメラの可聴制御のシステム及び方法
ディジタル・カメラ114をオーディオ制御又はボイス制御を介して制御できる、組合せ携帯電話機100及びディジタル・カメラ114。携帯電話機100に、可聴入力を検出する少なくとも1つのマイクロホン106、118が含まれる。検出された可聴入力が、電気信号に変換され、プロセッサに送られる。プロセッサは、検出された可聴入力をプロセッサに操作させるソフトウェアを含む記憶媒体にアクセスできる。プロセッサは、検出された可聴入力をカメラ・コマンドのデータベース412と比較して、検出された可聴入力がデータベース内のカメラ・コマンドの1つと一致するかどうかを判定する414。一致がある場合には、プロセッサは、カメラ・コマンドに関連する一連の命令を実行504して、所望の機能を実行する。  (もっと読む)
(もっと読む)
音声認識環境において用いるための無線ヘッドセット
装置(10、20)と通信するためのヘッドセット(16)は、ユーザの音声を検出するためにヘッドセット(16)によって取得されたオーディオ信号を処理し、概して、ユーザの音声が検出された場合にのみ、取得されたオーディオ信号のサンプリングされた表示を装置(10、20)に送信するよう構成されている。 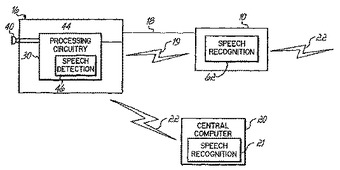 (もっと読む)
(もっと読む)
端末装置と通信制御方法
【課題】音声認識を利用することで、相手の会話の内容を明確に知ることができ、聴き取りが困難な環境下でも通話可能とする端末装置及び通信制御方法の提供。
【解決手段】圧縮符号化されて伝送された通話相手の音声信号を受信回路8で受信し、復調回路9及び伸長回路10で復調及び伸長されたデジタル音声信号を受け取って音声認識し、テキストデータに変換する音声認識回路15を備え、制御部14は、音声認識回路15で変換されたテキストデータを受けとり該テキストデータを表示部16に表示させる制御を行う。
(もっと読む)
介護用携帯電話機
【課題】 介護を要する老人等の被介護者と遠隔地にいる介護者間のコミュニケーションを補助するための介護用携帯電話機を提供する。
【解決手段】 特定の発信者から発信された電子メールを受信した場合に、この電子メールの内容を音声化して音声出力するメール音声化手段と、被介護者の音声を受けた場合に、この音声を文書データに変換し、さらにこの文書データを電子メールに含め発信者に向け返信し、被介護者による所定のボタン操作を受けた場合に、このボタン操作に応じたメッセージを電子メールに含め発信者に向け返信する応答手段とを備える。
(もっと読む)
141 - 158 / 158
[ Back to top ]