
再構成デバイス、処理配置方法及びプログラム

【課題】再構成デバイスの回路構成変更において、機構追加による回路規模を増やすことなく、処理内容に対する依存を回避しつつ回路構成変更期間を短縮する。
【解決手段】外部メモリ101は、内部に回路構成情報106を保持している。回路構成情報106は再構成デバイス105を構成する要素を動作させる設定群である。コンフィギュレーションコントローラ102は上記メモリ101から結線104を通じ回路構成情報106を取得する。取得した回路構成情報106は結線103を通じて再構成デバイス105へ送られる。
【解決手段】外部メモリ101は、内部に回路構成情報106を保持している。回路構成情報106は再構成デバイス105を構成する要素を動作させる設定群である。コンフィギュレーションコントローラ102は上記メモリ101から結線104を通じ回路構成情報106を取得する。取得した回路構成情報106は結線103を通じて再構成デバイス105へ送られる。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、回路構成を変更することができる再構成デバイス、その処理配置方法等に関する。
【背景技術】
【0002】
従来から製造後のLSI回路装置であっても内部の回路構成を変更することで、上記回路が行う処理内容を変更することが可能な再構成デバイスが提案されている。製造後のLSI回路装置でも処理を変更することが可能であるため、仕様変更などに伴うLSIの作り直しを行わなくて済む。製造コストを抑えることが可能な点や開発期間が短縮可能な点で、現在様々な分野において再構成デバイスが使用されている。
【0003】
再構成デバイスの構成として、多数のLUT(Look−Up−Table)を搭載したタイプや多数のプロセッシングエレメントを搭載したタイプが代表的である。また各々のエレメントにはマルチプレクサなどのスイッチングエレメントが接続されている。ここではLUTやプロセッシングエレメント、スイッチングエレメントなどの各構成要素を動作させるための設定を総称し回路構成情報と呼んでいる。回路構成情報の生成方法としては様々あるが、一般に(1)テクノロジーマッピングと呼ばれる論理的な処理の割り当て、(2)各構成要素への物理的な配置、(3)各構成要素の経路決定、の工程に分けられ、順番に行われことが多い。上記三つの工程を経て最終的に回路構成情報が生成される。
【0004】
(1)論理的な処理の割り当て工程では、処理を構成要素に割り当てることを行う。具体的には、各処理を物理的な構成要素を特定せずに論理的な構成要素に割り当てる。順序変更の指標としては、回路面積、動作速度、消費電力の観点が一般的である。(2)配置工程では、再構成デバイス内のどの構成要素でどの処理を行うかの物理的な割り当てを決定する。データの入出力関係にある処理が配置されているプロセッシングエレメント間の距離によって、データ通信に係るスイッチングエレメント数が異なるため、遅延時間(最大動作周波数)が大きく変化する。そのため、通常は入出力関係のある処理はできる限り近い距離のプロセッシングエレメントに配置させることが遅延時間を短縮する上で重要となる。(3)経路決定の工程では、データ通信の入出力関係にあるプロセッシングエレメント間のデータ通信のため、スイッチングエレメントによる経路を決定する。配置工程と比べ具体的な経路を決定するため、プロセッシングエレメント間の遅延時間を短縮した経路を決定することが重要となってくる。
【0005】
近年、集積度の向上に伴い、再構成デバイスにおいて実行可能な処理の規模は増えている。しかし、最近ではそれにも増して、処理自体への要求が複雑化・高度化しており、一つの再構成デバイスで全ての処理を一度に行うことは難しい場合がある。これに対して、一つの再構成デバイスにおいて時分割で処理を順々に行う方法がある。より具体的にはまず所望の処理を分割し、分割した処理に対応した回路構成情報を生成する。その後、回路構成情報に基づいた再構成デバイスの回路構成の変更、処理を順々に行っていく。これにより、再構成デバイスで大きな規模の処理を行うことが可能となる。しかしながら、毎回全ての回路構成を変更させていては全体の処理時間が長くなってしまい、速度性能が劣化してしまう。また上記の処理分割数が多い場合も同様に、処理速度の劣化を生じさせてしまう。
【0006】
この問題を解決するための方法として、マルチコンテキスト型の再構成デバイスがある。コンテキストとは、回路構成情報のことで、マルチコンテキスト型の再構成デバイスとは、複数の回路構成情報を格納するメモリを再構成デバイス内に搭載したものである。回路構成を変更する場合には、上記メモリを切り替えてデバイスを再構成することが可能であり、高速に切り換え可能なことで回路の再構成時間を大幅に短縮することが可能である。しかし、追加で回路構成情報用のメモリを搭載する必要があるため、回路規模が増大する問題がある。
【0007】
これに対し、特許文献1では、再構成時間を短縮する方法としてスケルトン回路技術に基づいた手法が提案されている。この手法では、先行ベース回路と呼ばれる回路構成情報を、予め再構成デバイスに構成しておく。ここで先行ベース回路とは複数の回路構成情報において全てに共通する共通回路部分と、複数個の回路で互いに共通せず、かつ、再構成デバイス上で回路構成情報を共有しない非排他的独立回路部分からなる回路構成情報のことである。再構成デバイス上において回路の差分のみを部分的に再構成することにより、処理に必要な回路を構成するようにする。この方法は、マルチコンテキスト型に比べ、追加で構成用のメモリを必要としないため回路規模が増大はしない。
【先行技術文献】
【特許文献】
【0008】
【特許文献1】特許第3558119号公報
【発明の概要】
【発明が解決しようとする課題】
【0009】
しかしながら、一般に再構成デバイスでは様々なアプリケーションを実行する可能性があり、アプリケーションによっては共通部分が少なくなる。また、再構成すべき回路構成情報の数もアプリケーションによって異なる。特許文献1で述べられている先行ベース回路部生成において、共通部分が少ないもしくは、回路構成情報の数が多く再構成デバイスの回路規模を大幅に超えてしまう場合には回路構成を変更するための期間を効率的に削減することが難しい。また、上述した処理配置工程においては、回路構成の変更期間を削減することに加え、データ入出力関係にあるプロセッシングエレメント間の距離が近い必要がある。入出力に係るプロセッシングエレメント間の通信距離が遠い場合、データ通信の遅延時間を増やし、結果として処理全体の期間を増大させてしまう。
【0010】
本発明は上述した問題点に鑑みてなされたものであり、回路構成変更の順序を考慮することで、プロセッシングエレメント間のデータ通信遅延を抑えつつ回路規模を増やすことなく回路変更期間を効率的に削減することを目的とする。
【課題を解決するための手段】
【0011】
本発明の処理葉位置方法は、複数の構成要素で構成される再構成デバイスに対し、データフローの各処理を行う構成要素を決定するための処理配置方法であって、少なくとも二つの異なるデータフローと前記データフローの処理順序を入力する入力ステップと、再構成デバイスの構成要素の制約を入力する制約ステップと、前記データフローに応じた、前記再構成に必要な設定変更数と前記データフローのデータ入出力の依存関係に基づく構成要素間の距離とを用い、構成要素の配置を決めることで、要求される処理をどの構成要素で実行させるかを決定する決定ステップとを有することを特徴とする。
【発明の効果】
【0012】
本発明によれば、データ通信の遅延時間を抑えつつ再構成に必要な設定数を減らすように回路構成情報を作成することで、回路規模を増やすことなく再構成デバイスの再構成期間を短縮することが可能である。
【図面の簡単な説明】
【0013】
【図1】再構成デバイスを含む処理装置の構成例を示す図である。
【図2】再構成デバイスの構成例を示す図である。
【図3】再構成デバイスのエレメント間のデータ通信の手順例を示す図である。
【図4】プロセッシングエレメントの構成例を示す図である。
【図5】コンフィギュレーションコマンドのフォーマット例を示す図である。
【図6】プロセッシングエレメントのコンフィギュレーションメモリに格納される設定の概要例を示す図である。
【図7】設定を読み書きする手順を示すフローチャートである。
【図8】スイッチングエレメントの構成例を示す図である。
【図9】スイッチングエレメントのコンフィギュレーションメモリに格納される設定の概要例を示す図である。
【図10】データフローにおける処理のプロセッシングエレメントへの配置例を示す図である。
【図11】複数のデータフローを順次処理するタイムチャートである。
【図12】処理配置に向けたプロセッシングエレメントアレイのモデル例を示す図である。
【図13】第1の実施形態における複数のデータフローの処理配置を行うための概要例を示す図である。
【図14】第1の実施形態における処理配置を行うためのフローチャートである。
【図15】第2の実施形態におけるデータフローの処理配置を行うための概要例を示す図である。
【図16】第3の実施形態におけるデータフローの処理配置を行うための概要例を示す図である。
【図17】第4の実施形態におけるデータフローの処理配置を行うための概要例を示す図である。
【図18】第5の実施形態におけるデータフローの処理配置範囲限定を行うための概要例を示す図である。
【図19】回路構成情報を作成する装置の構成の一例を示すブロック図である。
【発明を実施するための形態】
【0014】
以下、本発明を適用した好適な実施形態を、添付図面を参照しながら詳細に説明する。
【0015】
先ず、本発明の第1の実施形態について説明する。第1の実施形態に係る再構成デバイスを有するシステムの全体構成の例を図1に示す。外部メモリ101は、内部に回路構成情報106を保持している。回路構成情報106は再構成デバイス105を構成する要素を動作させる設定群である。コンフィギュレーションコントローラ102は上記メモリ101から結線104を通じ回路構成情報106を取得する。取得した回路構成情報106は結線103を通じて再構成デバイス105へ送られる。ここで再構成デバイス105の例としてプロセッシングエレメントアレイとしている。また以下では、具体的にプロセッシングエレメントアレイ内の説明をするが、本発明は下記の各プロセッシングエレメントの構成や経路構成に限定されるものではない。
【0016】
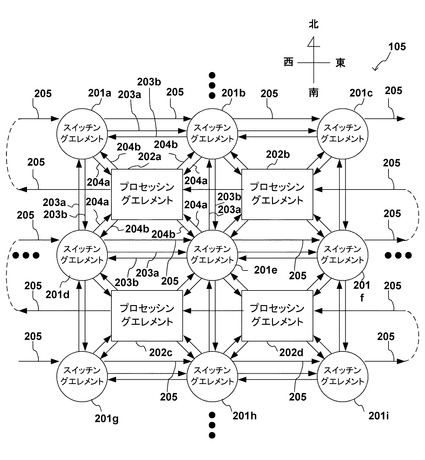
図2に、本実施形態における再構成デバイスであるプロセッシングエレメントアレイの概要図を示す。再構成デバイスには、8入力8出力の入出力処理手段であるスイッチングエレメント201が二次元格子状に配置されている。演算処理手段である4入力4出力のプロセッシングエレメント202が、スイッチングエレメント201の格子内に配置されている。スイッチングエレメント201a〜iの8入力8出力は1入力1出力を一組としてそれぞれ東西南北(右左下上)方向の、他の4つのスイッチングエレメント201と結線203aおよび203bを介して夫々接続されている。
【0017】
さらに、北東、南東、南西、北西方向の、それぞれ別の4つのプロセッシングエレメント202と結線204aおよび204bを介して双方向に接続された構成を持つ。またスイッチングエレメント201a〜201iおよびプロセッシングエレメント202a〜202dは結線205で一方向に数珠繋ぎに接続されている。
【0018】
結線203a、203bおよび結線204a、204bはスイッチングエレメント201やプロセッシングエレメント202の間で処理対象データを通信するために接続された結線である。結線205は、スイッチングエレメント201やプロセッシングエレメント202に設定を供給するための結線である。
【0019】
上述の設定によって、スイッチングエレメント201においては処理対象データの入出力先が決定され、プロセッシングエレメント202においては処理対象データの入出力先や処理内容が決定される。なお、図2の各結線203a、203b、204a、204b、205の矢印の方向はデータの方向を示している。またスイッチングエレメント201a〜201iはそれぞれ同じ構成を有し、プロセッシングエレメント202a〜202dはそれぞれ同じ構成を有する。
【0020】
ここで、各結線203a、203b、204a、204b、205の通信プロトコルの一例として、Valid信号とReady信号による2線ハンドシェークを図3に示す。図3では送信側であるモジュールA301と受信側であるモジュールB302間はデータ信号線303、Valid信号線304およびReady信号線305が接続されている。Valid信号はValid信号線304を通じ送信側が受信側に対し送信可能状態を示す信号である。Ready信号はReady信号線305を通じ受信側が送信側に対しデータ受信可能状態を示す信号である。本プロトコルではモジュールA301からのValid信号線304とモジュールB302のReady信号線305とが両方有効となるクロック立ち上がりのタイミングでデータ信号線303のデータがモジュールA301からモジュールB302へと送信される。図3の波形中では306aのタイミングでデータAが、306bのタイミングでデータBが、306cのタイミングでデータC、306dのタイミングでデータDがモジュールA301からモジュールB302へと転送されている。
【0021】
プロセッシングエレメント202の構成を図4に示す。プロセッシングエレメント202は、コンフィギュレーションユニット401、インプットユニット402、コンピュテーショナルユニット403、アウトプットユニット404、テンポラリーバッファ405で構成されている。前記コンフィギュレーションユニット401はプロセッシングエレメント202の動作内容を決定するための設定の管理を行う。前記インプットユニット402はコンフィギュレーションユニット401の設定に基づき、入力処理を行う。コンピュテーショナルユニット403はコンフィギュレーションユニット401の設定に基づき、演算処理を行う。また、コンピュテーショナルユニット403は、再度コンピュテーショナルユニット403に入力するためテンポラリーバッファ405に処理された結果を保持することが可能である。アウトプットユニット404はコンフィギュレーションユニット401の設定に基づき、出力処理を行う。
【0022】
上記プロセッシングエレメント202の動作をより具体的に説明する。インプットユニット402はコンフィギュレーションユニット401から入力先を決定するための設定情報を、結線406を通じて取得する。取得した設定情報はどの入力ポートを介して外部接続されているモジュールと通信を行うかが指定されている。その情報を元に、結線204a−ne、204a−se、204a−sw、204a−nw、を通じて処理対象であるデータを取得する。ここで参照符号のne,se、sw,nwはそれぞれ方向を示しており、結線204a−neは北東に配置されたスイッチングエレメントと接続されている。また、204a−seは南東に配置されたスイッチングエレメントと接続されている。204a−swは南西に配置されたスイッチングエレメントと接続されている。204a−nwは北西に配置されたスイッチングエレメントと接続されている。取得したデータは、結線409を通してコンピュテーショナルユニット403に送られる。
【0023】
コンピュテーショナルユニット403は、コンフィギュレーションユニット401から処理内容を決定するための設定情報を、結線407を通じて取得する。取得した設定情報に基づいてインプットユニット402から送られてくるデータを取得し、処理を行う。処理したデータは結線410を通じてアウトプットユニット404に送られる。
【0024】
コンピュテーショナルユニット403は、少なくとも一つの演算器を保持している。上記演算器は、例えば、加減算器、比較器、乗算器、除算器、論理演算器等の演算器、または、これらの組合せからなる演算器、さらにはこれらと他の演算器の組合せからなる演算器などである。以下では具体的な例として、上記コンピュテーショナルユニット403では、積和演算と比較演算処理が行え、一度の演算でどちらかを一方を選択的に行うことができるものとし説明する。積和演算では、a・b+c・dの処理を行い、比較演算では、もしa>bならばcを出力、そうでなければdを出力するといった処理を行う。また、コンピュテーショナルユニット403は一度の入力に対して、上記演算器を繰り返し使用することが可能な構成となっている。繰り返しで使用する場合は一旦上記演算器で使用された処理結果を、結線412を通して、テンポラリーバッファに保存し、その後、結線411を通して、再度コンピュテーショナルユニット403に入力する。再度入力されたデータに対して、新たに上記演算器にて処理を行う。後で詳細を述べるが、上記設定とは上記演算の種類や繰り返し処理、またそれぞれの処理で必要な変数a、b、c、dはどの値を参照するか、また固定値ならばその値を指定することを意味する。
【0025】
アウトプットユニット404は、処理したデータの出力先を示す設定情報を結線408を通じて取得する。取得した設定情報は、どの出力ポートを介してスイッチングエレメントと通信を行うかが指定されている。その情報を元に、結線204b−ne、204b−se、204b−sw、204b−nw、を通じてスイッチングエレメントへ出力する。ここで結線204b−neは北東に配置されたスイッチングエレメントと接続されている。また、204b−seは南東に配置されたスイッチングエレメントと接続されている。204b−swは南西に配置されたスイッチングエレメントと接続されている。204b−nwは北西に配置されたスイッチングエレメントと接続されている。
【0026】
次にコンフィギュレーションユニット401の動作について説明する。コンフィギュレーションユニット401はプロセッシングエレメント202毎にユニークなIDを保持している。コンフィギュレーションユニットは入力側の結線205より送られてくる設定情報を取得し、コンフィギュレーションユニット内で処理し、出力側の結線205を通して設定を出力する。コンフィギュレーションユニット401は自らのIDに対応する設定を格納するためコンフィギュレーションメモリ413を有している。
【0027】
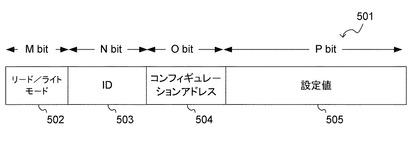
図5にコンフィギュレーションユニットに送受信される、設定のためのコンフィギュレーションコマンド501を示す。コンフィギュレーションコマンド501はリード/ライトモード502、ID503、コンフィギュレーションアドレス504、設定値505で構成されている。リード/ライトモード502はコンフィギュレーションコマンドの読み書きの処理を決定する信号である。ID503は処理対象のプロセッシングエレメント202を決める信号である。コンフィギュレーションアドレス504はコンフィギュレーションユニット401中の設定が保持されているメモリ内の番地を指定する信号である。設定値505は実際の設定値を表す信号である。図5中のビット幅を示すM、N、O、Pは実際に構成するアーキテクチャによって決められる値である。以下では上述した構成に基づく設定に関してより具体的に説明する。
【0028】
図6中の601はコンフィギュレーションメモリ413のアドレスを示しており、図5のコンフィギュレーションアドレス504で指定されるアドレスに相当する。602は実際の設定値を示しており、図5の設定値505に相当する。本実施形態はこれら一つ一つを設定と読んでいるが、本発明は上述の単位に限るものではない。図ではインプットユニット402、コンピュテーショナルユニット403、アウトプットユニット404に関する設定がコンフィギュレーションメモリ413に保持されている例を示している。
【0029】
アドレス0x0000_0000(“0x”は16進数を示している)で示した設定値は、インプットユニット402における入力先を決定するための設定情報で、この値に応じて所定の入力先が決まる。アドレス0x0000_0004で示したイタレーションナンバーは、コンピュテーショナルユニット403における、演算の繰り返し回数を決定するための設定情報で、値に応じて演算の繰り返し回数が決まる。本実施形態では4回までの演算を想定している。
【0030】
アドレス0x0000_0008で示したオペレーションセッティングは1度目の演算で行う、演算の種類を決定するための設定で、値に応じて積和演算か比較演算かが決まる。アドレス0x0000_000cで示したバリアブルセッティングは1度目の演算で、変数aの値の参照先を決めるための設定である。参照先としては、入力ポートからの入力値、コンフィギュレーションメモリ413に保持されている固定値、以前の計算結果が保持されているテンポラリーバッファの値がある。この値に応じて、上記いずれかの値がこの変数aに入力される。また0x0000_000cと同様に、0x0000_0010、0x0000_0014、0x0000_0018で示したバリアブルセッティングはそれぞれ、1度目の演算における変数b、c、dの値の参照先を決めるための設定である。
【0031】
次に0x0000_001cで示したパラメータは、1度目の演算において0x0000_000cで指定された参照先が固定値の場合の、変数aのための固定値である。0x0000_001cと同様に0x0000_0020、0x0000_0024、0x0000_0028で示した固定値は、それぞれ1度目の演算で変数b、c、d、で使用される場合の値である。
【0032】
続く0x0000_002c〜から0x0000_0094は、上記0x0000_0008〜0x0000_0028で示した1度目の演算に係る設定と同様にそれぞれ、2度目、3度目、4度目の設定値を示している。最後に0x0000_0098で示したアウトプットセレクトバリューは、アウトプットユニット404における出力先を決定するための設定値で、値に応じて所定の出力先が決まる。
【0033】
次にコンフィギュレーションユニットで行われる処理フローを図7に示す。ステップS701では、コンフィギュレーションコマンド501を入力する。ステップS702では、入力されたコンフィギュレーションコマンド501で指定されたID503が、コンフィギュレーションユニット401の持つ自身のIDと一致するかどうかを判断する。もし、ステップS702で自身のIDと違うと判断された場合はステップS711、712で、入力されたコンフィギュレーションコマンド501に対して、何も処理せずにそのまま出力する。もし、自身のIDと一致する場合は、次にステップS703でリード/ライトモード502の値がリードモードかどうかを判断する。リードモードでなければステップS707でライトモードかどうかを判断する。いずれのモードでもない場合はステップS711、712で何も処理せずにそのまま出力する。もし、リードモードと判断された場合は、ステップS704において、コンフィギュレーションメモリ413からコンフィギュレーションアドレス504で指定されたデータを読み出す。その後、ステップS705にて、入力されたコンフィギュレーションコマンド501の設定値505に読み出したデータを書き込み、ステップS706でそのコンフィギュレーションコマンド501を出力する。ライトモードと判断された場合は、ステップS708にて入力されたコンフィギュレーションコマンド501の設定値505をコンフィギュレーションアドレス504で指定されたコンフィギュレーションメモリ413に書き込む。次にステップS709では、入力されたコンフィギュレーションコマンド501の値を変更せず、ステップS710にて、そのまま出力する。一度のコンフィギュレーションコマンドで一つの設定値505を変更することが可能であり、順次コンフィギュレーションコマンドを送信し、必要な設定値を全て変更することで所望の処理を実現する。つまり、この設定数が処理内容の切り替え時間を決めていることとなる。
【0034】
スイッチングエレメント201の構成を図8に示す。スイッチングエレメント201は、コンフィギュレーションユニット801と、クロスバースイッチ802で構成される。コンフィギュレーションユニット801はデータを転送する接続先を決定するための設定値の管理をする。クロスバースイッチ802はコンフィギュレーションユニット801の設定に基づき一対一に入出力を接続する。プロセッシングエレメント202のコンフィギュレーションユニット401と同様、コンフィギュレーションユニット801はスイッチングエレメント201毎にユニークなIDを保持している。コンフィギュレーションユニットは入力側の結線205より送られてくる設定情報を取得し、コンフィギュレーションユニット内で処理を行い、出力側の結線205を通して設定値を出力する。コンフィギュレーションユニットは上記取得した設定をコンフィギュレーションメモリ804に保持している。コンフィギュレーションユニットのコンフィギュレーションコマンドとその処理フローは、図5に示したフォーマット、および図7に示した処理フローと同様である。クロスバースイッチ802はコンフィギュレーションユニット801からデータの入出力先を決定する設定情報を、結線803を通じて取得する。スイッチングエレメント201は取得した設定値に基づき結線203a−w、−s、203b−e、−n、結線204b−ne、−se、−sw、−nwを通じてデータを取得する。取得したデータは、接続されている結線203a−e、−n、203b−w、−s、結線204a−ne、−se、−sw、−nwを通じて渡す。
【0035】
ここで結線203a−w、−sはそれぞれ西、南に配置されたスイッチングエレメントと接続されていることを意味する。203b−e、−nはそれぞれ東、北に配置されたスイッチングエレメントと接続されていることを意味している。
【0036】
結線203a−e、−nはそれぞれ東、北に配置されたスイッチングエレメントと接続されていることを意味する。203b−w、−sはそれぞれ西、南に配置されたスイッチングエレメントと接続されていることを意味している。
【0037】
結線204a−ne、−se、−sw、−nwはそれぞれ北東、南東、南西、北西に配置されたスイッチングエレメントと接続されていることを意味している。結線204b−ne、−se、−sw、−nwはそれぞれ北東、南東、南西、北西に配置されたスイッチングエレメントと接続されていることを意味している。
【0038】
図9にコンフィギュレーションメモリ804に保持されている、スイッチングエレメント201におけるクロスバースイッチ802の入出力の接続に関する設定例を示す。901はメモリのアドレスを示しており、図5のコンフィギュレーションアドレス504で指定されるアドレスに相当する。902は設定値を示しており、図5の設定値505を示している。アドレス0x0000_0000で示したコネクション設定は結線203a−wからの入力を203a−e、n、203b−w、−s、204a−ne、−se、−sw、−nwのいずれに出力するかを決定するための設定値である。続く、0x0000_0004は結線203a−sからの入力を0x0000_0000と同様どの結線に出力するかを決定する設定値である。0x0000_0008は結線203b−eからの入力を0x0000_0000と同様どの結線に出力するかを決定する設定値である。0x0000_000cは結線203b−nからの入力を0x0000_0000と同様どの結線に出力するかを決定する設定値である。0x0000_0010は結線204b−neからの入力を0x0000_0000と同様どの結線に出力するかを決定する設定値である。0x0000_0014は結線204b−seからの入力を0x0000_0000と同様どの結線に出力するかを決定する設定値である。0x0000_0018は結線204b−swからの入力を0x0000_0000と同様どの結線に出力するかを決定する設定値である。0x0000_001cは結線204b−nwからの入力を0x0000_0000と同様どの結線に出力するかを決定する設定値である。
【0039】
次にデータフローの構成要素への配置の概要について図10を用いて説明する。ここで、配置とはデータフローの処理を、所定の配置で規定されるプロセッシングエレメントで実行させるかを決定することを意味している。図10ではデータフロー1001のノード1002、1003、1004、1005はそれぞれ一つのプロセッシングエレメントで行われる処理である。これらノード1002、1003、1004、1005に対応する処理を、再構成デバイス105のプロセッシングエレメント202−1、−2、−3、−4へ配置する例を示している。設定1006、1007、1008、1009はそれぞれ1002、1003、1004、1005の処理内容に対応したアドレス601、設定値602で構成されている。なお、各ノードで行う処理内容の割り当ては済んでおり、設定1006、1007、1008、1009は予め決められているものとしている。配置を決定することで、各設定の書き込み先であるプロセッシングエレメントに対応したID503を決定することが可能となる。
【0040】
上述した再構成デバイスの構成を複数種類変更して所望の処理を実現するためのタイムチャート例を図11に示す。図11では同一の再構成デバイスで複数の異なるデータフローA〜Zを順に実行しているタイムチャートを示している。本実施形態で扱うデータフローとは、再構成デバイスのプロセッシングエレメントに配置可能な単位で構成されたデータフローのことである。各データフローを処理するための設定は予め生成しておく。再構成デバイスに対して予め生成された設定に基づき再構成デバイスを再構成し、その構成のもとで処理をするという一連の処理が、所定の順序で順々に行われる。
【0041】
以下ではデータフローAを配置済みとし、データフローBを配置対象として説明する。具体的には、配置済みのデータフローAを実行するための設定値を参照し、データフローBの処理配置を決定する。データフローAの処理配置を参照しデータフローBの処理配置を決定した後、次はデータフローBを配置済みとし、データフローCを配置対象とする。具体的にはデータフローBの処理配置を決定した時と同様に、処理配置済みのデータフローBを実行するための設定値を参照し、データフローCの処理配置を決定する。上記の手順を順々に繰り返すことでAからZまでのデータフローの配置を行うことが可能となる。
【0042】
一般に、配置問題は配置のみを決定するだけでも解空間が広い。そのため、詳細配線決定を同時に行うと、良い解を算出できないだけでなく、解自体を算出できない可能性が出てくる。そのため本配置方法では詳細な配線情報は決定せず、図12に示す配置モデルに基づく概略の距離を用いて配置を決定する。本実施形態では配置モデルとしてプロセッシングエレメントアレイをプロセッシングエレメントの位置に基づいたマンハッタンモデルを用いている。プロセッシングエレメント間のマンハッタン距離を指標として解を算出する。ただし、本発明は、概略の距離としてはマンハッタン距離に限定されるものではない。指標として、詳細配線を同時に行うことも可能である。また、本実施形態では配置モデルとしてマンハッタンモデルに基づく配置モデルを用いたが、それに限るものではない。アーキテクチャに依存したモデルやユークリッド空間に基づいたモデルでも良い。
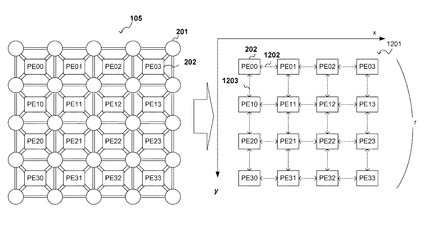
【0043】
図12に示すように、スイッチングエレメント201とプロセッシングエレメント202で構成される再構成デバイス105に対し、配置モデル1201を定義する。配置モデル1201はプロセッシングエレメント202のみで構成しており、指標となる距離としては、横方向のプロセッシングエレメント間の距離1202と縦方向の距離1203で表す。本実施形態では縦横の距離は等しいものとしているが、異なっても良い。また本発明で扱う距離とは、物理的な長さであっても良いし、各エレメント間の通信に要する時間の長さであっても良く、これらに限るものではない。
【0044】
次に、図12の配置モデルを用いて、図11のタイムチャートで示した処理の切り替わりに注目した処理のプロセッシングエレメントへの配置方法について述べる。
【0045】
図13では本実施形態における配置の概要を示している。データフローAはノード1301、1302、1303、1304として表される処理で構成されており、設定1305、1306、1307、1308はそれぞれのノードで行う処理の設定である。またフロー1309はノード1301と1302間のデータ入出力関係を表している。フロー1310はノード1301と1303間のデータ入出力関係を表している。フロー1311はノード1302と1304間のデータ入出力関係を表している。フロー1312はノード1303と1304間のデータ入出力関係を表している。
【0046】
データフローBはノード1313、1314、1315、1316として表される処理で構成されており、設定1317、1318、1319、1320はそれぞれのノードで行う処理の設定である。またフロー1321はノード1313と1315間のデータ入出力関係を表している。フロー1322はノード1314と1315間のデータ入出力関係を表している。フロー1323はノード1315と1316間のデータ入出力関係を表している。
【0047】
ここではプロセッシングエレメントアレイの配置モデル1201内の領域1324に上述のデータフローA、Bの処理を配置させることを想定している。本実施形態ではプロセッシングエレメントアレイ内の一部への配置について述べるが、それに限られるものではなく、複数の部分や全体への配置でも良い。1325は上記の領域1324のデータフローA向けの処理配置例を表している。1326は上記の領域1326のデータフローB向けの処理配置例を表している。各々の処理配置1325、1326内のプロセッシングエレメント1327、1328、1329、1330はそれぞれ物理的に同じプロセッシングエレメントを表している。処理配置1325では、データフローAにおいてはノード1301の処理をプロセッシングエレメント1327に配置させている。ノード1302の処理をプロセッシングエレメント1329に配置させている。ノード1303の処理をプロセッシングエレメント1328に配置させている。ノード1304の処理をプロセッシングエレメント1330に配置させている。またプロセッシングエレメント間のデータ通信の距離を、フロー1309は距離1331、フロー1310は距離1332、フロー1311は距離1333、フロー1312は距離1334として表している。
【0048】
続いてデータフローBに関しては、ノード1313の処理をプロセッシングエレメント1327に配置させている。ノード1314の処理をプロセッシングエレメント1328に配置させている。ノード1315の処理をプロセッシングエレメント1329に配置させている。ノード1316の処理をプロセッシングエレメント1330に配置させている。またプロセッシングエレメント間のデータ通信の距離を、フロー1321は距離1335、フロー1322は距離1336および1337、フロー1323は距離1338として表している。
【0049】
データフローAからデータフローBに処理が切り替わる際に、プロセッシングエレメント1327においては、設定変更1339で示すように設定1305から設定1317へと設定が変更される。プロセッシングエレメント1328においては、設定変更1341で示すように設定1307から設定1318へと設定が変更される。プロセッシングエレメント1329においては、設定変更1339で示すように設定1306から設定1319へと設定が変更される。プロセッシングエレメント1330においては、設定変更1339で示すように設定1308から設定1320へと設定が変更される。
【0050】
本実施形態では、配置を行う上で、処理が切り替わる際の設定変更数とデータフローの依存関係に基づく構成要素間の距離の二つの要素に注目する。
【0051】
本実施形態で用いる図13の例ではデータフローAは既に処理配置済みであり、データフローAに関する各プロセッシングエレメントの各メモリ内の設定値は固定値として与えられるものとする。データフローBに関しては処理配置対象である。つまりデータフローの処理順序は決まっており、既に配置済みの配置情報をもとに次に処理されるデータフローの配置を決定することを想定している。
【0052】
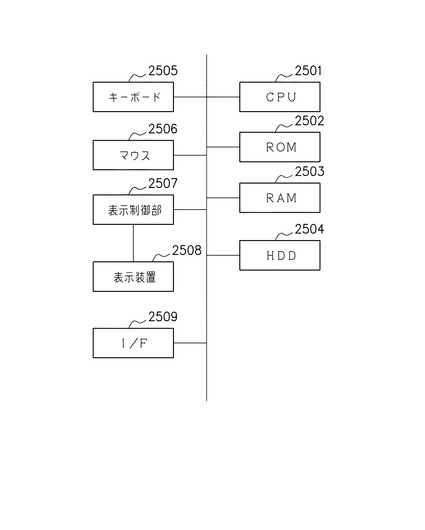
図19は、データフローからデータフローへ処理を切り替えるための回路構成情報106を生成するための装置のブロック構成図を示している。図19において、2501は装置全体の制御を司るCPUである。2502はブートプログラムやBIOSを記憶しているROMである。2503はCPU2501のワークエリアとして利用され、且つ、OS(オペレーティングシステム)、アプリケーションを格納するためのRAMである。2504はOS、回路構成情報106を作成するためのアプリケーション、ならびに、様々なデータを格納するためのハードディスクドライブ(HDD)である。2505はキーボード、2506はマウスであり、ユーザインタフェースとして機能する。2507は内部にビデオメモリ及び表示コントローラを内蔵する表示制御部であり、2508は表示制御部2507からの映像信号を受信し、表示するための表示装置である。2509は各種外部デバイスと通信するインタフェースであり、例えば、図1に示した外部メモリ101を接続することで、本装置が作成した回路構成情報106をその外部メモリ101に書込むことになる。
【0053】
上記構成において、本装置に電源が投入されると、CPU2501はROM2502に格納されたブートプログラムを実行し、HDD2504に格納されたOSをRAMにロードし、その後、回路構成情報106を作成するアプリケーションを起動することで、本装置が回路構成情報作成装置として機能することになる。
【0054】
以下、本発明を実施するための回路構成情報作成装置として機能する本装置の処理を、図14のフローチャートを用いて説明する。本手順はシミュレーテッドアニーリングに基づく処理配置方法の例を示すが、本発明は上記手法のみに限定されるものではなく、遺伝的アルゴリズムなどのさまざまな近似解法や線形計画法や非線形計画法など数値最適化法でも良い。また、配置する問題の規模に応じて方法を変えてもよい。
【0055】
図13に示す各データフローを表すインデックスをi、ノードのインデックスをj、図6のアドレス601や図9で示したアドレス901に相当するエレメント内で保持しているメモリのコンフィギュレーションアドレスをkとする。また、各ノードj間のフローに関するインデックスをlとする。上記より各メモリ内の設定値はui,j,kと表すことができる。またi番目のデータフローにおける、フローlの出発側のノードをSi,l、到着側のノードをdi,lとする。
【0056】
また、図12に示す通り、各プロセッシングエレメントを表すインデックスをrとする。各データフローiの各ノードjの配置位置はxi,jおよびyi,jと表すことができる。本実施形態では同じプロセッシングエレメントに同じデータフロー内の異なる処理を配置することはしないため、xi,j、yi,jは、ノードjごとに必ず異なる。つまり、同じプロセッシングエレメントに異なる処理を配置しない。
【0057】
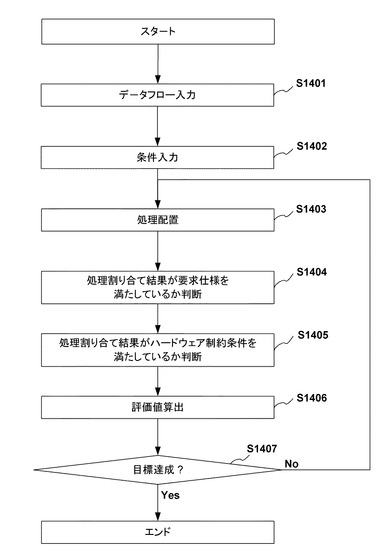
ここで処理配置済みのデータフローをi0、処理配置対象のデータフローをi1とする。初めに、ステップS1401では複数のデータフローとその順序関係(iの順序)を入力する。処理配置済みのデータフローに関しては、設定値ui0,j,kと共に配置情報xi0,j、yi0,jも入力する。
【0058】
次に、ステップS1402で要求仕様とハードウェアの制約の条件を入力する。ここでハードウェア制約条件とは、ヘテロ構成に伴う各プロセッシングエレメントが個別に持つ構成情報や、処理によって発生する発熱量などの制限などハードウェア構成上の制約となりうるものである。また要求仕様とは、プロセッシングエレメント間の距離制限やステップS1406で後述する設定変更数と距離の要素の優先度合の割合などハードウェア使用上で制限すべき項目である。ただし、本発明は上述の制約のみに限られるものではない。
【0059】
続いてステップS1403では対象となるデータフローの処理配置を行う。初期の処理の配置においては、ランダムに配置する、ないしはデータフローの深さ方向とプロセッシングエレメントアレイの入出力方向とを連動させて処理を配置させる方法があるが、これらの方法に限られるものではない。初期の配置でない場合は、シミュレーテッドアニーリングに基づき処理の配置を変更する。本実施形態では、処理配置である対象のデータフローBに関して初期処理配置、ないしは処理配置変更を行う。処理配置済みのデータフローAに関しては、制約に基づき処理配置の変更は行わない。
【0060】
ステップS1404では、処理配置結果がステップS1403で入力した要求仕様を満たしているか判断する。以下の式に示すように、制約を満たしていれば、ペナルティ変数p0を0とし、違反している場合はペナルティ変数p0をペナルティ値Cp0とする。
【0061】
【数1】

【0062】
ここで本実施形態では、違反があった場合に一律Cp0は定数値として扱っているが、違反項目に応じた変数値としてもよい。ステップS1405では、処理配置結果がステップS1302で入力したハードウェア制約条件を満たしているかを判断する。
【0063】
以下の式に示すように、制約を満たしていれば、ペナルティ変数p1を0とし、違反している場合はペナルティ変数p1をペナルティ値Cp1とする。
【0064】
【数2】
【0065】
ここで本実施形態では、違反があった場合に一律Cp1は定数値として扱っているが、違反項目に応じた変数値としてもよい。次にステップS1406では、対象となるデータフロー変更間における設定変更数と配置に基づく距離の算出を行い、評価値を計算する。まず設定変更数の算出について説明する。図13の例で説明するとの設定変更1339、1340、1341、1342の際に変更の必要がある設定数である。
【0066】
より具体的には、処理配置済みのデータフローi0における、設定値ui0,j,kと、処理配置対象のデータフローi1における、同じ位置に配置されたプロセッシングエレメントの同じ種類の設定値ui1,j,kの値が一致していなければα1を設定変更数に加える。上述の値が一致していれば何も加えない。
【0067】
ここで、プロセッシングエレメントrに配置されているデータフローi0のノードj0をj0rと表し、データフローi1のノードj1をj1rと表す。ここでrは前述したとおり、各プロセッシングエレメントを表すインデックスである。データフローが切り替わる際の同じ位置に配置されているノードの処理内容の変更に必要な設定変更数は以下の式で求めることができる。
【0068】
【数3】
【0069】
ここでα1は通常1であるが、プロセッシングエレメントのコンフィギュレーションメモリの構造に応じて、各設定が格納されているアドレス毎に重み付けを変更することも可能としている。またデータフロー毎に切り替え時間の優先度をつけるためにデータフロー毎に重みづけることも可能としている。図7で示した通り、一度のコンフィギュレーションコマンドで一つの設定値を変更することができることから、この数が少なくなれば、処理の切り替え時間を削減することが可能となる。
【0070】
続いて距離の算出について述べる。距離とは、配置対象であるデータフローBにおける距離1335、1336、1337、1338の合計量である。ステップS1403での配置とデータフローのデータ入出力関係に基づいて、以下の式で距離を表すことが可能である。
【0071】
【数4】
【0072】
ここでκ1l、λ1lはノード間の距離のx、y毎の重みであって、ノード間の距離などのアーキテクチャによって重みを一律ないしは別々に変更することも可能である。本ステップで評価値算出する際の式は上述の式より、以下と定義する。
【0073】
【数5】
【0074】
ここで、δはステップS1402で与えた設定変更数と距離のどちらを優先させるかの割合を表す指標である。つまり、要求仕様とハードウェア制約条件を満たしつつ、また距離が少なく、再構成に必要な設定変更数が少なくなるほど上記評価値は小さくなる。
【0075】
最後にステップS1407では、シミュレーテッドアニーリングに基づき目標達成したかを判断し、目標を達成した場合は終了する。目標未達の場合はステップS1403に戻り、ステップS1403〜S1407を繰り返し行う。ここで、目標値とは十分良い結果が得られるまで、もしくは予定された計算時間に達するまで繰り返す。
【0076】
以上の結果、回路構成情報106がHDD2504に生成されるので、後はインタフェース2509を介して、利用する外部メモリ101にそれを書き出し、実製品に搭載すれば良いことになる。
【0077】
なお、上記実施形態では、回路構成情報106を、外部装置(図17)にて作成する例を示した。これは以降に説明する全実施形態でも同じである。また、コンフィギュレーションコントローラ102が外部装置の代わりに、図13の処理を実行し、回路構成情報106を作成しても構わない。例えば、外部メモリ101に複数のデータフロー毎の設定(必要なプロセッサ数と各プロセッサの処理パラメータ)を保持させ、コンフィギュレーションコントローラ102が複数のデータフローの設定に基づいて回路構成106を作成すればよい。係る点も、以降に説明する全実施形態にも適用できることである。
【0078】
一般的な再構成デバイスにおけるデータフローのプロセッシングエレメントへの処理配置方法では設定変更数を意識しないため、データフローの処理変更間で全ての設定を変更する必要が生じる。
【0079】
本実施形態では、データフローの処理順に注目し、距離に加え設定変更の合計数が少なくすることで、設定変更数削減を効果的に行うことが可能となる。
【0080】
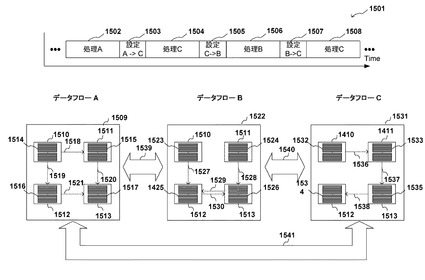
次に、本発明の第2の実施形態について説明する。第2の実施形態に係る処理のタイムチャートおよび、処理配置の概要を図15に示す。本実施形態では再構成デバイスの設定を変更において、各データフローの処理内容自体は決まっているが、その変更順序が不定で、状況や入力データなどに応じて変わる場合の処理配置に関する実施形態である。
【0081】
タイムチャート1501における期間1502ではデータフローAに関する処理が行われ、期間1504、1508ではデータフローCに関する処理が行われ、期間1506ではデータフローBに関する処理が行われる。期間1503ではデータフローAからデータフローCの設定変更が行われる。期間1505ではデータフローCからデータフローBの設定変更が行われる。期間1507ではデータフローBからデータフローCの設定変更が行われる。本実施形態では、データフローA、B、Cの処理変更の順序が一定でないため、それぞれのデータフロー間の全ての設定変更を考慮して処理の配置を行う必要がある。
【0082】
図中の1509、1522、1431はそれぞれデータフローA、B、Cにおけるプロセッシングエレメントの配置例を示しており、ここではこれら全てのデータフローの処理の配置を一度に一括して行う。なお配置例1509、1522、1531中のプロセッシングエレメント1510、1511、1512、1513はそれぞれ物理的に同じプロセッシングエレメントを指す。
【0083】
設定1514、1515、1516、1517は、それぞれデータフローAの配置におけるプロセッシングエレメント1510、1511、1512、1513への設定を表している。設定1523、1524、1525、1526は、それぞれデータフローBの配置におけるプロセッシングエレメント1510、1511、1512、1513への設定を表している。設定1532、1533、1534、1535は、それぞれデータフローCの配置におけるプロセッシングエレメント1510、1511、1512、1513への設定を表している。ここで上記の設定とは実施形態1と同様に、図6で説明した設定のことである。本実施形態では、データフローA、B間、B、C間、C、A間のプロセッシングエレメント1510、1511、1512、1513でデータフロー変更に必要な合計の設定変更数と各プロセッシングエレメント間接続の合計距離に注目する。
【0084】
上記合計数および距離数が図14で示したフローチャート1406で示す評価値に加える設定変更数を後述する評価値として算出することで、距離を考慮した、再構成デバイスの再構成時の設定変更数の削減を行う。
【0085】
なお、データフローA、B間でのプロセッシングエレメント1510、1511、1512、1513の設定変更は1539で表している。またデータフローB、C間でのプロセッシングエレメント1510、1511、1512、1513の設定変更は1540で表している。データフローC、A間でのプロセッシングエレメント1510、1511、1512、1513の設定変更は1541で表している。
【0086】
本実施形態と第1の実施形態との違いは、同時に複数のデータフローの処理配置を行う点にある。図14のステップS1401では、複数のデータフローを入力すると同時に、処理順序が任意であることを入力する。図14のステップS1404で行う処理配置では、処理配置対象であるデータフローA、B、C全てに対して処理配置を行う。図14のステップS1406で第1の実施形態に対して以下の違いがある。
【0087】
処理配置対象のデータフローi0における、設定値uio,j,kと、処理配置対象のデータフローi1における、同じ位置に配置されたプロセッシングエレメントの同じ種類の設定値ui1,j,kの値が一致していなければα2を設定変更数に加える。また、処理配置対象のデータフローi1における、設定値ui1,j,kと、処理配置対象のデータフローi2における、同じ位置に配置されたプロセッシングエレメントの同じ種類の設定値ui2,j,kの値が一致していなければβ2を設定変更数に加える。さらに、処理配置対象のデータフローi2における、設定値ui2,j,kと、処理配置対象のデータフローi0における、同じ位置に配置されたプロセッシングエレメントの同じ種類の設定値ui0,j,kの値が一致していなければγ2を設定変更数に加える。上述以外で、設定値が一致していれ場合は何も加えない。
【0088】
ここで、プロセッシングエレメントrに配置されているデータフローi0のノードj0をj0rと表し、データフローi1のノードj1をj1rと表し、データフローi2のノードj2をj2rと表す。ここでrは前述したとおり、各プロセッシングエレメントを表すインデックスである。
【0089】
データフローが切り替わる際に、同じ位置に配置されているノードの処理内容の変更に必要な設定変更数は以下の式で求めることができる。
【0090】
【数6】
【0091】
ここでα2、β2、γ2は通常それぞれ1であるが、プロセッシングエレメントのコンフィギュレーションメモリの構造に応じて、各設定が格納されているアドレス毎に重み付けを変更することも可能としている。またデータフロー毎に切り替え時間の優先度をつけるためにデータフロー毎に重みづけることも可能としている。
【0092】
また距離については以下の違いがある。図15で示した例では、距離は、距離1518、1519、1520、1521、1527、1528、1529、1530、1536、1537、1538の合計量として表される。図中のプロセッシングエレメントの配置は一例を示してだけであり、配置を変更することでこれらの距離合計量も変わる。配置後にその配置と、データフローのデータ入出力に基づいて以下の式で距離を表すことが可能である。
【0093】
【数7】
【0094】
ここでκ2i,l、λ2i,lは、データフロー毎のノード間の距離などのアーキテクチャによって重みを一律ないしは別々に変更することも可能である。本実施形態により、全てのデータフロー間を考慮することで、処理の実行順序が不定な場合でも、距離を考慮したうえで平均して設定変更数削減効果が得られる。
【0095】
次に、本発明の第3の実施形態について説明する。第3の実施形態に係る処理のタイムチャートおよび、処理配置の概要を図16に示す。本実施形態では既に複数のデータフローの処理順序およびそれぞれの処理配置も決まっている場合を想定している。上述の処理順序における任意のデータフローの処理間に、挿入前後の処理配置は変えずに、新たなデータフローに対応した処理を挿入するための処理配置に関する実施形態である。
【0096】
図16のタイムチャート1601は再構成デバイスで行う処理順序が既に決められ、その処理配置も決められているタイムチャートである。タイムチャート1601ではデータフローAの処理1603後、データフローAの設定からデータフローCの設定へ変更する期間1604を経てデータフローCの処理1605を行っている。このタイムチャート1601のデータフローAとデータフローC間に新たにデータフローBを挿入したタイムチャートがタイムチャート1602である。データフローAの処理1603の後にデータフローAの設定からデータフローBの設定へ変更する期間1606を経て新たに挿入したデータフローBの処理1607が行われる。その後データフローBの設定からデータフローCの設定へ変更する期間1608を経てデータフローBの処理1605が行われる。この際データフローAとCの処理配置は変更せずにデータフローBの処理配置を決定するため、挿入する前後の既に処理配置済みのデータフロー間の設定変更量を考慮する。
【0097】
図中の1609、1622、1631はそれぞれデータフローA、B、Cにおけるプロセッシングエレメントの配置例を示している。本実施形態ではデータフローAおよびCは処理配置済みであり、データフローBの処理配置を行う。なお配置例1609、1622、1631中のプロセッシングエレメント1610、1611、1612、1613はそれぞれ同じプロセッシングエレメントを指す。
【0098】
設定1614、1615、1616、1617は、それぞれデータフローAの配置におけるプロセッシングエレメント1610、1611、1612、1613への設定を表している。設定1623、1624、1625、1626は、それぞれデータフローBの配置におけるプロセッシングエレメント1610、1611、1612、1613への設定を表している。設定1632、1633、1634、1635は、それぞれデータフローCの配置におけるプロセッシングエレメント1610、1611、1612、1613への設定を表している。ここで上記の設定とは実施形態1と同様に、図6で説明した設定のことである。本実施形態では、データフローA、B間、B、C間、C、A間のプロセッシングエレメント1610、1611、1612、1613でデータフロー変更に必要な合計の設定変更数と各プロセッシングエレメント間接続の合計距離に注目する。
【0099】
なお、新たに挿入するデータフローBに伴う、データフローA、B間でのプロセッシングエレメント1610、1611、1612、1613の設定変更は1639で表している。またデータフローB、C間でのプロセッシングエレメント1610、1611、1612、1613の設定変更は1640で表している。
【0100】
本実施形態と第1の実施形態との違いは、複数の処理配置済みのデータフローを参照して、対象となるデータフローの処理配置を行う点である。
【0101】
図14のステップS1403で行う処理配置は、データフローBのみが対象である。データフローA、Cは処理配置済みであり、処理配置変更は行わない。図14のステップS1406では第一の実施形態に対して以下の違いがある。
【0102】
処理配置済みのデータフローi0における、設定値ui0,j,kと、処理配置対象のデータフローi1における、同じ位置に配置されたプロセッシングエレメントの設定値ui1,j,kの値が一致していなければα3を設定変更数に加える。また、処理配置対象のデータフローi1における、設定値ui1,j,kと、処理配置済みのデータフローi2における、同じ位置に配置されたプロセッシングエレメントの設定値ui2,j,kの値が一致していなければβ3を設定変更数に加える。上述の値が一致していなければ何も加えない。
【0103】
ここで、あるプロセッシングエレメントrに配置されているデータフローi0のノードj0をj0rと表し、データフローi1のノードj1をj1rと表し、データフローi2のノードj2をj2rと表す。ここでrは前述したとおり、各プロセッシングエレメントを表すインデックスである。
【0104】
データフローが切り替わる際の同じ位置に配置されているノードの処理内容の変更に必要な設定変更数は以下の式で求めることができる。
【0105】
【数8】
【0106】
またα3、β3は通常それぞれ1であるが、プロセッシングエレメントのコンフィギュレーションメモリの構造に応じて、各設定が格納されているアドレス毎に重み付けを変更することも可能としている。またデータフロー毎に切り替え時間の優先度をつけるためにデータフロー毎に重みづけることも可能としている。
【0107】
また距離については以下の違いがある。図16で示した例では、距離は、距離1618、1619、1620、1621、1627、1628、1629、1630、1636、1637、1638の合計量として表される。図中のプロセッシングエレメントの配置は一例を示してだけであり、配置を変更することでこれらの距離合計量も変わる。配置後にその配置と、データフローのデータ入出力に基づいて以下の式で距離を表すことが可能である。
【0108】
【数9】
【0109】
ここでκ3l、λ3lは、データフロー毎のノード間の距離などのアーキテクチャによって重みを一律ないしは別々に変更することも可能である。新たにデータフロー挿入する場合に、挿入前後のデータフローとの設定変更数の削減に関する効果が得られる。
【0110】
次に、本発明の第4の実施形態について説明する。第4の実施形態に係る処理のタイムチャートおよび、処理配置の概要を図17に示す。本実施形態では、ある基準となるデータフローの処理後、その結果に応じて次に行われるデータフローが異なる場合の処理配置に関する実施形態である。
【0111】
図17のタイムチャート1701は基準となるデータフローXの処理を期間1702で行った後、その結果に応じて、データフローXからデータフローAかBかCへの設定変更を期間1703で行う。設定完了後、データフローAかBかCの処理が期間1704で行われ、再度基準となるデータフローXの処理を行うため期間1705でデータフローAかBかCからデータフローXへと設定変更を行う。上記順序が繰り返されが、データフローAかBかCのどれが行われるかはデータフローXの結果に応じて変わる。
【0112】
図中の1706、1719、1728、1737はそれぞれデータフローX、A、B、Cにおける配置例を示している。本実施形態では、データフローX、A、B、Cの全てのデータフローの処理配置を行う。なお配置例1706、1719、1728、1737中のプロセッシングエレメント1707、1708、1709、1710はそれぞれ同じプロセッシングエレメントを指す。
【0113】
設定1711、1712、1713、1714は、それぞれデータフローXの配置におけるプロセッシングエレメント1707、1708、1709、1710への設定を表している。設定1720、1721、1722、1723は、それぞれデータフローAの配置におけるプロセッシングエレメント1707、1708、1709、1710への設定を表している。設定1729、1730、1731、1732は、それぞれデータフローBの配置におけるプロセッシングエレメント1707、1708、1709、1710への設定を表している。設定1738、1739、1740、1741は、それぞれデータフローCの配置におけるプロセッシングエレメント1707、1708、1709、1710への設定を表している。ここで上記の設定とは第1の実施形態と同様に、図6で説明した設定のことである。
【0114】
本実施形態では具体的には、データフローX、A、B、Cの処理配置を行う。処理配置に際して、データフローX、A間、X、B間、X、C間のプロセッシングエレメント1707、1708、1709、1710でデータフロー変更に必要な設定変更数の合計数と各プロセッシングエレメント間接続の合計距離に注目する。
【0115】
なお、データフローX、A間でのプロセッシングエレメント1707、1708、1709、1710の設定変更は1745で表している。データフローX、B間でのプロセッシングエレメント1707、1708、1709、1710の設定変更は1746で表している。
【0116】
データフローX、C間でのプロセッシングエレメント1707、1708、1709、1710の設定変更は1747で表している。
【0117】
本実施形態と第1の実施形態との違いは、処理順序に分岐があり、分岐先と分岐元間のデータフローに対して処理配置を行う点にある。
【0118】
図13のステップS1301では、複数のデータフローを入力すると同時に、部分的に任意の順序関係を含んだ処理順序を入力する。ここで部分的な任意とは本実施形態では実行順序に分岐があり、分岐元と分岐先の実行順序のみ任意であるということを指す。
【0119】
図14のステップS1403で行う処理配置は、処理配置対象であるデータフローX、A、B、Cの全てに対して処理配置を行う。本実施形態では全てのデータフローを処理配置対象として扱う例を示しているが、それに限ったものではない。本実施形態は処理順序に注目したものであり、少なくとも一つのデータフローが、既に処理配置済みの場合には、それ以外のデータフローの処理配置を行うこととなる。
【0120】
図14のステップS1406では第1の実施形態に対して以下の違いがある。処理配置対象のデータフローi0における、設定値ui0,j,kと、処理配置対象のデータフローi1における、同じ位置に配置されたプロセッシングエレメントの同じ種類の設定値ui1,j,kの値が一致していなければα4を設定変更数に加える。また、処理配置対象のデータフローi0における、設定値ui0,j,kと、処理配置対象のデータフローi2における、同じ位置に配置されたプロセッシングエレメントの同じ種類の設定値ui2,j,kの値が一致していなければβ4を設定変更数に加える。さらに、処理配置対象のデータフローi0における、設定値ui0,j,kと、処理配置対象のデータフローi3における、同じ位置に配置されたプロセッシングエレメントの同じ種類の設定値ui3,j,kの値が一致していなければγ4を設定変更数に加える。上述以外で、設定値が一致している場合は何も加えない。
【0121】
ここで、あるプロセッシングエレメントrに配置されているデータフローi0のノードj0をj0rと表し、データフローi1のノードj1をj1rと表し、データフローi2のノードj2をj2rと表し、データフローi3のノードj3をj3rと表す。ここでrは前述したとおり、各プロセッシングエレメントを表すインデックスである。
【0122】
データフローが切り替わる際の同じ位置に配置されているノードの処理内容の変更に必要な設定変更数は以下の式で求めることができる。
【0123】
【数10】
【0124】
ここでα4、β4、γ4は通常それぞれ1であるが、プロセッシングエレメントのコンフィギュレーションメモリの構造に応じて、各設定が格納されているアドレス毎に重み付けを変更することも可能としている。またデータフロー毎に切り替え時間の優先度をつけるためにデータフロー毎に重みづけることも可能としている。
【0125】
また距離については以下の違いがある。図17で示した例では、距離は、距離1715、1716、1717、1718、1724、1725、1726、1727、1733、1734、1735、1736、1742、1743、1744の合計量として表される。図中のプロセッシングエレメントの配置は一例を示してだけであり、配置を変更することでこれらの距離合計量も変わる。配置後にその配置と、データフローのデータ入出力に基づいて以下の式で距離を表すことが可能である。
【0126】
【数11】
【0127】
ここで、κ4i,l、λ4i,lは、データフロー毎のノード間の距離などのアーキテクチャによって重みを一律ないしは別々に変更することも可能である。本実施形態により、複数のデータフローを順々に行う上で、その実行順序に分岐がある場合でも、分岐元となるデータフローと分岐先となる複数の他のデータフローを考慮することで、設定変更数削減効果が得られる。
【0128】
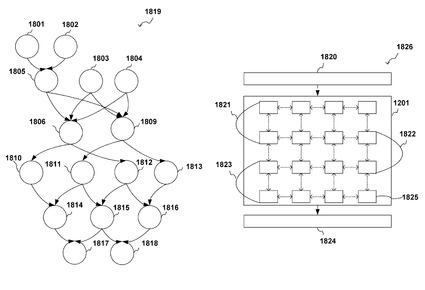
次に、本発明の第5の実施形態について説明する。第5の実施形態に係るデータフローと処理配置制限方法に関する概要を図18に示す。処理配置問題は一般的に難しく解算出のための時間が大きくかかる場合が多い。本発明のように複数のデータフローを同時に配置させる場合はさらに問題が大きくなる。そのため本実施形態では処理の配置可能範囲を制限することで効果的に解算出時間を短縮する。
【0129】
データフロー1819は複数の処理に対応するノード1801〜1818で構成されている。また1826はプロセッシングエレメントアレイに対する入力装置を1820、出力装置を1821とし、それらの間にプロセッシングエレメントアレイがある構成となっている。
【0130】
本実施形態では、これらをデータフロー1819の処理を配置モデル1201に配置させる際、データフローの深さ方向とプロセッシングエレメントアレイへの入出力の位置を対応させることで解空間を効率的に狭める。具体的にはノード1801から1804は1821で示した範囲のみ配置可能と設定する。また1805から1810は1822で示した範囲のみ配置可能と設定する。また1811から1814は1822で示した範囲のみ配置可能と設定する。また1815から1818は1823で示した範囲のみ配置可能と設定する。
【0131】
これらの制限は図14のステップS1402で入力することを想定している。本実施形態では配置可能範囲はデータフローの深さとプロセッシングエレメントアレイの入出力の方向に対応付けさせたが、それに限るものではない。
【0132】
上述した実施形態では、ユースケース別に各々の処理配置方法について述べたが、本発明はこれらの方法の組み合わせでも良い。また、再構成デバイスの構成要素としてプロセッシングエレメントを説明したが、これに限るものではなく、LUTや、それとの組み合わせでも良い。また、設定は、実施形態で示した設定に限るものではなく、LUTベースの再構成デバイスで使用される設定でも良い。また、実施形態では入力するデータフロー全てに対して処理配置対象としたが、データフローの処理配置対象範囲を指定することで、データフローの一部のみに対して処理配置を行っても良い。また、実施形態ではプロセッシングエレメント数はデータフロー間で同じとしているが、処理を配置するプロセッシングエレメント数が異なっても良い。また、実施形態で示した、距離合計値が少なくなるように記載しているが、各距離の最大値が小さくなるように配置を決定しても良い。また、各距離の平均値が少なくなるように配置を決定しても良い。
【0133】
上述した実施形態ではプロセッシングエレメントは格子状に均一に配置され、それぞれのプロセッシングエレメント間の接続距離は一定を前提に記載したが、これに限るものではない。プロセッシングエレメントの接続形態が例えば木構造のように接続されている場合はそれぞれの距離は、木構造に応じて重みづけても良い。つまり、プロセッシングエレメントの接続形態に応じてそれぞれの距離を重みづけても良い。
【0134】
また、本発明は、以下の処理を実行することによっても実現される。即ち、上述した実施形態の機能を実現するソフトウェア(プログラム)を、ネットワーク又は各種記憶媒体を介してシステム或いは装置に供給し、そのシステム或いは装置のコンピュータ(またはCPUやMPU等)がプログラムを読み出して実行する処理である。
【技術分野】
【0001】
本発明は、回路構成を変更することができる再構成デバイス、その処理配置方法等に関する。
【背景技術】
【0002】
従来から製造後のLSI回路装置であっても内部の回路構成を変更することで、上記回路が行う処理内容を変更することが可能な再構成デバイスが提案されている。製造後のLSI回路装置でも処理を変更することが可能であるため、仕様変更などに伴うLSIの作り直しを行わなくて済む。製造コストを抑えることが可能な点や開発期間が短縮可能な点で、現在様々な分野において再構成デバイスが使用されている。
【0003】
再構成デバイスの構成として、多数のLUT(Look−Up−Table)を搭載したタイプや多数のプロセッシングエレメントを搭載したタイプが代表的である。また各々のエレメントにはマルチプレクサなどのスイッチングエレメントが接続されている。ここではLUTやプロセッシングエレメント、スイッチングエレメントなどの各構成要素を動作させるための設定を総称し回路構成情報と呼んでいる。回路構成情報の生成方法としては様々あるが、一般に(1)テクノロジーマッピングと呼ばれる論理的な処理の割り当て、(2)各構成要素への物理的な配置、(3)各構成要素の経路決定、の工程に分けられ、順番に行われことが多い。上記三つの工程を経て最終的に回路構成情報が生成される。
【0004】
(1)論理的な処理の割り当て工程では、処理を構成要素に割り当てることを行う。具体的には、各処理を物理的な構成要素を特定せずに論理的な構成要素に割り当てる。順序変更の指標としては、回路面積、動作速度、消費電力の観点が一般的である。(2)配置工程では、再構成デバイス内のどの構成要素でどの処理を行うかの物理的な割り当てを決定する。データの入出力関係にある処理が配置されているプロセッシングエレメント間の距離によって、データ通信に係るスイッチングエレメント数が異なるため、遅延時間(最大動作周波数)が大きく変化する。そのため、通常は入出力関係のある処理はできる限り近い距離のプロセッシングエレメントに配置させることが遅延時間を短縮する上で重要となる。(3)経路決定の工程では、データ通信の入出力関係にあるプロセッシングエレメント間のデータ通信のため、スイッチングエレメントによる経路を決定する。配置工程と比べ具体的な経路を決定するため、プロセッシングエレメント間の遅延時間を短縮した経路を決定することが重要となってくる。
【0005】
近年、集積度の向上に伴い、再構成デバイスにおいて実行可能な処理の規模は増えている。しかし、最近ではそれにも増して、処理自体への要求が複雑化・高度化しており、一つの再構成デバイスで全ての処理を一度に行うことは難しい場合がある。これに対して、一つの再構成デバイスにおいて時分割で処理を順々に行う方法がある。より具体的にはまず所望の処理を分割し、分割した処理に対応した回路構成情報を生成する。その後、回路構成情報に基づいた再構成デバイスの回路構成の変更、処理を順々に行っていく。これにより、再構成デバイスで大きな規模の処理を行うことが可能となる。しかしながら、毎回全ての回路構成を変更させていては全体の処理時間が長くなってしまい、速度性能が劣化してしまう。また上記の処理分割数が多い場合も同様に、処理速度の劣化を生じさせてしまう。
【0006】
この問題を解決するための方法として、マルチコンテキスト型の再構成デバイスがある。コンテキストとは、回路構成情報のことで、マルチコンテキスト型の再構成デバイスとは、複数の回路構成情報を格納するメモリを再構成デバイス内に搭載したものである。回路構成を変更する場合には、上記メモリを切り替えてデバイスを再構成することが可能であり、高速に切り換え可能なことで回路の再構成時間を大幅に短縮することが可能である。しかし、追加で回路構成情報用のメモリを搭載する必要があるため、回路規模が増大する問題がある。
【0007】
これに対し、特許文献1では、再構成時間を短縮する方法としてスケルトン回路技術に基づいた手法が提案されている。この手法では、先行ベース回路と呼ばれる回路構成情報を、予め再構成デバイスに構成しておく。ここで先行ベース回路とは複数の回路構成情報において全てに共通する共通回路部分と、複数個の回路で互いに共通せず、かつ、再構成デバイス上で回路構成情報を共有しない非排他的独立回路部分からなる回路構成情報のことである。再構成デバイス上において回路の差分のみを部分的に再構成することにより、処理に必要な回路を構成するようにする。この方法は、マルチコンテキスト型に比べ、追加で構成用のメモリを必要としないため回路規模が増大はしない。
【先行技術文献】
【特許文献】
【0008】
【特許文献1】特許第3558119号公報
【発明の概要】
【発明が解決しようとする課題】
【0009】
しかしながら、一般に再構成デバイスでは様々なアプリケーションを実行する可能性があり、アプリケーションによっては共通部分が少なくなる。また、再構成すべき回路構成情報の数もアプリケーションによって異なる。特許文献1で述べられている先行ベース回路部生成において、共通部分が少ないもしくは、回路構成情報の数が多く再構成デバイスの回路規模を大幅に超えてしまう場合には回路構成を変更するための期間を効率的に削減することが難しい。また、上述した処理配置工程においては、回路構成の変更期間を削減することに加え、データ入出力関係にあるプロセッシングエレメント間の距離が近い必要がある。入出力に係るプロセッシングエレメント間の通信距離が遠い場合、データ通信の遅延時間を増やし、結果として処理全体の期間を増大させてしまう。
【0010】
本発明は上述した問題点に鑑みてなされたものであり、回路構成変更の順序を考慮することで、プロセッシングエレメント間のデータ通信遅延を抑えつつ回路規模を増やすことなく回路変更期間を効率的に削減することを目的とする。
【課題を解決するための手段】
【0011】
本発明の処理葉位置方法は、複数の構成要素で構成される再構成デバイスに対し、データフローの各処理を行う構成要素を決定するための処理配置方法であって、少なくとも二つの異なるデータフローと前記データフローの処理順序を入力する入力ステップと、再構成デバイスの構成要素の制約を入力する制約ステップと、前記データフローに応じた、前記再構成に必要な設定変更数と前記データフローのデータ入出力の依存関係に基づく構成要素間の距離とを用い、構成要素の配置を決めることで、要求される処理をどの構成要素で実行させるかを決定する決定ステップとを有することを特徴とする。
【発明の効果】
【0012】
本発明によれば、データ通信の遅延時間を抑えつつ再構成に必要な設定数を減らすように回路構成情報を作成することで、回路規模を増やすことなく再構成デバイスの再構成期間を短縮することが可能である。
【図面の簡単な説明】
【0013】
【図1】再構成デバイスを含む処理装置の構成例を示す図である。
【図2】再構成デバイスの構成例を示す図である。
【図3】再構成デバイスのエレメント間のデータ通信の手順例を示す図である。
【図4】プロセッシングエレメントの構成例を示す図である。
【図5】コンフィギュレーションコマンドのフォーマット例を示す図である。
【図6】プロセッシングエレメントのコンフィギュレーションメモリに格納される設定の概要例を示す図である。
【図7】設定を読み書きする手順を示すフローチャートである。
【図8】スイッチングエレメントの構成例を示す図である。
【図9】スイッチングエレメントのコンフィギュレーションメモリに格納される設定の概要例を示す図である。
【図10】データフローにおける処理のプロセッシングエレメントへの配置例を示す図である。
【図11】複数のデータフローを順次処理するタイムチャートである。
【図12】処理配置に向けたプロセッシングエレメントアレイのモデル例を示す図である。
【図13】第1の実施形態における複数のデータフローの処理配置を行うための概要例を示す図である。
【図14】第1の実施形態における処理配置を行うためのフローチャートである。
【図15】第2の実施形態におけるデータフローの処理配置を行うための概要例を示す図である。
【図16】第3の実施形態におけるデータフローの処理配置を行うための概要例を示す図である。
【図17】第4の実施形態におけるデータフローの処理配置を行うための概要例を示す図である。
【図18】第5の実施形態におけるデータフローの処理配置範囲限定を行うための概要例を示す図である。
【図19】回路構成情報を作成する装置の構成の一例を示すブロック図である。
【発明を実施するための形態】
【0014】
以下、本発明を適用した好適な実施形態を、添付図面を参照しながら詳細に説明する。
【0015】
先ず、本発明の第1の実施形態について説明する。第1の実施形態に係る再構成デバイスを有するシステムの全体構成の例を図1に示す。外部メモリ101は、内部に回路構成情報106を保持している。回路構成情報106は再構成デバイス105を構成する要素を動作させる設定群である。コンフィギュレーションコントローラ102は上記メモリ101から結線104を通じ回路構成情報106を取得する。取得した回路構成情報106は結線103を通じて再構成デバイス105へ送られる。ここで再構成デバイス105の例としてプロセッシングエレメントアレイとしている。また以下では、具体的にプロセッシングエレメントアレイ内の説明をするが、本発明は下記の各プロセッシングエレメントの構成や経路構成に限定されるものではない。
【0016】
図2に、本実施形態における再構成デバイスであるプロセッシングエレメントアレイの概要図を示す。再構成デバイスには、8入力8出力の入出力処理手段であるスイッチングエレメント201が二次元格子状に配置されている。演算処理手段である4入力4出力のプロセッシングエレメント202が、スイッチングエレメント201の格子内に配置されている。スイッチングエレメント201a〜iの8入力8出力は1入力1出力を一組としてそれぞれ東西南北(右左下上)方向の、他の4つのスイッチングエレメント201と結線203aおよび203bを介して夫々接続されている。
【0017】
さらに、北東、南東、南西、北西方向の、それぞれ別の4つのプロセッシングエレメント202と結線204aおよび204bを介して双方向に接続された構成を持つ。またスイッチングエレメント201a〜201iおよびプロセッシングエレメント202a〜202dは結線205で一方向に数珠繋ぎに接続されている。
【0018】
結線203a、203bおよび結線204a、204bはスイッチングエレメント201やプロセッシングエレメント202の間で処理対象データを通信するために接続された結線である。結線205は、スイッチングエレメント201やプロセッシングエレメント202に設定を供給するための結線である。
【0019】
上述の設定によって、スイッチングエレメント201においては処理対象データの入出力先が決定され、プロセッシングエレメント202においては処理対象データの入出力先や処理内容が決定される。なお、図2の各結線203a、203b、204a、204b、205の矢印の方向はデータの方向を示している。またスイッチングエレメント201a〜201iはそれぞれ同じ構成を有し、プロセッシングエレメント202a〜202dはそれぞれ同じ構成を有する。
【0020】
ここで、各結線203a、203b、204a、204b、205の通信プロトコルの一例として、Valid信号とReady信号による2線ハンドシェークを図3に示す。図3では送信側であるモジュールA301と受信側であるモジュールB302間はデータ信号線303、Valid信号線304およびReady信号線305が接続されている。Valid信号はValid信号線304を通じ送信側が受信側に対し送信可能状態を示す信号である。Ready信号はReady信号線305を通じ受信側が送信側に対しデータ受信可能状態を示す信号である。本プロトコルではモジュールA301からのValid信号線304とモジュールB302のReady信号線305とが両方有効となるクロック立ち上がりのタイミングでデータ信号線303のデータがモジュールA301からモジュールB302へと送信される。図3の波形中では306aのタイミングでデータAが、306bのタイミングでデータBが、306cのタイミングでデータC、306dのタイミングでデータDがモジュールA301からモジュールB302へと転送されている。
【0021】
プロセッシングエレメント202の構成を図4に示す。プロセッシングエレメント202は、コンフィギュレーションユニット401、インプットユニット402、コンピュテーショナルユニット403、アウトプットユニット404、テンポラリーバッファ405で構成されている。前記コンフィギュレーションユニット401はプロセッシングエレメント202の動作内容を決定するための設定の管理を行う。前記インプットユニット402はコンフィギュレーションユニット401の設定に基づき、入力処理を行う。コンピュテーショナルユニット403はコンフィギュレーションユニット401の設定に基づき、演算処理を行う。また、コンピュテーショナルユニット403は、再度コンピュテーショナルユニット403に入力するためテンポラリーバッファ405に処理された結果を保持することが可能である。アウトプットユニット404はコンフィギュレーションユニット401の設定に基づき、出力処理を行う。
【0022】
上記プロセッシングエレメント202の動作をより具体的に説明する。インプットユニット402はコンフィギュレーションユニット401から入力先を決定するための設定情報を、結線406を通じて取得する。取得した設定情報はどの入力ポートを介して外部接続されているモジュールと通信を行うかが指定されている。その情報を元に、結線204a−ne、204a−se、204a−sw、204a−nw、を通じて処理対象であるデータを取得する。ここで参照符号のne,se、sw,nwはそれぞれ方向を示しており、結線204a−neは北東に配置されたスイッチングエレメントと接続されている。また、204a−seは南東に配置されたスイッチングエレメントと接続されている。204a−swは南西に配置されたスイッチングエレメントと接続されている。204a−nwは北西に配置されたスイッチングエレメントと接続されている。取得したデータは、結線409を通してコンピュテーショナルユニット403に送られる。
【0023】
コンピュテーショナルユニット403は、コンフィギュレーションユニット401から処理内容を決定するための設定情報を、結線407を通じて取得する。取得した設定情報に基づいてインプットユニット402から送られてくるデータを取得し、処理を行う。処理したデータは結線410を通じてアウトプットユニット404に送られる。
【0024】
コンピュテーショナルユニット403は、少なくとも一つの演算器を保持している。上記演算器は、例えば、加減算器、比較器、乗算器、除算器、論理演算器等の演算器、または、これらの組合せからなる演算器、さらにはこれらと他の演算器の組合せからなる演算器などである。以下では具体的な例として、上記コンピュテーショナルユニット403では、積和演算と比較演算処理が行え、一度の演算でどちらかを一方を選択的に行うことができるものとし説明する。積和演算では、a・b+c・dの処理を行い、比較演算では、もしa>bならばcを出力、そうでなければdを出力するといった処理を行う。また、コンピュテーショナルユニット403は一度の入力に対して、上記演算器を繰り返し使用することが可能な構成となっている。繰り返しで使用する場合は一旦上記演算器で使用された処理結果を、結線412を通して、テンポラリーバッファに保存し、その後、結線411を通して、再度コンピュテーショナルユニット403に入力する。再度入力されたデータに対して、新たに上記演算器にて処理を行う。後で詳細を述べるが、上記設定とは上記演算の種類や繰り返し処理、またそれぞれの処理で必要な変数a、b、c、dはどの値を参照するか、また固定値ならばその値を指定することを意味する。
【0025】
アウトプットユニット404は、処理したデータの出力先を示す設定情報を結線408を通じて取得する。取得した設定情報は、どの出力ポートを介してスイッチングエレメントと通信を行うかが指定されている。その情報を元に、結線204b−ne、204b−se、204b−sw、204b−nw、を通じてスイッチングエレメントへ出力する。ここで結線204b−neは北東に配置されたスイッチングエレメントと接続されている。また、204b−seは南東に配置されたスイッチングエレメントと接続されている。204b−swは南西に配置されたスイッチングエレメントと接続されている。204b−nwは北西に配置されたスイッチングエレメントと接続されている。
【0026】
次にコンフィギュレーションユニット401の動作について説明する。コンフィギュレーションユニット401はプロセッシングエレメント202毎にユニークなIDを保持している。コンフィギュレーションユニットは入力側の結線205より送られてくる設定情報を取得し、コンフィギュレーションユニット内で処理し、出力側の結線205を通して設定を出力する。コンフィギュレーションユニット401は自らのIDに対応する設定を格納するためコンフィギュレーションメモリ413を有している。
【0027】
図5にコンフィギュレーションユニットに送受信される、設定のためのコンフィギュレーションコマンド501を示す。コンフィギュレーションコマンド501はリード/ライトモード502、ID503、コンフィギュレーションアドレス504、設定値505で構成されている。リード/ライトモード502はコンフィギュレーションコマンドの読み書きの処理を決定する信号である。ID503は処理対象のプロセッシングエレメント202を決める信号である。コンフィギュレーションアドレス504はコンフィギュレーションユニット401中の設定が保持されているメモリ内の番地を指定する信号である。設定値505は実際の設定値を表す信号である。図5中のビット幅を示すM、N、O、Pは実際に構成するアーキテクチャによって決められる値である。以下では上述した構成に基づく設定に関してより具体的に説明する。
【0028】
図6中の601はコンフィギュレーションメモリ413のアドレスを示しており、図5のコンフィギュレーションアドレス504で指定されるアドレスに相当する。602は実際の設定値を示しており、図5の設定値505に相当する。本実施形態はこれら一つ一つを設定と読んでいるが、本発明は上述の単位に限るものではない。図ではインプットユニット402、コンピュテーショナルユニット403、アウトプットユニット404に関する設定がコンフィギュレーションメモリ413に保持されている例を示している。
【0029】
アドレス0x0000_0000(“0x”は16進数を示している)で示した設定値は、インプットユニット402における入力先を決定するための設定情報で、この値に応じて所定の入力先が決まる。アドレス0x0000_0004で示したイタレーションナンバーは、コンピュテーショナルユニット403における、演算の繰り返し回数を決定するための設定情報で、値に応じて演算の繰り返し回数が決まる。本実施形態では4回までの演算を想定している。
【0030】
アドレス0x0000_0008で示したオペレーションセッティングは1度目の演算で行う、演算の種類を決定するための設定で、値に応じて積和演算か比較演算かが決まる。アドレス0x0000_000cで示したバリアブルセッティングは1度目の演算で、変数aの値の参照先を決めるための設定である。参照先としては、入力ポートからの入力値、コンフィギュレーションメモリ413に保持されている固定値、以前の計算結果が保持されているテンポラリーバッファの値がある。この値に応じて、上記いずれかの値がこの変数aに入力される。また0x0000_000cと同様に、0x0000_0010、0x0000_0014、0x0000_0018で示したバリアブルセッティングはそれぞれ、1度目の演算における変数b、c、dの値の参照先を決めるための設定である。
【0031】
次に0x0000_001cで示したパラメータは、1度目の演算において0x0000_000cで指定された参照先が固定値の場合の、変数aのための固定値である。0x0000_001cと同様に0x0000_0020、0x0000_0024、0x0000_0028で示した固定値は、それぞれ1度目の演算で変数b、c、d、で使用される場合の値である。
【0032】
続く0x0000_002c〜から0x0000_0094は、上記0x0000_0008〜0x0000_0028で示した1度目の演算に係る設定と同様にそれぞれ、2度目、3度目、4度目の設定値を示している。最後に0x0000_0098で示したアウトプットセレクトバリューは、アウトプットユニット404における出力先を決定するための設定値で、値に応じて所定の出力先が決まる。
【0033】
次にコンフィギュレーションユニットで行われる処理フローを図7に示す。ステップS701では、コンフィギュレーションコマンド501を入力する。ステップS702では、入力されたコンフィギュレーションコマンド501で指定されたID503が、コンフィギュレーションユニット401の持つ自身のIDと一致するかどうかを判断する。もし、ステップS702で自身のIDと違うと判断された場合はステップS711、712で、入力されたコンフィギュレーションコマンド501に対して、何も処理せずにそのまま出力する。もし、自身のIDと一致する場合は、次にステップS703でリード/ライトモード502の値がリードモードかどうかを判断する。リードモードでなければステップS707でライトモードかどうかを判断する。いずれのモードでもない場合はステップS711、712で何も処理せずにそのまま出力する。もし、リードモードと判断された場合は、ステップS704において、コンフィギュレーションメモリ413からコンフィギュレーションアドレス504で指定されたデータを読み出す。その後、ステップS705にて、入力されたコンフィギュレーションコマンド501の設定値505に読み出したデータを書き込み、ステップS706でそのコンフィギュレーションコマンド501を出力する。ライトモードと判断された場合は、ステップS708にて入力されたコンフィギュレーションコマンド501の設定値505をコンフィギュレーションアドレス504で指定されたコンフィギュレーションメモリ413に書き込む。次にステップS709では、入力されたコンフィギュレーションコマンド501の値を変更せず、ステップS710にて、そのまま出力する。一度のコンフィギュレーションコマンドで一つの設定値505を変更することが可能であり、順次コンフィギュレーションコマンドを送信し、必要な設定値を全て変更することで所望の処理を実現する。つまり、この設定数が処理内容の切り替え時間を決めていることとなる。
【0034】
スイッチングエレメント201の構成を図8に示す。スイッチングエレメント201は、コンフィギュレーションユニット801と、クロスバースイッチ802で構成される。コンフィギュレーションユニット801はデータを転送する接続先を決定するための設定値の管理をする。クロスバースイッチ802はコンフィギュレーションユニット801の設定に基づき一対一に入出力を接続する。プロセッシングエレメント202のコンフィギュレーションユニット401と同様、コンフィギュレーションユニット801はスイッチングエレメント201毎にユニークなIDを保持している。コンフィギュレーションユニットは入力側の結線205より送られてくる設定情報を取得し、コンフィギュレーションユニット内で処理を行い、出力側の結線205を通して設定値を出力する。コンフィギュレーションユニットは上記取得した設定をコンフィギュレーションメモリ804に保持している。コンフィギュレーションユニットのコンフィギュレーションコマンドとその処理フローは、図5に示したフォーマット、および図7に示した処理フローと同様である。クロスバースイッチ802はコンフィギュレーションユニット801からデータの入出力先を決定する設定情報を、結線803を通じて取得する。スイッチングエレメント201は取得した設定値に基づき結線203a−w、−s、203b−e、−n、結線204b−ne、−se、−sw、−nwを通じてデータを取得する。取得したデータは、接続されている結線203a−e、−n、203b−w、−s、結線204a−ne、−se、−sw、−nwを通じて渡す。
【0035】
ここで結線203a−w、−sはそれぞれ西、南に配置されたスイッチングエレメントと接続されていることを意味する。203b−e、−nはそれぞれ東、北に配置されたスイッチングエレメントと接続されていることを意味している。
【0036】
結線203a−e、−nはそれぞれ東、北に配置されたスイッチングエレメントと接続されていることを意味する。203b−w、−sはそれぞれ西、南に配置されたスイッチングエレメントと接続されていることを意味している。
【0037】
結線204a−ne、−se、−sw、−nwはそれぞれ北東、南東、南西、北西に配置されたスイッチングエレメントと接続されていることを意味している。結線204b−ne、−se、−sw、−nwはそれぞれ北東、南東、南西、北西に配置されたスイッチングエレメントと接続されていることを意味している。
【0038】
図9にコンフィギュレーションメモリ804に保持されている、スイッチングエレメント201におけるクロスバースイッチ802の入出力の接続に関する設定例を示す。901はメモリのアドレスを示しており、図5のコンフィギュレーションアドレス504で指定されるアドレスに相当する。902は設定値を示しており、図5の設定値505を示している。アドレス0x0000_0000で示したコネクション設定は結線203a−wからの入力を203a−e、n、203b−w、−s、204a−ne、−se、−sw、−nwのいずれに出力するかを決定するための設定値である。続く、0x0000_0004は結線203a−sからの入力を0x0000_0000と同様どの結線に出力するかを決定する設定値である。0x0000_0008は結線203b−eからの入力を0x0000_0000と同様どの結線に出力するかを決定する設定値である。0x0000_000cは結線203b−nからの入力を0x0000_0000と同様どの結線に出力するかを決定する設定値である。0x0000_0010は結線204b−neからの入力を0x0000_0000と同様どの結線に出力するかを決定する設定値である。0x0000_0014は結線204b−seからの入力を0x0000_0000と同様どの結線に出力するかを決定する設定値である。0x0000_0018は結線204b−swからの入力を0x0000_0000と同様どの結線に出力するかを決定する設定値である。0x0000_001cは結線204b−nwからの入力を0x0000_0000と同様どの結線に出力するかを決定する設定値である。
【0039】
次にデータフローの構成要素への配置の概要について図10を用いて説明する。ここで、配置とはデータフローの処理を、所定の配置で規定されるプロセッシングエレメントで実行させるかを決定することを意味している。図10ではデータフロー1001のノード1002、1003、1004、1005はそれぞれ一つのプロセッシングエレメントで行われる処理である。これらノード1002、1003、1004、1005に対応する処理を、再構成デバイス105のプロセッシングエレメント202−1、−2、−3、−4へ配置する例を示している。設定1006、1007、1008、1009はそれぞれ1002、1003、1004、1005の処理内容に対応したアドレス601、設定値602で構成されている。なお、各ノードで行う処理内容の割り当ては済んでおり、設定1006、1007、1008、1009は予め決められているものとしている。配置を決定することで、各設定の書き込み先であるプロセッシングエレメントに対応したID503を決定することが可能となる。
【0040】
上述した再構成デバイスの構成を複数種類変更して所望の処理を実現するためのタイムチャート例を図11に示す。図11では同一の再構成デバイスで複数の異なるデータフローA〜Zを順に実行しているタイムチャートを示している。本実施形態で扱うデータフローとは、再構成デバイスのプロセッシングエレメントに配置可能な単位で構成されたデータフローのことである。各データフローを処理するための設定は予め生成しておく。再構成デバイスに対して予め生成された設定に基づき再構成デバイスを再構成し、その構成のもとで処理をするという一連の処理が、所定の順序で順々に行われる。
【0041】
以下ではデータフローAを配置済みとし、データフローBを配置対象として説明する。具体的には、配置済みのデータフローAを実行するための設定値を参照し、データフローBの処理配置を決定する。データフローAの処理配置を参照しデータフローBの処理配置を決定した後、次はデータフローBを配置済みとし、データフローCを配置対象とする。具体的にはデータフローBの処理配置を決定した時と同様に、処理配置済みのデータフローBを実行するための設定値を参照し、データフローCの処理配置を決定する。上記の手順を順々に繰り返すことでAからZまでのデータフローの配置を行うことが可能となる。
【0042】
一般に、配置問題は配置のみを決定するだけでも解空間が広い。そのため、詳細配線決定を同時に行うと、良い解を算出できないだけでなく、解自体を算出できない可能性が出てくる。そのため本配置方法では詳細な配線情報は決定せず、図12に示す配置モデルに基づく概略の距離を用いて配置を決定する。本実施形態では配置モデルとしてプロセッシングエレメントアレイをプロセッシングエレメントの位置に基づいたマンハッタンモデルを用いている。プロセッシングエレメント間のマンハッタン距離を指標として解を算出する。ただし、本発明は、概略の距離としてはマンハッタン距離に限定されるものではない。指標として、詳細配線を同時に行うことも可能である。また、本実施形態では配置モデルとしてマンハッタンモデルに基づく配置モデルを用いたが、それに限るものではない。アーキテクチャに依存したモデルやユークリッド空間に基づいたモデルでも良い。
【0043】
図12に示すように、スイッチングエレメント201とプロセッシングエレメント202で構成される再構成デバイス105に対し、配置モデル1201を定義する。配置モデル1201はプロセッシングエレメント202のみで構成しており、指標となる距離としては、横方向のプロセッシングエレメント間の距離1202と縦方向の距離1203で表す。本実施形態では縦横の距離は等しいものとしているが、異なっても良い。また本発明で扱う距離とは、物理的な長さであっても良いし、各エレメント間の通信に要する時間の長さであっても良く、これらに限るものではない。
【0044】
次に、図12の配置モデルを用いて、図11のタイムチャートで示した処理の切り替わりに注目した処理のプロセッシングエレメントへの配置方法について述べる。
【0045】
図13では本実施形態における配置の概要を示している。データフローAはノード1301、1302、1303、1304として表される処理で構成されており、設定1305、1306、1307、1308はそれぞれのノードで行う処理の設定である。またフロー1309はノード1301と1302間のデータ入出力関係を表している。フロー1310はノード1301と1303間のデータ入出力関係を表している。フロー1311はノード1302と1304間のデータ入出力関係を表している。フロー1312はノード1303と1304間のデータ入出力関係を表している。
【0046】
データフローBはノード1313、1314、1315、1316として表される処理で構成されており、設定1317、1318、1319、1320はそれぞれのノードで行う処理の設定である。またフロー1321はノード1313と1315間のデータ入出力関係を表している。フロー1322はノード1314と1315間のデータ入出力関係を表している。フロー1323はノード1315と1316間のデータ入出力関係を表している。
【0047】
ここではプロセッシングエレメントアレイの配置モデル1201内の領域1324に上述のデータフローA、Bの処理を配置させることを想定している。本実施形態ではプロセッシングエレメントアレイ内の一部への配置について述べるが、それに限られるものではなく、複数の部分や全体への配置でも良い。1325は上記の領域1324のデータフローA向けの処理配置例を表している。1326は上記の領域1326のデータフローB向けの処理配置例を表している。各々の処理配置1325、1326内のプロセッシングエレメント1327、1328、1329、1330はそれぞれ物理的に同じプロセッシングエレメントを表している。処理配置1325では、データフローAにおいてはノード1301の処理をプロセッシングエレメント1327に配置させている。ノード1302の処理をプロセッシングエレメント1329に配置させている。ノード1303の処理をプロセッシングエレメント1328に配置させている。ノード1304の処理をプロセッシングエレメント1330に配置させている。またプロセッシングエレメント間のデータ通信の距離を、フロー1309は距離1331、フロー1310は距離1332、フロー1311は距離1333、フロー1312は距離1334として表している。
【0048】
続いてデータフローBに関しては、ノード1313の処理をプロセッシングエレメント1327に配置させている。ノード1314の処理をプロセッシングエレメント1328に配置させている。ノード1315の処理をプロセッシングエレメント1329に配置させている。ノード1316の処理をプロセッシングエレメント1330に配置させている。またプロセッシングエレメント間のデータ通信の距離を、フロー1321は距離1335、フロー1322は距離1336および1337、フロー1323は距離1338として表している。
【0049】
データフローAからデータフローBに処理が切り替わる際に、プロセッシングエレメント1327においては、設定変更1339で示すように設定1305から設定1317へと設定が変更される。プロセッシングエレメント1328においては、設定変更1341で示すように設定1307から設定1318へと設定が変更される。プロセッシングエレメント1329においては、設定変更1339で示すように設定1306から設定1319へと設定が変更される。プロセッシングエレメント1330においては、設定変更1339で示すように設定1308から設定1320へと設定が変更される。
【0050】
本実施形態では、配置を行う上で、処理が切り替わる際の設定変更数とデータフローの依存関係に基づく構成要素間の距離の二つの要素に注目する。
【0051】
本実施形態で用いる図13の例ではデータフローAは既に処理配置済みであり、データフローAに関する各プロセッシングエレメントの各メモリ内の設定値は固定値として与えられるものとする。データフローBに関しては処理配置対象である。つまりデータフローの処理順序は決まっており、既に配置済みの配置情報をもとに次に処理されるデータフローの配置を決定することを想定している。
【0052】
図19は、データフローからデータフローへ処理を切り替えるための回路構成情報106を生成するための装置のブロック構成図を示している。図19において、2501は装置全体の制御を司るCPUである。2502はブートプログラムやBIOSを記憶しているROMである。2503はCPU2501のワークエリアとして利用され、且つ、OS(オペレーティングシステム)、アプリケーションを格納するためのRAMである。2504はOS、回路構成情報106を作成するためのアプリケーション、ならびに、様々なデータを格納するためのハードディスクドライブ(HDD)である。2505はキーボード、2506はマウスであり、ユーザインタフェースとして機能する。2507は内部にビデオメモリ及び表示コントローラを内蔵する表示制御部であり、2508は表示制御部2507からの映像信号を受信し、表示するための表示装置である。2509は各種外部デバイスと通信するインタフェースであり、例えば、図1に示した外部メモリ101を接続することで、本装置が作成した回路構成情報106をその外部メモリ101に書込むことになる。
【0053】
上記構成において、本装置に電源が投入されると、CPU2501はROM2502に格納されたブートプログラムを実行し、HDD2504に格納されたOSをRAMにロードし、その後、回路構成情報106を作成するアプリケーションを起動することで、本装置が回路構成情報作成装置として機能することになる。
【0054】
以下、本発明を実施するための回路構成情報作成装置として機能する本装置の処理を、図14のフローチャートを用いて説明する。本手順はシミュレーテッドアニーリングに基づく処理配置方法の例を示すが、本発明は上記手法のみに限定されるものではなく、遺伝的アルゴリズムなどのさまざまな近似解法や線形計画法や非線形計画法など数値最適化法でも良い。また、配置する問題の規模に応じて方法を変えてもよい。
【0055】
図13に示す各データフローを表すインデックスをi、ノードのインデックスをj、図6のアドレス601や図9で示したアドレス901に相当するエレメント内で保持しているメモリのコンフィギュレーションアドレスをkとする。また、各ノードj間のフローに関するインデックスをlとする。上記より各メモリ内の設定値はui,j,kと表すことができる。またi番目のデータフローにおける、フローlの出発側のノードをSi,l、到着側のノードをdi,lとする。
【0056】
また、図12に示す通り、各プロセッシングエレメントを表すインデックスをrとする。各データフローiの各ノードjの配置位置はxi,jおよびyi,jと表すことができる。本実施形態では同じプロセッシングエレメントに同じデータフロー内の異なる処理を配置することはしないため、xi,j、yi,jは、ノードjごとに必ず異なる。つまり、同じプロセッシングエレメントに異なる処理を配置しない。
【0057】
ここで処理配置済みのデータフローをi0、処理配置対象のデータフローをi1とする。初めに、ステップS1401では複数のデータフローとその順序関係(iの順序)を入力する。処理配置済みのデータフローに関しては、設定値ui0,j,kと共に配置情報xi0,j、yi0,jも入力する。
【0058】
次に、ステップS1402で要求仕様とハードウェアの制約の条件を入力する。ここでハードウェア制約条件とは、ヘテロ構成に伴う各プロセッシングエレメントが個別に持つ構成情報や、処理によって発生する発熱量などの制限などハードウェア構成上の制約となりうるものである。また要求仕様とは、プロセッシングエレメント間の距離制限やステップS1406で後述する設定変更数と距離の要素の優先度合の割合などハードウェア使用上で制限すべき項目である。ただし、本発明は上述の制約のみに限られるものではない。
【0059】
続いてステップS1403では対象となるデータフローの処理配置を行う。初期の処理の配置においては、ランダムに配置する、ないしはデータフローの深さ方向とプロセッシングエレメントアレイの入出力方向とを連動させて処理を配置させる方法があるが、これらの方法に限られるものではない。初期の配置でない場合は、シミュレーテッドアニーリングに基づき処理の配置を変更する。本実施形態では、処理配置である対象のデータフローBに関して初期処理配置、ないしは処理配置変更を行う。処理配置済みのデータフローAに関しては、制約に基づき処理配置の変更は行わない。
【0060】
ステップS1404では、処理配置結果がステップS1403で入力した要求仕様を満たしているか判断する。以下の式に示すように、制約を満たしていれば、ペナルティ変数p0を0とし、違反している場合はペナルティ変数p0をペナルティ値Cp0とする。
【0061】
【数1】
【0062】
ここで本実施形態では、違反があった場合に一律Cp0は定数値として扱っているが、違反項目に応じた変数値としてもよい。ステップS1405では、処理配置結果がステップS1302で入力したハードウェア制約条件を満たしているかを判断する。
【0063】
以下の式に示すように、制約を満たしていれば、ペナルティ変数p1を0とし、違反している場合はペナルティ変数p1をペナルティ値Cp1とする。
【0064】
【数2】
【0065】
ここで本実施形態では、違反があった場合に一律Cp1は定数値として扱っているが、違反項目に応じた変数値としてもよい。次にステップS1406では、対象となるデータフロー変更間における設定変更数と配置に基づく距離の算出を行い、評価値を計算する。まず設定変更数の算出について説明する。図13の例で説明するとの設定変更1339、1340、1341、1342の際に変更の必要がある設定数である。
【0066】
より具体的には、処理配置済みのデータフローi0における、設定値ui0,j,kと、処理配置対象のデータフローi1における、同じ位置に配置されたプロセッシングエレメントの同じ種類の設定値ui1,j,kの値が一致していなければα1を設定変更数に加える。上述の値が一致していれば何も加えない。
【0067】
ここで、プロセッシングエレメントrに配置されているデータフローi0のノードj0をj0rと表し、データフローi1のノードj1をj1rと表す。ここでrは前述したとおり、各プロセッシングエレメントを表すインデックスである。データフローが切り替わる際の同じ位置に配置されているノードの処理内容の変更に必要な設定変更数は以下の式で求めることができる。
【0068】
【数3】
【0069】
ここでα1は通常1であるが、プロセッシングエレメントのコンフィギュレーションメモリの構造に応じて、各設定が格納されているアドレス毎に重み付けを変更することも可能としている。またデータフロー毎に切り替え時間の優先度をつけるためにデータフロー毎に重みづけることも可能としている。図7で示した通り、一度のコンフィギュレーションコマンドで一つの設定値を変更することができることから、この数が少なくなれば、処理の切り替え時間を削減することが可能となる。
【0070】
続いて距離の算出について述べる。距離とは、配置対象であるデータフローBにおける距離1335、1336、1337、1338の合計量である。ステップS1403での配置とデータフローのデータ入出力関係に基づいて、以下の式で距離を表すことが可能である。
【0071】
【数4】
【0072】
ここでκ1l、λ1lはノード間の距離のx、y毎の重みであって、ノード間の距離などのアーキテクチャによって重みを一律ないしは別々に変更することも可能である。本ステップで評価値算出する際の式は上述の式より、以下と定義する。
【0073】
【数5】
【0074】
ここで、δはステップS1402で与えた設定変更数と距離のどちらを優先させるかの割合を表す指標である。つまり、要求仕様とハードウェア制約条件を満たしつつ、また距離が少なく、再構成に必要な設定変更数が少なくなるほど上記評価値は小さくなる。
【0075】
最後にステップS1407では、シミュレーテッドアニーリングに基づき目標達成したかを判断し、目標を達成した場合は終了する。目標未達の場合はステップS1403に戻り、ステップS1403〜S1407を繰り返し行う。ここで、目標値とは十分良い結果が得られるまで、もしくは予定された計算時間に達するまで繰り返す。
【0076】
以上の結果、回路構成情報106がHDD2504に生成されるので、後はインタフェース2509を介して、利用する外部メモリ101にそれを書き出し、実製品に搭載すれば良いことになる。
【0077】
なお、上記実施形態では、回路構成情報106を、外部装置(図17)にて作成する例を示した。これは以降に説明する全実施形態でも同じである。また、コンフィギュレーションコントローラ102が外部装置の代わりに、図13の処理を実行し、回路構成情報106を作成しても構わない。例えば、外部メモリ101に複数のデータフロー毎の設定(必要なプロセッサ数と各プロセッサの処理パラメータ)を保持させ、コンフィギュレーションコントローラ102が複数のデータフローの設定に基づいて回路構成106を作成すればよい。係る点も、以降に説明する全実施形態にも適用できることである。
【0078】
一般的な再構成デバイスにおけるデータフローのプロセッシングエレメントへの処理配置方法では設定変更数を意識しないため、データフローの処理変更間で全ての設定を変更する必要が生じる。
【0079】
本実施形態では、データフローの処理順に注目し、距離に加え設定変更の合計数が少なくすることで、設定変更数削減を効果的に行うことが可能となる。
【0080】
次に、本発明の第2の実施形態について説明する。第2の実施形態に係る処理のタイムチャートおよび、処理配置の概要を図15に示す。本実施形態では再構成デバイスの設定を変更において、各データフローの処理内容自体は決まっているが、その変更順序が不定で、状況や入力データなどに応じて変わる場合の処理配置に関する実施形態である。
【0081】
タイムチャート1501における期間1502ではデータフローAに関する処理が行われ、期間1504、1508ではデータフローCに関する処理が行われ、期間1506ではデータフローBに関する処理が行われる。期間1503ではデータフローAからデータフローCの設定変更が行われる。期間1505ではデータフローCからデータフローBの設定変更が行われる。期間1507ではデータフローBからデータフローCの設定変更が行われる。本実施形態では、データフローA、B、Cの処理変更の順序が一定でないため、それぞれのデータフロー間の全ての設定変更を考慮して処理の配置を行う必要がある。
【0082】
図中の1509、1522、1431はそれぞれデータフローA、B、Cにおけるプロセッシングエレメントの配置例を示しており、ここではこれら全てのデータフローの処理の配置を一度に一括して行う。なお配置例1509、1522、1531中のプロセッシングエレメント1510、1511、1512、1513はそれぞれ物理的に同じプロセッシングエレメントを指す。
【0083】
設定1514、1515、1516、1517は、それぞれデータフローAの配置におけるプロセッシングエレメント1510、1511、1512、1513への設定を表している。設定1523、1524、1525、1526は、それぞれデータフローBの配置におけるプロセッシングエレメント1510、1511、1512、1513への設定を表している。設定1532、1533、1534、1535は、それぞれデータフローCの配置におけるプロセッシングエレメント1510、1511、1512、1513への設定を表している。ここで上記の設定とは実施形態1と同様に、図6で説明した設定のことである。本実施形態では、データフローA、B間、B、C間、C、A間のプロセッシングエレメント1510、1511、1512、1513でデータフロー変更に必要な合計の設定変更数と各プロセッシングエレメント間接続の合計距離に注目する。
【0084】
上記合計数および距離数が図14で示したフローチャート1406で示す評価値に加える設定変更数を後述する評価値として算出することで、距離を考慮した、再構成デバイスの再構成時の設定変更数の削減を行う。
【0085】
なお、データフローA、B間でのプロセッシングエレメント1510、1511、1512、1513の設定変更は1539で表している。またデータフローB、C間でのプロセッシングエレメント1510、1511、1512、1513の設定変更は1540で表している。データフローC、A間でのプロセッシングエレメント1510、1511、1512、1513の設定変更は1541で表している。
【0086】
本実施形態と第1の実施形態との違いは、同時に複数のデータフローの処理配置を行う点にある。図14のステップS1401では、複数のデータフローを入力すると同時に、処理順序が任意であることを入力する。図14のステップS1404で行う処理配置では、処理配置対象であるデータフローA、B、C全てに対して処理配置を行う。図14のステップS1406で第1の実施形態に対して以下の違いがある。
【0087】
処理配置対象のデータフローi0における、設定値uio,j,kと、処理配置対象のデータフローi1における、同じ位置に配置されたプロセッシングエレメントの同じ種類の設定値ui1,j,kの値が一致していなければα2を設定変更数に加える。また、処理配置対象のデータフローi1における、設定値ui1,j,kと、処理配置対象のデータフローi2における、同じ位置に配置されたプロセッシングエレメントの同じ種類の設定値ui2,j,kの値が一致していなければβ2を設定変更数に加える。さらに、処理配置対象のデータフローi2における、設定値ui2,j,kと、処理配置対象のデータフローi0における、同じ位置に配置されたプロセッシングエレメントの同じ種類の設定値ui0,j,kの値が一致していなければγ2を設定変更数に加える。上述以外で、設定値が一致していれ場合は何も加えない。
【0088】
ここで、プロセッシングエレメントrに配置されているデータフローi0のノードj0をj0rと表し、データフローi1のノードj1をj1rと表し、データフローi2のノードj2をj2rと表す。ここでrは前述したとおり、各プロセッシングエレメントを表すインデックスである。
【0089】
データフローが切り替わる際に、同じ位置に配置されているノードの処理内容の変更に必要な設定変更数は以下の式で求めることができる。
【0090】
【数6】
【0091】
ここでα2、β2、γ2は通常それぞれ1であるが、プロセッシングエレメントのコンフィギュレーションメモリの構造に応じて、各設定が格納されているアドレス毎に重み付けを変更することも可能としている。またデータフロー毎に切り替え時間の優先度をつけるためにデータフロー毎に重みづけることも可能としている。
【0092】
また距離については以下の違いがある。図15で示した例では、距離は、距離1518、1519、1520、1521、1527、1528、1529、1530、1536、1537、1538の合計量として表される。図中のプロセッシングエレメントの配置は一例を示してだけであり、配置を変更することでこれらの距離合計量も変わる。配置後にその配置と、データフローのデータ入出力に基づいて以下の式で距離を表すことが可能である。
【0093】
【数7】
【0094】
ここでκ2i,l、λ2i,lは、データフロー毎のノード間の距離などのアーキテクチャによって重みを一律ないしは別々に変更することも可能である。本実施形態により、全てのデータフロー間を考慮することで、処理の実行順序が不定な場合でも、距離を考慮したうえで平均して設定変更数削減効果が得られる。
【0095】
次に、本発明の第3の実施形態について説明する。第3の実施形態に係る処理のタイムチャートおよび、処理配置の概要を図16に示す。本実施形態では既に複数のデータフローの処理順序およびそれぞれの処理配置も決まっている場合を想定している。上述の処理順序における任意のデータフローの処理間に、挿入前後の処理配置は変えずに、新たなデータフローに対応した処理を挿入するための処理配置に関する実施形態である。
【0096】
図16のタイムチャート1601は再構成デバイスで行う処理順序が既に決められ、その処理配置も決められているタイムチャートである。タイムチャート1601ではデータフローAの処理1603後、データフローAの設定からデータフローCの設定へ変更する期間1604を経てデータフローCの処理1605を行っている。このタイムチャート1601のデータフローAとデータフローC間に新たにデータフローBを挿入したタイムチャートがタイムチャート1602である。データフローAの処理1603の後にデータフローAの設定からデータフローBの設定へ変更する期間1606を経て新たに挿入したデータフローBの処理1607が行われる。その後データフローBの設定からデータフローCの設定へ変更する期間1608を経てデータフローBの処理1605が行われる。この際データフローAとCの処理配置は変更せずにデータフローBの処理配置を決定するため、挿入する前後の既に処理配置済みのデータフロー間の設定変更量を考慮する。
【0097】
図中の1609、1622、1631はそれぞれデータフローA、B、Cにおけるプロセッシングエレメントの配置例を示している。本実施形態ではデータフローAおよびCは処理配置済みであり、データフローBの処理配置を行う。なお配置例1609、1622、1631中のプロセッシングエレメント1610、1611、1612、1613はそれぞれ同じプロセッシングエレメントを指す。
【0098】
設定1614、1615、1616、1617は、それぞれデータフローAの配置におけるプロセッシングエレメント1610、1611、1612、1613への設定を表している。設定1623、1624、1625、1626は、それぞれデータフローBの配置におけるプロセッシングエレメント1610、1611、1612、1613への設定を表している。設定1632、1633、1634、1635は、それぞれデータフローCの配置におけるプロセッシングエレメント1610、1611、1612、1613への設定を表している。ここで上記の設定とは実施形態1と同様に、図6で説明した設定のことである。本実施形態では、データフローA、B間、B、C間、C、A間のプロセッシングエレメント1610、1611、1612、1613でデータフロー変更に必要な合計の設定変更数と各プロセッシングエレメント間接続の合計距離に注目する。
【0099】
なお、新たに挿入するデータフローBに伴う、データフローA、B間でのプロセッシングエレメント1610、1611、1612、1613の設定変更は1639で表している。またデータフローB、C間でのプロセッシングエレメント1610、1611、1612、1613の設定変更は1640で表している。
【0100】
本実施形態と第1の実施形態との違いは、複数の処理配置済みのデータフローを参照して、対象となるデータフローの処理配置を行う点である。
【0101】
図14のステップS1403で行う処理配置は、データフローBのみが対象である。データフローA、Cは処理配置済みであり、処理配置変更は行わない。図14のステップS1406では第一の実施形態に対して以下の違いがある。
【0102】
処理配置済みのデータフローi0における、設定値ui0,j,kと、処理配置対象のデータフローi1における、同じ位置に配置されたプロセッシングエレメントの設定値ui1,j,kの値が一致していなければα3を設定変更数に加える。また、処理配置対象のデータフローi1における、設定値ui1,j,kと、処理配置済みのデータフローi2における、同じ位置に配置されたプロセッシングエレメントの設定値ui2,j,kの値が一致していなければβ3を設定変更数に加える。上述の値が一致していなければ何も加えない。
【0103】
ここで、あるプロセッシングエレメントrに配置されているデータフローi0のノードj0をj0rと表し、データフローi1のノードj1をj1rと表し、データフローi2のノードj2をj2rと表す。ここでrは前述したとおり、各プロセッシングエレメントを表すインデックスである。
【0104】
データフローが切り替わる際の同じ位置に配置されているノードの処理内容の変更に必要な設定変更数は以下の式で求めることができる。
【0105】
【数8】
【0106】
またα3、β3は通常それぞれ1であるが、プロセッシングエレメントのコンフィギュレーションメモリの構造に応じて、各設定が格納されているアドレス毎に重み付けを変更することも可能としている。またデータフロー毎に切り替え時間の優先度をつけるためにデータフロー毎に重みづけることも可能としている。
【0107】
また距離については以下の違いがある。図16で示した例では、距離は、距離1618、1619、1620、1621、1627、1628、1629、1630、1636、1637、1638の合計量として表される。図中のプロセッシングエレメントの配置は一例を示してだけであり、配置を変更することでこれらの距離合計量も変わる。配置後にその配置と、データフローのデータ入出力に基づいて以下の式で距離を表すことが可能である。
【0108】
【数9】
【0109】
ここでκ3l、λ3lは、データフロー毎のノード間の距離などのアーキテクチャによって重みを一律ないしは別々に変更することも可能である。新たにデータフロー挿入する場合に、挿入前後のデータフローとの設定変更数の削減に関する効果が得られる。
【0110】
次に、本発明の第4の実施形態について説明する。第4の実施形態に係る処理のタイムチャートおよび、処理配置の概要を図17に示す。本実施形態では、ある基準となるデータフローの処理後、その結果に応じて次に行われるデータフローが異なる場合の処理配置に関する実施形態である。
【0111】
図17のタイムチャート1701は基準となるデータフローXの処理を期間1702で行った後、その結果に応じて、データフローXからデータフローAかBかCへの設定変更を期間1703で行う。設定完了後、データフローAかBかCの処理が期間1704で行われ、再度基準となるデータフローXの処理を行うため期間1705でデータフローAかBかCからデータフローXへと設定変更を行う。上記順序が繰り返されが、データフローAかBかCのどれが行われるかはデータフローXの結果に応じて変わる。
【0112】
図中の1706、1719、1728、1737はそれぞれデータフローX、A、B、Cにおける配置例を示している。本実施形態では、データフローX、A、B、Cの全てのデータフローの処理配置を行う。なお配置例1706、1719、1728、1737中のプロセッシングエレメント1707、1708、1709、1710はそれぞれ同じプロセッシングエレメントを指す。
【0113】
設定1711、1712、1713、1714は、それぞれデータフローXの配置におけるプロセッシングエレメント1707、1708、1709、1710への設定を表している。設定1720、1721、1722、1723は、それぞれデータフローAの配置におけるプロセッシングエレメント1707、1708、1709、1710への設定を表している。設定1729、1730、1731、1732は、それぞれデータフローBの配置におけるプロセッシングエレメント1707、1708、1709、1710への設定を表している。設定1738、1739、1740、1741は、それぞれデータフローCの配置におけるプロセッシングエレメント1707、1708、1709、1710への設定を表している。ここで上記の設定とは第1の実施形態と同様に、図6で説明した設定のことである。
【0114】
本実施形態では具体的には、データフローX、A、B、Cの処理配置を行う。処理配置に際して、データフローX、A間、X、B間、X、C間のプロセッシングエレメント1707、1708、1709、1710でデータフロー変更に必要な設定変更数の合計数と各プロセッシングエレメント間接続の合計距離に注目する。
【0115】
なお、データフローX、A間でのプロセッシングエレメント1707、1708、1709、1710の設定変更は1745で表している。データフローX、B間でのプロセッシングエレメント1707、1708、1709、1710の設定変更は1746で表している。
【0116】
データフローX、C間でのプロセッシングエレメント1707、1708、1709、1710の設定変更は1747で表している。
【0117】
本実施形態と第1の実施形態との違いは、処理順序に分岐があり、分岐先と分岐元間のデータフローに対して処理配置を行う点にある。
【0118】
図13のステップS1301では、複数のデータフローを入力すると同時に、部分的に任意の順序関係を含んだ処理順序を入力する。ここで部分的な任意とは本実施形態では実行順序に分岐があり、分岐元と分岐先の実行順序のみ任意であるということを指す。
【0119】
図14のステップS1403で行う処理配置は、処理配置対象であるデータフローX、A、B、Cの全てに対して処理配置を行う。本実施形態では全てのデータフローを処理配置対象として扱う例を示しているが、それに限ったものではない。本実施形態は処理順序に注目したものであり、少なくとも一つのデータフローが、既に処理配置済みの場合には、それ以外のデータフローの処理配置を行うこととなる。
【0120】
図14のステップS1406では第1の実施形態に対して以下の違いがある。処理配置対象のデータフローi0における、設定値ui0,j,kと、処理配置対象のデータフローi1における、同じ位置に配置されたプロセッシングエレメントの同じ種類の設定値ui1,j,kの値が一致していなければα4を設定変更数に加える。また、処理配置対象のデータフローi0における、設定値ui0,j,kと、処理配置対象のデータフローi2における、同じ位置に配置されたプロセッシングエレメントの同じ種類の設定値ui2,j,kの値が一致していなければβ4を設定変更数に加える。さらに、処理配置対象のデータフローi0における、設定値ui0,j,kと、処理配置対象のデータフローi3における、同じ位置に配置されたプロセッシングエレメントの同じ種類の設定値ui3,j,kの値が一致していなければγ4を設定変更数に加える。上述以外で、設定値が一致している場合は何も加えない。
【0121】
ここで、あるプロセッシングエレメントrに配置されているデータフローi0のノードj0をj0rと表し、データフローi1のノードj1をj1rと表し、データフローi2のノードj2をj2rと表し、データフローi3のノードj3をj3rと表す。ここでrは前述したとおり、各プロセッシングエレメントを表すインデックスである。
【0122】
データフローが切り替わる際の同じ位置に配置されているノードの処理内容の変更に必要な設定変更数は以下の式で求めることができる。
【0123】
【数10】
【0124】
ここでα4、β4、γ4は通常それぞれ1であるが、プロセッシングエレメントのコンフィギュレーションメモリの構造に応じて、各設定が格納されているアドレス毎に重み付けを変更することも可能としている。またデータフロー毎に切り替え時間の優先度をつけるためにデータフロー毎に重みづけることも可能としている。
【0125】
また距離については以下の違いがある。図17で示した例では、距離は、距離1715、1716、1717、1718、1724、1725、1726、1727、1733、1734、1735、1736、1742、1743、1744の合計量として表される。図中のプロセッシングエレメントの配置は一例を示してだけであり、配置を変更することでこれらの距離合計量も変わる。配置後にその配置と、データフローのデータ入出力に基づいて以下の式で距離を表すことが可能である。
【0126】
【数11】
【0127】
ここで、κ4i,l、λ4i,lは、データフロー毎のノード間の距離などのアーキテクチャによって重みを一律ないしは別々に変更することも可能である。本実施形態により、複数のデータフローを順々に行う上で、その実行順序に分岐がある場合でも、分岐元となるデータフローと分岐先となる複数の他のデータフローを考慮することで、設定変更数削減効果が得られる。
【0128】
次に、本発明の第5の実施形態について説明する。第5の実施形態に係るデータフローと処理配置制限方法に関する概要を図18に示す。処理配置問題は一般的に難しく解算出のための時間が大きくかかる場合が多い。本発明のように複数のデータフローを同時に配置させる場合はさらに問題が大きくなる。そのため本実施形態では処理の配置可能範囲を制限することで効果的に解算出時間を短縮する。
【0129】
データフロー1819は複数の処理に対応するノード1801〜1818で構成されている。また1826はプロセッシングエレメントアレイに対する入力装置を1820、出力装置を1821とし、それらの間にプロセッシングエレメントアレイがある構成となっている。
【0130】
本実施形態では、これらをデータフロー1819の処理を配置モデル1201に配置させる際、データフローの深さ方向とプロセッシングエレメントアレイへの入出力の位置を対応させることで解空間を効率的に狭める。具体的にはノード1801から1804は1821で示した範囲のみ配置可能と設定する。また1805から1810は1822で示した範囲のみ配置可能と設定する。また1811から1814は1822で示した範囲のみ配置可能と設定する。また1815から1818は1823で示した範囲のみ配置可能と設定する。
【0131】
これらの制限は図14のステップS1402で入力することを想定している。本実施形態では配置可能範囲はデータフローの深さとプロセッシングエレメントアレイの入出力の方向に対応付けさせたが、それに限るものではない。
【0132】
上述した実施形態では、ユースケース別に各々の処理配置方法について述べたが、本発明はこれらの方法の組み合わせでも良い。また、再構成デバイスの構成要素としてプロセッシングエレメントを説明したが、これに限るものではなく、LUTや、それとの組み合わせでも良い。また、設定は、実施形態で示した設定に限るものではなく、LUTベースの再構成デバイスで使用される設定でも良い。また、実施形態では入力するデータフロー全てに対して処理配置対象としたが、データフローの処理配置対象範囲を指定することで、データフローの一部のみに対して処理配置を行っても良い。また、実施形態ではプロセッシングエレメント数はデータフロー間で同じとしているが、処理を配置するプロセッシングエレメント数が異なっても良い。また、実施形態で示した、距離合計値が少なくなるように記載しているが、各距離の最大値が小さくなるように配置を決定しても良い。また、各距離の平均値が少なくなるように配置を決定しても良い。
【0133】
上述した実施形態ではプロセッシングエレメントは格子状に均一に配置され、それぞれのプロセッシングエレメント間の接続距離は一定を前提に記載したが、これに限るものではない。プロセッシングエレメントの接続形態が例えば木構造のように接続されている場合はそれぞれの距離は、木構造に応じて重みづけても良い。つまり、プロセッシングエレメントの接続形態に応じてそれぞれの距離を重みづけても良い。
【0134】
また、本発明は、以下の処理を実行することによっても実現される。即ち、上述した実施形態の機能を実現するソフトウェア(プログラム)を、ネットワーク又は各種記憶媒体を介してシステム或いは装置に供給し、そのシステム或いは装置のコンピュータ(またはCPUやMPU等)がプログラムを読み出して実行する処理である。
【特許請求の範囲】
【請求項1】
複数の構成要素で構成される再構成デバイスに対し、データフローの各処理を行う構成要素を決定するための処理配置方法であって、
少なくとも二つの異なるデータフローと前記データフローの処理順序を入力する入力ステップと、
再構成デバイスの構成要素の制約を入力する制約ステップと、
前記データフローに応じた、前記再構成に必要な設定変更数と前記データフローのデータ入出力の依存関係に基づく構成要素間の距離とを用い、構成要素の配置を決めることで、要求される処理をどの構成要素で実行させるかを決定する決定ステップとを有することを特徴とする処理配置方法。
【請求項2】
前記制約は、データフローの構成と再構成デバイスの構成に合わせてデータフロー内の各処理ごとに配置可能範囲を限定する制約を含むことを特徴とする請求項1に記載の処理配置方法。
【請求項3】
前記設定変更数は、データフロー毎あるいは前記構成要素の処理内容を決定する設定に重み付けられることを特徴とする請求項1に記載の処理配置方法。
【請求項4】
前記構成要素間の接続の距離は前記構成要素に重み付けられることを特徴とする請求項1に記載の処理配置方法。
【請求項5】
複数の構成要素で構成される再構成デバイスに対し、データフローの各処理を行う構成要素を決定するための処理配置方法をコンピュータに実行させるためのプログラムであって、
少なくとも二つの異なるデータフローと前記データフローの処理順序を入力する入力ステップと、
再構成デバイスの構成要素の制約を入力する制約ステップと、
前記データフローに応じた、前記再構成に必要な設定変更数と前記データフローのデータ入出力の依存関係に基づく構成要素間の距離とを用い、構成要素の配置を決めることで、要求される処理をどの構成要素で実行させるかを決定する決定ステップとをコンピュータに実行させるためのプログラム。
【請求項6】
請求項1に記載の処理配置方法によって生成された設定情報に基づいて動作する再構成デバイス。
【請求項1】
複数の構成要素で構成される再構成デバイスに対し、データフローの各処理を行う構成要素を決定するための処理配置方法であって、
少なくとも二つの異なるデータフローと前記データフローの処理順序を入力する入力ステップと、
再構成デバイスの構成要素の制約を入力する制約ステップと、
前記データフローに応じた、前記再構成に必要な設定変更数と前記データフローのデータ入出力の依存関係に基づく構成要素間の距離とを用い、構成要素の配置を決めることで、要求される処理をどの構成要素で実行させるかを決定する決定ステップとを有することを特徴とする処理配置方法。
【請求項2】
前記制約は、データフローの構成と再構成デバイスの構成に合わせてデータフロー内の各処理ごとに配置可能範囲を限定する制約を含むことを特徴とする請求項1に記載の処理配置方法。
【請求項3】
前記設定変更数は、データフロー毎あるいは前記構成要素の処理内容を決定する設定に重み付けられることを特徴とする請求項1に記載の処理配置方法。
【請求項4】
前記構成要素間の接続の距離は前記構成要素に重み付けられることを特徴とする請求項1に記載の処理配置方法。
【請求項5】
複数の構成要素で構成される再構成デバイスに対し、データフローの各処理を行う構成要素を決定するための処理配置方法をコンピュータに実行させるためのプログラムであって、
少なくとも二つの異なるデータフローと前記データフローの処理順序を入力する入力ステップと、
再構成デバイスの構成要素の制約を入力する制約ステップと、
前記データフローに応じた、前記再構成に必要な設定変更数と前記データフローのデータ入出力の依存関係に基づく構成要素間の距離とを用い、構成要素の配置を決めることで、要求される処理をどの構成要素で実行させるかを決定する決定ステップとをコンピュータに実行させるためのプログラム。
【請求項6】
請求項1に記載の処理配置方法によって生成された設定情報に基づいて動作する再構成デバイス。
【図1】


【図2】
【図3】

【図4】

【図5】
【図6】

【図7】

【図8】

【図9】

【図10】

【図11】

【図12】
【図13】

【図14】
【図15】
【図16】

【図17】

【図18】
【図19】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【公開番号】特開2012−185803(P2012−185803A)
【公開日】平成24年9月27日(2012.9.27)
【国際特許分類】
【出願番号】特願2012−3035(P2012−3035)
【出願日】平成24年1月11日(2012.1.11)
【出願人】(000001007)キヤノン株式会社 (59,756)
【Fターム(参考)】
【公開日】平成24年9月27日(2012.9.27)
【国際特許分類】
【出願日】平成24年1月11日(2012.1.11)
【出願人】(000001007)キヤノン株式会社 (59,756)
【Fターム(参考)】
[ Back to top ]