
Fターム[5B042MC28]の内容
デバッグ、監視 (27,428) | 表示又は記録する内容 (5,146) | 計算値 (364)
Fターム[5B042MC28]の下位に属するFターム
Fターム[5B042MC28]に分類される特許
21 - 40 / 148
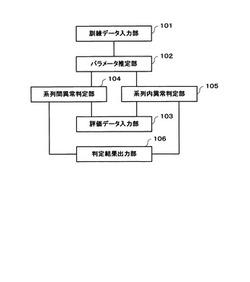
異常判定装置、異常判定プログラムおよび異常判定方法
【課題】入力されたデータにもとづいて、発生した異常の種類を判定する異常判定装置を提供する。
【解決手段】訓練データ入力部101が、異常判定装置の外部から訓練データおよび予め設定されたパラメータを入力する。パラメータ推定部102が、入力された訓練データにもとづいて、線形混合モデルのパラメータの推定値を求める。評価データ入力部103が、入力された評価データにもとづいて、線形回帰分析モデルのパラメータの推定値を求める。系列間異常判定部104が、線形混合モデルのパラメータの推定値と、線形回帰分析モデルのパラメータの推定値とにもとづいて系列間異常が生じたか否かを判定する。系列内異常判定部105が、線形混合モデルのパラメータの推定値と、線形回帰モデルのパラメータの推定値とにもとづいて系列内異常が生じたか否かを判定する。
(もっと読む)
性能計測分析支援プログラムおよび性能計測分析支援装置

【課題】計算機システムの性能の分析を支援することを可能とする。
【解決手段】制御部55は、計算機システムにおいて同一の業務処理が実行された期間の各々を示す計測期間情報を取得する。パターン抽出部52は、格納部42に格納されている計測期間情報によって示される期間内に該当する時刻を示すタイムスタンプ情報を含むパケットデータから構成されるデータセットを当該期間毎に作成する。パターン抽出部52は、期間毎に作成されたデータセット間において送信元情報および送信先情報が共通するパケットデータを時系列順に当該データのセットの各々から抽出する。ログ集計部53は、パターン抽出部52によって抽出された送信元情報および送信先情報が共通するパケットデータに基づいてノード毎の性能を表す性能情報を集計する。結果表示部54は、ノード毎の性能情報を出力する。
(もっと読む)
ソフトウェアの加速試験装置及び加速試験方法
【課題】ソフトウェアの加速試験を効率的に実行することのできるソフトウェアの加速試験装置及び加速試験方法を提供する。
【解決手段】クロック発生器17、時計機能18及びCPU11を有し、このCPU上で稼動するソフトウェアの加速試験を行うソフトウェアの加速試験装置において、クロック発生器のクロック周波数を加算して変更する前と変更後のそれぞれについて単位時間あたりのCPUによる所定の演算の繰返し回数を取得して、変更前に対する変更後の演算の繰返し回数の比を求める加速比率取得手段22と、時計機能の計時値を加算して変更する前に対する変更後の計時値の比率が、加速比率取得手段で求めた演算の繰返し回数の比と略等しくなるように時計機能の計時値を加算する時計加速手段23とを備えたソフトウェアの加速試験装置である。
(もっと読む)
監視システム、監視装置、サービス実行環境の監視方法、及び監視装置用プログラム
【課題】装置使用者がサービス実行環境に関する膨大な知識や経験を有することなく監視ルールを適切に修正可能ならしめる監視システム等を提供する。
【解決手段】サービス実行環境30の状態が監視ルールの各監視条件を満たすか否かを判定する分析部11を備え各判定の違いを検出して当該各監視条件にかかる監視設定が不適切であることを示す監視不良を告知可能としたマネージャ装置10を備えた監視システムであって、前記マネージャ装置10が、前記各判定に使用された各監視条件に対応するサービス実行環境30の状態(各性能情報)を履歴として各々蓄積する分析履歴蓄積部19と、複数の各監視条件が異なる判定結果の場合に前記分析履歴蓄積部19の性能情報の履歴に基づいて前記複数の各監視条件が同一の判定結果となるしきい値を算出しこれを前記監視不良の修正にかかる監視条件として生成する条件生成部18と、を備えたこと。
(もっと読む)
プログラム診断装置およびプログラム診断方法
【課題】ソフトウェアに基づきシステムの伝送処理の応答性を診断することが可能なプログラム診断装置を提供する。
【解決手段】本発明のプログラム診断装置100は、機器間の伝送処理を規定するプログラムを診断する装置であって、所定の関数を実行したときの処理に要する関数処理時間を記憶する関数情報記憶部180と、プログラムのソースから使用されている関数を抽出するプログラム読取部120と、関数情報記憶部180より抽出された関数の関数処理時間を取得して、プログラムのソースの実行に要する全処理時間を算出し、当該プログラムを実行する機器内での最大許容処理時間と全処理時間とを比較して、機器間の伝送処理の応答性の良否を判定するプログラム判定部130と、を備える。プログラム判定部130は、全処理時間が最大許容処理時間より大きいとき、機器間の伝送処理の応答性に問題があると判定する。
(もっと読む)
運用管理装置、運用管理方法、運用管理プログラム
【課題】システムを構成する各ノードのシステムの動作に対する影響度を提示する。
【解決手段】サービスシステムを構成する各ノード40の健全動作率を用いて、ネットワークシステムの論理トポロジに基づく演算を行うことにより、直属関係にあるノードそれぞれの健全動作率の算出する健全動作率算出部11と、各ノードで動作障害が生じた場合に最上位ノードの健全動作率を低下させる影響の度合いを示す各ノードのインパクト値を健全動作率に基づき算出するインパクト値算出部12を備えた運用管理装置20。
(もっと読む)
イベント予測システムおよびイベント予測方法、ならびにコンピュータ・プログラム
【課題】装置障害等のイベントの発生を事前に予測する。
【解決手段】監視対象装置で発生し得るイベントとそのイベント発生原因との対応関係およびイベント発生原因間の遷移を有限オートマトンでモデル化した初期イベント発生モデルと、学習用イベント列とに基づいて、イベント発生原因ごとに各イベントが発生する確率およびイベント発生原因間の遷移の確率を算出し、イベント発生モデルを生成するイベント発生モデル学習部12と、このイベント発生モデルに基づいて、障害原因発見用イベント列が観察される確率が最も高いと考えられる状態遷移列を求める状態遷移列計算部13と、イベント発生モデルと状態遷移列計算部13によって求められた状態遷移列とに基づいて、監視対象装置で将来発生し得るイベントを予測するフィルタリングモジュール14とを備える。
(もっと読む)
異常検出装置、異常検出システム、異常検出方法、及び、プログラム
【課題】原因装置群を高い精度にて特定することが可能な異常検出装置を提供すること。
【解決手段】異常検出装置100は、互いに関連して作動する複数の装置を含むシステムに適用される。異常検出装置100は、上記システムの作動状態の特徴を表す特徴量を取得する特徴量取得部101と、上記取得された特徴量に基づいて、上記特徴量を確率変数とする確率分布を取得する確率分布取得部102と、上記取得された確率分布と、上記特徴量を確率変数とする確率分布の基準となる基準確率分布と、の差に基づいて、上記システムの作動状態が異常状態にあるか否かを判定する作動状態判定部103と、上記システムの作動状態が異常状態となった基となる装置群である原因装置群を、上記取得された確率分布の基準確率分布からの変化に対して当該装置群が及ぼす影響の大きさと、当該装置群を構成する装置の数と、に基づいて特定する原因装置群特定部104と、を備える。
(もっと読む)
運用管理装置、運用管理システム、情報処理方法、及び運用管理プログラム
【課題】本発明は、障害の予兆を検出し、発生場所の特定が可能な運用管理装置を提供する。
【解決手段】運用管理装置は、性能種目又は被管理装置を要素とし、少なくとも第1の要素に関する性能情報の時系列変化を示す第1の性能系列情報と、第2の要素に関する性能情報の時系列変化を示す第2の性能系列情報との相関関数を導出し、この相関関数に基づいて相関モデルを生成しこの相関モデルを各要素間の組み合わせについて求める相関モデル生成部123と、被管理装置から新たに検出し取得される性能情報に基づいて、相関モデルの変化を分析する相関変化分析部124を含む。
(もっと読む)
システム使用率管理装置及びそれに用いるシステム使用率管理方法並びにそのプログラム
【課題】 性能やアーキテクチャの異なる複数の計算ノードで構成される計算機システムに対して、システム性能の管理や運用ノード数の最適化を容易に行うことが可能なシステム使用率管理装置を提供する。
【解決手段】 処理装置11のノード最大性能設定手段111は外部のシステムを構成する各ノードの最大性能を記憶装置12のノード最大性能記憶部121に格納する。リソース使用率取得手段112は各ノードのリソース使用率101を取得し、仮想使用率算出部113に付与する。仮想使用率算出部113はノード最大性能記憶部121に保持された各ノードの最大性能と付与された各ノードのリソース使用率とからシステムの仮想的な使用率を算出し、その仮想的な使用率を出力部114に付与する。出力部114は付与された仮想的な使用率を出力装置13に出力する。
(もっと読む)
並列プログラム解析結果表示装置および並列プログラム解析結果表示方法
【課題】並列プログラムの実行時に発生する遅延に基づいて、並列プログラムを改善する指針、および並列プログラムの実行環境の改善の指針を与えること。
【解決手段】並列プログラムの実行環境の性能が記述されたターゲット性能パラメータ、並列プログラムのプロファイルデータ、および並列プログラムに記述されているタスク間のデータを介した依存関係を表す第1タスク依存グラフに基づいて、各タスクに対して第1データ遅延情報および第1タスク遅延情報を計算する遅延情報計算モジュールと、並列プログラムから選択されたタスクに対して、第1タスク遅延情報および第1データ遅延情報に基づいて、当該選択されたタスク、当該選択されたタスクに依存するタスク、第1タスク遅延情報、および第1データ遅延情報を表す映像を表示画面上に表示する遅延情報表示モジュールと、を具備する。
(もっと読む)
運用管理プログラム、運用管理装置および運用管理方法
【課題】ボトルネック候補となる情報処理装置を適切に検出すること。
【解決手段】計数部1bは、情報処理装置から取得した、所定の時間間隔で得られたN(Nは1≦Nの整数)個のサンプリングタイミングから、各サンプリングタイミング時に情報処理装置が処理中の処理要求の数を示す値Xi(iは1≦i≦Nの整数)を得る。処理部1cは、Xiの総和に対する、Xiの最大値との差分が所定範囲内にあるXiの総和の割合を求める処理を、複数の情報処理装置について行い、求めた割合が所定値以上の情報処理処置を検出する。
(もっと読む)
進捗情報表示装置、進捗情報表示方法、及び進捗情報表示プログラム
【課題】 進捗情報表示装置が、情報処理システムの情報処理の処理速度の変化に応じて情報処理の進捗状況を示す進捗情報を表示できない。
【解決手段】 進捗情報表示装置は、情報処理システムにおける情報処理の処理速度を特定する処理速度特定部と、前記情報処理システムにおける情報処理の進捗状況を示す進捗情報を、前記処理速度に比例した速度である標準速度で変化させて表示する表示部と、前記処理速度に基づいて算出される前記処理速度の加速度が第一の閾値以下の場合に、前記表示部に表示させる前記進捗情報の変化速度を前記標準速度とは異なる速度に変更する変更部と、を備える。
(もっと読む)
運用情報管理システム、運用情報管理方法、運用情報管理プログラム
【課題】監視対象機器における動作状態を示す情報を重要度に基づき管理する。
【解決手段】監視対象機器4における動作内容を示すメッセージを取得し予め設定されたフィルタ条件に基づくフィルタリングを行うフィルタ適用部201と、このフィルタリングにより抽出したメッセージを蓄積するメッセージ蓄積部204と、抽出されたメッセージ以外のメッセージから検索条件に適合するメッセージの検索を行うメッセージ検索部208と、各検索条件の検索に利用された回数と検索でヒットしたメッセージの数との関係に基づき検索結果に重み値を設定する検索条件適用手段203と、設定された重み値が一定値を超えた場合にこの検索条件をフィルタリング条件に設定するフィルタ登録実施手段210を備えた。
(もっと読む)
異常検出装置、及び異常検出方法
【課題】より高精度に異常を検出することができる異常検出装置、及び異常検出方法を提供する。
【解決手段】異常検出装置は、ソフトウェアを実行して処理データをメモリ上に展開し、前記メモリのデータ値とデータ値を記憶する時間を示す時間情報Tとを複数記憶する。異常検出装置は、記憶する複数のデータ値と時間情報とに基づいて一次近似直線Bを算出し、複数のデータ値に基づいて標準誤差Zを算出し、前記一次近似直線Bと前記標準誤差Zと、記憶する1つのデータ値とに基づいて危険値到達直線Dを算出する。異常検出装置は、前記危険値到達直線Dと予め設定される危険値Fとに基づいて異常を検出する。
(もっと読む)
仮想サーバの移動方法の決定方法及びその管理サーバ
【課題】
システムの現況に応じて仮想サーバの移動方法を決定することで、可用性を向上する。
【解決手段】
仮想化システムが使用する物理資源量を示す使用物理資源量、仮想化システムを稼動させる物理サーバの性能を示す最大物理資源量とからなる物理資源情報、仮想化システムが仮想サーバに割り当てている物理資源量の関係を示す割当物理資源係数、仮想サーバが使用する物理資源量の関係を示す使用仮想資源係数とからなる仮想資源情報、移動手段の実行に必要な物理資源量を示す必要物理資源量、仮想サーバの使用仮想資源係数の変化が各移動手段による仮想サーバの移動所要時間に与える影響の度合いを示す変動率、使用物理資源量を基準とした基準実行時間とからなる移動手段情報から、前記仮想サーバの物理資源の使用量、前記使用物理資源量からの使用物理資源量の変化値、前記各移動手段による仮想サーバの移動所要時間を算出する。
(もっと読む)
システム監視プログラム、システム監視方法およびシステム監視装置
【課題】トランザクションを分析して業務システムを監視すること。
【解決手段】トランザクション監視装置がトランザクション・モデルに基づいてトランザクションを監視し、モデル・マッチ率が所定の閾値より小さい場合に、マッチしなかったトランザクションを詳細に分析するようにトランザクション詳細分析装置200に指示する。すると、マッチしなかったトランザクションについてトランザクション詳細分析装置200の類似モデル検索部245が最も類似する類似モデルを検索し、トラン−類似モデル相違箇所抽出部246が類似モデルとの相違箇所を抽出し、詳細分析結果表示部251が相違箇所を強調表示する。また、システム運用者が異常でないと判断したトランザクションをモデル更新処理部247がトランザクション・モデルに追加登録する。
(もっと読む)
運用管理装置および運用管理方法ならびにそのプログラム
【課題】システムの性能劣化を正確に検知する運用管理装置、方法およびプログラムを提供する。
【解決手段】システムが正常に動作している場合の正常モデルの相関関係の崩れの分布の範囲を保持する正常モデル分布蓄積手段と、システムに異常が発生している場合の障害モデルを保持する障害モデル分布蓄積手段と、性能情報の各相関モデルの崩れの分布が正常モデルの崩れの分布の範囲内か判断する相関変化分布判別手段と、前記範囲内でないと判断された各相関モデルの崩れの分布を保持する相関変化履歴蓄積手段と、前記相関変化履歴蓄積手段に保持された前記各相関モデルの崩れの分布が前記障害モデル分布蓄積手段に蓄積された障害モデルの崩れの分布に近似していく傾向があるか判断する相関崩れ増加判別手段と、を有する。
(もっと読む)
カスケード接続メモリを使用して処理能力を評価するためのメディアキャプチャシステム、方法及びコンピュータプログラム製品
【課題】カスケード接続メモリを使用して処理能力を評価するためのメディアキャプチャシステム、方法及びコンピュータプログラム製品を提供する。
【解決手段】使用において、メディアデータが、所定の基準に従ってシステムからキャプチャされる。更に、前記メディアデータは、前記システムとは別の複数のカスケード接続メモリに記憶される。更にまた、前記メディアデータは、前記所定の基準に基づいて、前記システムのメディア処理能力を評価するのに使用される。
(もっと読む)
サービスコンポーネント管理システム、実行制御サーバ、プロファイルサーバ及びサービスコンポーネント管理方法
【課題】複数台の実行制御サーバを並列に実行したとしてもシステム全体でリクエストを監視することができ、サービスコンポーネントへのリクエスト処理量を向上することができる。
【解決手段】トラフィック情報管理サーバ14は、実行制御サーバ1,2,3から収集したトラフィック情報を集計するトラフィック集計機能部16と、集計したトラフィック情報に基づいて閉塞状態にするサービスコンポーネントを抽出するサービスコンポーネント監視機能部17と、集計したトラフィック情報に基づいて特定のサービスコンポーネントに対して一時利用不可能にするユーザを抽出するユーザ監視機能部18と、閉塞状態にするサービスコンポーネント又は一時利用不可能にするユーザをプロファイルサーバ21に通知するリアクション機能部19と、を備える。
(もっと読む)
21 - 40 / 148
[ Back to top ]