
Fターム[5E501CC11]の内容
デジタル計算機のユーザインターフェイス (127,284) | 入出力機器その他 (2,248) | 特殊な入出力機器 (1,202) | 身振り、手振り (138)
Fターム[5E501CC11]に分類される特許
101 - 120 / 138
電子ブック装置、ブックカバー装置、電子ブック処理方法、およびプログラム

【課題】従来は、紙媒体の書籍を読んでいる際に感じられるべき感覚が得られない場合があるという課題があった。
【解決手段】1以上のページを有する文書情報が格納され得る文書情報格納部101と、ユーザにより行われた紙のページをめくる動作と同様の動作を検出し、検出結果を出力する動作検出部102と、動作検出部102が出力する検出結果を用いて、ページをめくる動作が行われたことを示す情報であるユーザ動作情報を取得する動作情報取得部103と、ユーザ動作情報に応じた出力であって、ページがめくられたことをユーザに知覚させるための出力であるページフリップ出力を行うページフリップ出力部104と、文書情報格納部101に格納されている文書情報から、動作情報取得部103が取得したユーザ動作情報に応じたページの情報を読み出し、表示する文書ページ表示部105とを備えた。
(もっと読む)
操作装置及びその方法

【課題】ユーザの手形状を手モデルに忠実に反映できる操作装置を提供する。
【解決手段】指を伸ばした初期状態からの掌接触領域及び指接触領域の移動量を算出し、初期状態からの掌接触領域及び指接触領域の移動量に基づいて、CGモデルの平行移動量、回転量及び各指関節の曲がり角度を決定し、決定した平行移動量、回転量及び各指関節の曲がり角度に従って、CGモデルの変形形状を決定する。そして、変形形状が決定されたCGモデルと保持されているGUIパーツとを重畳した画像を作成して表示部に表示させ、GUIパーツとCGモデルの指先との衝突を判定し、衝突が判定されると、衝突が判定されたGUIパーツに割当てられたコマンドを機器に送信する。
(もっと読む)
改良されたジェスチャに基づく画像操作
改良された画像観察においては、ユーザのジェスチャは、第1および第2の画像から認識され、認識されたユーザのジェスチャに対応するインタラクションコマンドが決定され、そして、決定されたインタラクションコマンドに基づいてユーザインターフェースで表示される画像オブジェクトが操作される。 (もっと読む)
アニメーションキャラクターを用いる電子機器及び方法
電子機器(10)はアニメーションキャラクタ(24)をディスプレイ(14)に表示することができ、キャラクタは、ユーザの存在が検出されるとユーザに反応するために現れることができる。キャラクターは人物、動物、又は他の物体の表現であってよい。テレビ電話に用いるカメラのような撮像装置(18)によって生成される映像データストリームを解析することにより、ユーザがディスプレイを見ていることを解明する。  (もっと読む)
(もっと読む)
情報処理装置、情報処理方法、情報処理プログラム及び携帯端末装置
【課題】 カメラ部で撮像されたユーザの撮像画像に基づく所望の情報処理の指定操作を行う場合に、ユーザに対して手や顔等の部位を停止させる位置(=移動させる位置)を認識させることができ、また、適正な位置に停止している部位及び不適正な位置に停止している部位をユーザに認識させることで、上記指定操作の容易化を図る。
【解決手段】 制御部は、被写体となっているユーザの撮像画像と共に、当該ユーザのポーズを検出するための複数のガイド枠を表示部に表示し、被写体となっているユーザの部位が、ガイド枠内に位置している場合は、その部位を赤色の枠で囲んで表示し、該ガイド枠外に位置している場合は、その部位を青色の枠で囲んで表示する。当該携帯電話機のユーザは、青色の枠で囲まれた部位がガイド枠内に位置するように、被写体となっているユーザを誘導する。これにより、容易かつ迅速に所望の情報処理の指定操作を行うことができる。
(もっと読む)
操作入力装置
【課題】 ユーザーの手振りやジェスチャーをカメラで撮影してカーナビゲーション等の操作を行う場合、機器や操作対象の数が増えるに従い、それぞれに対応した手の形状や手の動きが増える。そのため、ユーザーにとって操作が複雑になるという問題があった。また、カメラで手を検出する場合に、カメラ撮影画像の中に色情報が似た顔等が入った場合や太陽光や照明の外光が変化した場合は、検出制度が低下するという問題があった。
【解決手段】 限定した手の操作判定手段とメニュー表示手段を備えることで、簡単に操作でき、かつ正確に操作を判定できるようにする。また、複数のカメラを用いて複数の判定手段から一つの結果を選択する手段を備えることにより、検出精度を高める。
(もっと読む)
電子機器の制御装置、制御方法及び制御プログラム
【課題】表示装置に表示された操作ボタンに手などをかざして操作ボタンを操作する電子機器において、ユーザーの手などの認識対象物に対する操作ボタンの表示位置を適切なものとし、その操作性を向上させる。
【解決手段】
認識情報生成部23により、ビデオカメラ2によって撮影されたユーザー3の身体の一部又はユーザー3が保持する物体である対象物を認識し、認識対象物の属性、個数、画面内における位置などを含む認識対象物情報を生成し、ビデオカメラ2によって撮影した画像を鏡像変換し、認識対象物情報に応じて、拡大、縮小又は位置の調整を行うとともに、操作用画像を生成し、操作ボタンの表示位置又は範囲を調整し、これらの混合画像を表示装置21の画面上に表示させ、画面に表示された操作者が認識対象物を用いて操作ボタンを選択する所定の選択動作を検出して、操作ボタンに対応する制御動作を行う。
(もっと読む)
リアルタイムのコンテンツのストリームと対話するための装置
【課題】ユーザが単なる観客でいることを可能にする代わりに、出力される表現と対話し、該ユーザ自身の好みに従って該表現を順応させること。
【解決手段】リアルタイムのコンテンツのストリームを出力表現に変換するエンドユーザ装置10と、ユーザが前記ストリームと対話することを可能とするユーザインタフェース30とを含む。ユーザインタフェース30は、ユーザによって為される動き及び/又は発せられる音声を検出するために対話領域36を監視するセンサ32a〜32fを含む。センサ32a〜32fは、ユーザインタフェース30が前記検出された動き及び/又は音声が生じた対話領域36内の3次元の位置を決定することができるように、対話領域36の周囲に配置される。異なるコンテンツのストリームが、検出された動き及び/又は音声のタイプと前記決定された位置とに基づいて、表現内で起動される。
(もっと読む)
車両における情報表示方法および車両用表示装置
本発明は、自動車において情報を表示する方法に関しており、ここでは自動車に固定されたディスプレイ(1)によって複数のオブジェクト(6)をグラフィックに表示する。本発明による方法の特徴は、ユーザインタフェース装置(2)によってグラフィックデータを作成し、このグラフィックデータによって上記のディスプレイ(1)を駆動制御して、上記のグラフィックオブジェクト(6)を遠近法表示される仮想のリング(5)に配置して表示し、入力装置(4)を用いた入力に応じて、上記のユーザインタフェース装置(2)の計算ユニット(3)により、前記のグラフィックデータを変更して、上記の複数のオブジェクト(6)を仮想のリング(5)上でメリーゴーラウンド状に回転させることである。さらに本発明は相応する表示装置に関する。 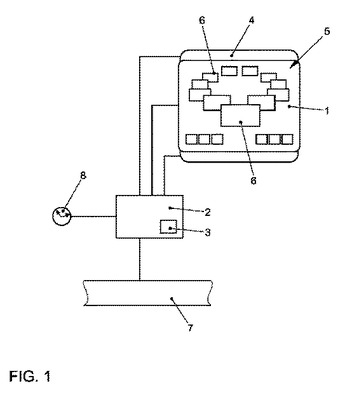 (もっと読む)
(もっと読む)
高度な語彙外単語の拒否
入力ジェスチャを、学習ジェスチャの語彙を総合的にモデル化する隠れマルコフモデルに適用することに基づいて、入力ジェスチャが学習ジェスチャの各々に適合する尤度と、最大の尤度を有すると判断されたモデル化された学習ジェスチャの対応する状態に適合する入力ジェスチャの状態量と、を決定する、語彙外単語の高度な拒否。決定された量が閾値を満たさない場合は、入力ジェスチャは拒否される。 (もっと読む)
システム、頭部装着型表示装置、その制御方法
【課題】 HMDを頭部に装着した複数人のユーザが複合現実空間を共有する場合に、HMDに対する無線での画像送信を円滑に行うための技術を提供すること。
【解決手段】 HMD10aは、HMD10aの位置と無線I/F105aの位置とを通る直線を軸とする領域を示す領域情報を生成する。他の画像処理装置11b、11cが有する無線I/Fの位置情報を取得する。取得した位置情報が示す位置が、上記領域情報が示す領域内に含まれているか否かを判断する。そして係る判断の結果に応じて、無線I/F105a、若しくは他の無線I/Fの何れかを無線通信相手として選択し、選択した無線I/Fとの無線通信により、画像を受信する。
(もっと読む)
カメラ・ベースの身振り入力を使用しての3次元映像構築のシステムおよび方法
【課題】システム利用者のカメラ・ベースの身振り入力を使用して3次元映像を構築するためのシステムおよび方法。
【解決手段】ビデオ映像表示装置は該システム利用者の前に置かれる。該システムは、更にこのシステム利用者の身体および主要身体部分の3次元位置を決定するために、上記のコンピュータが読取り可能な記憶装置に蓄積されるプログラムによりビデオ信号を処理するためのマイクロプロセッサを有する。このマイクロプロセッサは該システム利用者の身体および主要身体部分の3次元位置に基づきビデオ映像表示装置上に、該システム利用者および相互動作区域の3次元映像を構築する。該ビデオ映像表示装置はいかにもそれらが相互動作区域を占めているように見えるように重ね合わされた3次元のグラフィック対象物を示し、且つ該システム利用者による動きは、該ビデオ映像表示装置上に表示される重ね合わされた3次元対象物の見掛け上の動きを起こさせる。
(もっと読む)
プロジェクタ
【課題】プレゼンテーション等の場に参加している各人に資料を配付するのと同様に資料を提示でき、資料を提示するときの態様を明示することによって、プレゼンテーションにおける演出を高めることができると共に、資料を配付するために会議を中断することなく、プレゼンテーションを円滑に進めることができ、操作が容易なプロジェクタを提供する。
【解決手段】投影すべきコンテンツの画像の表示態様と、そのコンテンツに対する処理態様との少なくとも一方を、操作者の動作に基づいて決定して、コンテンツの画像を投影する。
(もっと読む)
携帯装置の傾斜及び並進運動成分の識別
【課題】本発明は、モーションインターフェースを有する携帯装置を提供する。
【解決手段】モーションコントロール携帯装置は、第1の軸に沿う加速度を検出する第1の加速度計と、第2の軸に沿う加速度を検出する第2の加速度計とを有する。第2の軸は第1の軸に垂直である。当該装置は、前記第1の軸及び前記第2の軸の少なくとも一方の回りの回転成分を検出するチルト検出素子と、現在の画像を表示するディスプレイとを有する。当該装置は、前記第1の加速度計、前記第2の加速度計及び前記チルト検出素子を用いて3次元での当該装置の運動を追跡するモーション追跡モジュールを含む。当該装置は前記現在の画像を生成し、当該装置の運動に応じて前記現在の画像を変更するコントローラとを有する。
(もっと読む)
医療用個体識別機
【課題】検体を特定する識別データの読取りと識別データの入力の操作性が良く、しかも検体の汚染を防止した医療用個別識別機を提供する。
【解決手段】テーブルと、前記テーブルに内蔵されたアンテナであって前記テーブルに載せられた前記検体容器の識別データを読込むアンテナと、このテーブルの後部に立設されたディスプレイ部と、ディスプレイ部の周辺に複数設けられ前方の対象物体を検知する物体検知センサと、この物体検知センサの検知信号を受けて入力信号を作成する制御部を有し、前記物体検知センサの検知距離が識別データ読込操作時の前記検体容器又は操作者の手に達しないように前記物体検知センサの検知方向を設定して、前記物体検知センサの検知信号を前記識別データの取り込み指令とする。
(もっと読む)
電子機器の制御装置
【課題】ユーザの動きの画像をディスプレイ上のメニューに重ねて電子機器の遠隔操作を行う場合、操作メニュー上のユーザ画像のサイズ、位置が最適ではないときは操作しにくい。ユーザ画像のサイズ、位置を補正する場合は、操作が煩雑になる。
【解決手段】検出部13は表示装置21の表示画面の表示領域を縦方向9個、横方向に16個の計144個の検出領域に分割し、これら分割検出領域毎にユーザ画像の手の動きの画像を検出する。制御情報判断器(CPU)20は、検出部13からの検出信号の最大幅に基づいて、スケーラ15から出力される鏡像変換画像信号によるユーザ画像の画像サイズを所定のサイズとし、かつ、検出信号の重心座標を求め、その重心座標がグラフィックス生成器16で生成される操作用画像の中心位置にくるように、スケーラ15を制御する。
(もっと読む)
視野角切り替え装置連動の広画面表示装置
【課題】従来、小型の携帯端末でWebページや文書を閲覧しようとした場合に、画面表示の幅を超えることが多く、そのために、縮小表示をすることで視認性を欠いたり、スクロール操作の必要が発生し利便性を欠いたりすること等が課題となる。また、複数の視野角においてそれぞれ異なる映像を表示できる表示装置においては、利用者が参照している以外の視野角の画面については、覗き見をされるなど、プライバシーの確保が課題として生じる。
【解決手段】以上の課題解決のため、第一に本発明は表示すべき画面が、現在表示している画面の幅を超えている場合には、これを判断し、複数視野に分割して表示する表示装置を提供する。第二に装置筐体の傾きにより、各視野角画面の濃度を選択的に調整する装置を提供する。第三に、表示装置を左右に振ることで、その加速度と傾きにより、スクロールを実行する表示装置を提供する。
(もっと読む)
画像認識システム
【課題】利用者の手や足などに発光体を装着させる必要がなく、利用者の動きを3次元的に解析して利用者の動きを詳細に反映した処理を行うことができる画像認識システムを提供すること。
【解決手段】検出ユニット16の撮像空間PSの3次元座標系において、検出対象物の3次元形状情報や3次元位置情報を取得することにより、検出対象物の形状や位置を3次元的に解析して種々の処理を行う。
(もっと読む)
マルチポイント感知装置でのジェスチャー
【課題】マルチポイント感知装置、及びそのマルチポイント感知装置でジェスチャーを実施する方法を提供する。
【解決手段】感知装置でジェスチャーを実施する方法及びシステムが開示される。より詳細には、マルチポイント感知装置でのジェスチャーに関連した方法及びシステムが開示される。
(もっと読む)
ジェスチャー/音声統合認識システム及び方法
本発明はジェスチャー/音声統合認識システム及び方法に関し、雑音環境下における音声とジェスチャーの統合を通じて命令語の認識の性能を高めるために入力された音声の中から命令語の始点と終点を検出し音声特徴情報を抽出する音声特徴抽出部と、前記検出した始点と終点に関する情報を用いて撮影映像のジェスチャーから命令区間を検出し、ジェスチャー特徴情報を抽出するジェスチャー特徴抽出部と、前記抽出された音声特徴情報とジェスチャー特徴情報を既設定の学習パラメーターを用いて統合認識データとして出力する統合認識部を含んで構成され、簡単に、且つ正確にユーザーの命令を認識することができる。  (もっと読む)
(もっと読む)
101 - 120 / 138
[ Back to top ]