
Fターム[5L096AA09]の内容
イメージ分析 (61,341) | 分析対象画像の物理的性質 (6,787) | 3次元画像 (415)
Fターム[5L096AA09]に分類される特許
121 - 140 / 415
表面特性を用いて対象物の特定および/または認証をするための方法、および、その方法に使用するセンサ
本発明の主題は、表面特性を用いて、対象物の特定および/または認証をするための方法である。本発明のさらなる主題は、表面を走査するためのセンサである。 (もっと読む)
画像処理装置および方法
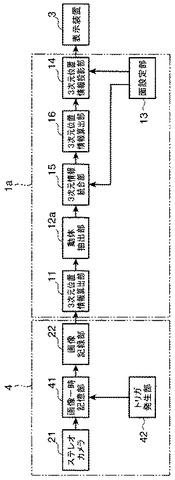
【課題】ドライブレコーダの撮像画像を表示装置に表示させる画像処理装置において、動体の動きを使用者が容易に理解できるようにする。
【解決手段】ドライブレコーダからの時系列のステレオ撮像画像から、3次元位置情報算出部11が3次元位置情報を算出し、動体抽出部12aが同一の動体を抽出する一方、面設定部13からは、使用者が表示にあたって所望とする投影面、すなわち視線方向を設定し、これに応じて3次元位置情報統合部15が、その設定された投影面での時系列画像を統合し、3次元位置情報算出部16が、その統合した画面における動体の各位置を算出し、3次元位置情報投影部14が表示装置3に表示させる。したがって、時系列の3次元撮像画像から解析した動体の動きを、運転者の目線や、事故の目撃者の目線から見た画像に変換して表示することができ、前記動体の動きを使用者が容易に理解することができる。
(もっと読む)
通行者計数装置、通行者計数方法および通行者計数プログラム

【課題】通行者数を正確に計測する。
【解決手段】最高点選出部によって判断対象画像TG1の最高点HMAが選出される。選出された最高点HMAから所定の高さ(例えば、高さ0の床面)まで鉛直下方に向けて所定の間隔毎に、閉領域HR1における水平面に平行なスライス画像が保持部によってそれぞれ抽出され保持される。そして、最高点HMAから所定の間隔(例えば、150mm)だけ低い位置におけるスライス画像内の判断対象画像の面積に基づいて、当該判断対象画像が通行者を示す画像であるか否かが通行者認識部により認識される。
(もっと読む)
可変姿勢を含む画像シーケンスのリアルタイム利用可能なコンピュータ支援分析方法
本発明は、互いに関して可動な相互接続された複数要素からなる物体の可変姿勢画像シーケンスのリアルタイム利用可能なコンピュータ支援分析方法に関する。画像シーケンスの個別画像が、コンピュータによって処理されること並びにシーケンスの各画像に対するカメラのピクセル座標の関数として明暗及び距離データを有するべく飛行時間(TOF)カメラによって記録される。本方法は、a.物体を形成する個別画像のピクセルを取得するステップと、b.カメラに可視の物体の表面を表す仮想空間内の3次元(3D)点集合を、物体からの距離について取得されたデータを考慮に入れた物体マッピングピクセルの空間への計算機投影によって計算するステップと、c.物体の複数要素の一選択を表す複数ノードと要素の相互接続を表す複数エッジとからなる物体のモデルを、個別画像に対してコンピュータ生成された3D点集合にフィッティングするステップと、d.点集合についてランダムにサンプリングされた所定数の点を有する自己組織化マップを訓練する学習ルールを適用してすべてのノード位置を逐次更新するステップと、e.シーケンスの各後続個別画像に対してステップ(a)から(d)を繰り返すステップであって、先行フレームのステップ(e)の結果がステップ(c)でのフィッティングのプロセスを目的として使用されるステップと、f.画像シーケンスの少なくとも代表画像において取得された、モデルの所定ノード位置からの変化姿勢を決定するステップとを含む。  (もっと読む)
(もっと読む)
三空間入力の検出、表現、および解釈:自由空間、近接、および表面接触モードを組み込むジェスチャ連続体
三空間入力を検出し、表現し、解釈するシステムおよび方法について記載する。SOEのコンテキストにおける本システムの実施形態は空間追跡データの複数のソースからの低レベル・データを処理し、これら意味的に相関付けられていない空間時間データを分析し、動的に構成変更可能な暗示的および明示的ジェスチャ記述にしたがって高レベルジェスチャ・イベントを発生する。これら生成されたイベントは、インタラクティブ・システムによる消費に適しており、本実施形態は、これらのコンシューマへのイベント配信を制御および実行する1つ以上のメカニズムを設ける。更に、本実施形態は、そのイベントの消費者に、任意の空間および意味的基準フレーム間においてジェスチャ・イベントを変換する機能を提供する。 (もっと読む)
ロボットの少なくとも1つの将来的活動を決定する決定メカニズム、方法、モジュールおよび決定するように構成されたロボット
【課題】ロボットによるシーンの自立的探索のための方法を改善することである。
【解決手段】本発明は決定メカニズムに関する。この決定メカニズムは、ロボットの少なくとも1つの将来的活動を前記ロボットの複数の活動から、前の環境状態の前の確率論的表現を計算し、前記少なくとも1つの将来的活動が適用された後に、達成すべき後の環境状態の後の確率論的表現における少なくとも1つの不確定性を低減する新たな観察を目的として、前記前の確率論的表現を更新し、ただし前記後の確率論的表現は前記更新から生じた確率論的表現であり、前記前の確率論的表現と前記後の確率論的表現との間の情報利得を、少なくとも1つの情報理論的測定を使用して決定し、そして前記少なくとも1つの将来的活動を、当該少なくとも1つの将来的活動の実行コストを前記情報利得に加算することにより評価することによって決定するように構成されている。
(もっと読む)
3次元情報表示装置および3次元情報表示方法
【課題】本発明は、任意の画像を基準とし時系列画像の動体対応画像部分を統合して表示できる3次元情報表示装置及び該方法を提供する。
【解決手段】本発明は、複数の時系列画像を生成するステレオカメラ1と、時系列画像を順次記憶していき所定量の時系列画像を記憶すると最も古い画像を消去する画像記録部6と、作動した場合には画像記録部6に所定の時刻以降の前記時系列画像の消去を停止するように指示するトリガー13と、立体情報を取得する立体情報取得部と、時系列画像及び立体情報を基に、時系列画像の3次元画像情報を算出する3次元画像情報算出部7と、時系列画像中の動体対応画像部分を特定する動体特定部8と、3次元画像情報を用いて前記動体対応画像部分について時系列画像中、何れかの画像を基準とした3次元座標を算出する演算部10と、3次元座標に基づいて前記動体対応画像部分が基準画像に統合された画像を表示する表示装置5とを備える。
(もっと読む)
鏡面反射物体の3D姿勢を推定する方法
【課題】物体の3D姿勢を推定することに関し、より詳細には鏡面反射物体の3D姿勢を推定する。
【解決手段】方法が、環境内の3D鏡面反射物体の3D姿勢を推定する。前処理ステップにおいて、物体の3Dモデル及び該物体の姿勢のセットを使用して2D基準画像対のセットを生成する。各基準画像対は姿勢のうちの1つに関連付けられる。次に、物体の2D入力画像対を取得する。2D入力画像対内の特徴と各2D基準画像対内の特徴とを、概算コスト関数を使用して比較することによって物体の大まかな3D姿勢を推定する。概算推定値を、精密コスト関数を使用して精緻化する。
(もっと読む)
立体物判定装置、立体物判定方法及び立体物判定プログラム
【課題】取得した画像に含まれている物体が、立体物かどうかを精度よく判断できること。
【解決手段】立体物判定装置は、取得した画像データに含まれる物体の複数の特徴点を検出する検出部2と、前記複数の特徴点を3次元モデルで正規化した正規化パターンを生成するパターン正規化部5と、3次元モデル及び正規化パターンから画像データ中の前記物体に照射されている光の照明方向を推定する推定部6と、前記照明方向を用いて画像データ中の物体が立体物であるかを判定する判定部7と、を備える。
(もっと読む)
衝突判断処理システム、コンピュータプログラムおよび風力発電装置
【課題】 三次元空間を移動する物体が所定領域に対して所定時間内に到達するか否かを判断するためのシステムにおいて、演算処理の複雑さを回避してリアルタイム処理の実現を図る。
【解決手段】 所定の空間領域(11)を異なる方向から同期させて連続撮影する左カメラ(12L)と右カメラ(12R)を備えた撮影手段と、その左側画像データおよび右側画像データの高さ方向を予め同一に設定するとともにその画面縦方向の上下に予め設定した許容範囲に限って粒子(15)の対応付けを実行して三次元データを作成するステレオマッチング手段(14)と、その三次元データの粒子(15)と次の時刻の粒子(15)の中で最短距離の粒子(15)を対応付ける時刻間対応付け手段と、その二つの時刻間の粒子(15)で三次元速度ベクトル(16)を算出する速度ベクトル算出手段と、その速度ベクトル(16)が予め設定した対象領域(17)へ所定時間内に到達するか否かを判断する衝突判断手段と、を備える。
(もっと読む)
特徴を抽出する装置、方法およびプログラム
【課題】高い識別性能を有する特徴量を抽出する。
【解決手段】複数の画像間で相互に対応する部分画像を検出する検出部113と、複数の部分画像ごとおよび部分画像に含まれる画素ごとに画素特徴量を算出する画素特徴算出部104と、部分画像ごとに、部分画像内の複数の画素それぞれに対して算出された複数の画素特徴量の共起頻度を算出し、算出した共起頻度を含む特徴量を表す画像内特徴量を算出する画像内特徴算出部105と、複数の部分画像それぞれに対して算出された複数の画像内特徴量を含む特徴量を表す画像特徴量を生成する生成部107と、を備える。
(もっと読む)
物体認識装置および方法
【課題】 単一カメラ画像から物体の形状を、正確かつ短時間に効率よく認識することのできる物体認識装置および方法を実現することを目的とする。
【解決手段】 対象物の形状の学習画像を作成する学習画像生成部と、前記学習画像生成部にて作成された学習画像のそれぞれを固有空間上の特徴点として投影する処理を行う学習処理部と、前記学習画像の特徴点の情報を保存する学習データ部と、対象物の画像を入力し、該入力された対象物の画像を固有空間上の特徴点として投影処理を行い、前記学習データ部に保存されている前記学習画像の特徴点の情報の中でもっとも近い情報を検索して出力する認識処理部と、を備える。
(もっと読む)
視線認識装置
【課題】測定対象物を視聴している視聴者を正確に計測することのできる視線認識装置を提供する。
【解決手段】座標系に対する瞳孔の位置および角膜反射点を測定するための赤外線カメラ1と、前記座標系の既知の位置に配置され前記瞳孔の位置および角膜反射点を測定するための赤外線光源7と、前記各カメラで測定し視聴者の瞳孔の位置および角膜反射点の位置の情報をもとに視線方向が評価対称ディスプレイの方向を向いている視聴者を判別する視線測定部2と、判別した視聴者の視線方向が前記評価対象ディスプレイに向いている回数または前記評価対象ディスプレイに向いている時間を積算する視聴者情報作成部3と、作成された前記視聴者情報を格納する視聴者情報記憶部4を備えた。
(もっと読む)
画像情報の自動的分類を行う方法
この方法は、1台のコンピュータまたは複数台の連結コンピュータが、a)分類すべき第1の画像を画素の集合の形で、その集合の中の各画素を光の強さの少なくとも1チャネル内の画像情報に関連付けて、デジタル記憶媒体上に記憶するステップと、b)画像の第1の分類を各画素の画像情報に基づいて行い、またこの分類により各画素をクラスの第1の集合内の或るクラスに関連付け、これらの関連を第1のデータベース内に記憶するステップと、c)画素毎にまたクラスの第1の集合内の複数のクラス毎に、問題の画素と、データベース内の問題のクラスに関連付けた最も近い画素との間の画像内の最短距離を計算し、各画素とその画素について計算した最短距離との間の関連を、距離を計算したクラス毎に第2のデータベース内に記憶するステップと、d)第2のデータベース内のデータの第2の分類を、画素毎にそれぞれのクラスまでの最短距離に基づいて行って、各画素とクラスの第2の集合内の或るクラスとを関連付けるステップと、e)分類した画像を画素の集合の形でデジタル記憶媒体上に記憶し、各画素はその画素とクラスの第2の集合内の或るクラスとの関連に関するデータを含み、また分類した画像は第1の画像と同じ次元を有するステップと、を含むことを特徴とする。  (もっと読む)
(もっと読む)
テンプレート生成システム、テンプレートマッチングシステムおよびテンプレート生成方法
【課題】姿勢が不安定なテンプレートの生成を抑制し、生成したテンプレートを記憶する記憶容量を低減する。
【解決手段】テンプレート取得部110は、ワーク130の設計データを取得するCADデータ取得部112と、取得した設計データに基づいてワーク130の形状を抽出する形状抽出部114と、抽出した形状を複数の姿勢で平面に射影した複数の射影像を生成する射影部116と、複数の姿勢のそれぞれに応じて形状の姿勢を仮想的に変化させ、前記形状の姿勢が復元する結果に基づいて、ワーク130が複数の姿勢毎に載置された場合の安定度を算出する安定度算出部120と、複数の射影像のそれぞれに応じたテンプレートを生成するテンプレート生成部118と、生成したテンプレートを安定度と共に記憶するテンプレート記憶部122と、を備える。
(もっと読む)
ジェスチャー認識のための方法及びシステム
【課題】 本発明は、ジェスチャー認識のための方法及びシステムを提供することを課題とする。
【解決手段】 関心のあるジェスチャーを認識する方法は、関心のあるジェスチャーをするように対象者に指示し、動きをする前記対象者の複数の画像をセンサから取得し、前記複数の画像が各々取得されると、該複数の画像の各々と前記関心のあるジェスチャーとを比較し、前記比較に基づき追跡得点を決定し、該追跡得点が所与の閾値内にあるとき、前記対象者が関心のあるジェスチャーを行っていると決定することを含む。
(もっと読む)
画像処理装置および方法並びにプログラム
【課題】人体と寝台等の人体以外の被写体とが接触していても、医用画像において、人体の領域とそれ以外の領域とを分離する。
【解決手段】画像取得部1が、被写体の頭部を複数の切断位置で切断したときの各輪切の画像からなる複数のCT画像を取得する。多値化部2が、複数のCT画像のそれぞれを多値化して多値化画像を生成し、結合部3が、多値化画像の連結成分同士を結合する。削除部4が、CT画像から人体以外の領域を削除し、疑似3次元医用画像生成部5が、人体以外の領域が削除されたCT画像の人体の領域を表す画像情報に基づいて、例えばminIP法を実行することにより疑似3次元医用画像を生成する。表示部6が、疑似3次元医用画像生成部3により生成された疑似3次元医用画像を表示する。
(もっと読む)
視覚的目標追跡
目標を追跡する方法は、ソースから目標の観察された奥行き画像を受け取ること、及び目標のポーズをとらせたモデルを得ることを含む。モデルは合成された奥行き画像へとラスタライズされ、モデルの姿勢は、観察された奥行き画像と合成された奥行き画像の間との間の差に少なくとも部分的に基づいて調節される。 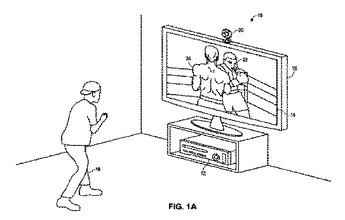 (もっと読む)
(もっと読む)
人体検出装置
【課題】検出位置によって距離画像での見え方が変化する人体を検出対象とする場合でも人体を確実に検出することが可能な人体検出装置を提供する。
【解決手段】人体検出装置Aは、検出空間Rを撮像した距離画像の距離値から各画素の距離勾配方向を求め、勾配方向値を画素値とする勾配方向画像を生成する勾配画像生成手段3と、検出空間R内の複数の検出位置に所定の人体モデルが存在する場合の距離画像での見え方を示した複数の基準距離画像が予め求められ、複数の基準距離画像をそれぞれ微分して得た複数の基準勾配方向画像を記憶する基準勾配方向画像記憶手段4と、勾配画像生成手段3により生成された勾配方向画像と勾配方向画像内の検出位置に応じて基準勾配方向画像記憶手段4から読み込んだ基準勾配方向画像との相関を表す類似度を算出するとともに、この類似度に基づいて基準勾配方向画像との一致度合いを評価する評価手段5とを備える。
(もっと読む)
画像からの深度マップの作成
複数の画像に対して複数の深度マップを生成する方法は、第1の画像を受信するステップと、前記第1の画像により規定されるショットに関する情報を取得するステップと、第1のスキーマによって前記第1の画像に対する深度マップを生成するステップと、第2の画像を受信するステップと、前記第2の画像により規定されたショットに関する情報を取得するステップと、前記第1の画像と前記第2の画像との間の前記取得された情報の変化を検出するステップと、第2のスキーマによって前記第2の画像に対する深度マップを生成するステップとを有し、前記第2のスキーマは、前記第1のスキーマの複雑さとは異なる複雑さを持つ。前記方法は、第1及び第2の深度モデルにアクセスするステップを有することができる。一実施例において、前記第1のスキーマは、前記第1の深度モデルを有し、前記第2のスキーマは、前記第2の深度モデルを有し、第2の実施例において、前記第1のスキーマは、前記第1の深度モデルを有し、前記第2のスキーマは、前記第1及び第2の深度モデルの組み合わせを有する。  (もっと読む)
(もっと読む)
121 - 140 / 415
[ Back to top ]