
Fターム[5B042MC15]の内容
デバッグ、監視 (27,428) | 表示又は記録する内容 (5,146) | エラー情報、障害情報 (726)
Fターム[5B042MC15]の下位に属するFターム
エラー種別 (46)
エラーメッセージ (99)
エラー発生箇所、故障装置名 (80)
Fターム[5B042MC15]に分類される特許
21 - 40 / 501
情報処理装置、画像形成装置、およびプログラム
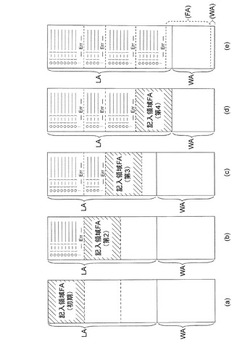
【課題】障害等の発生により装置の再起動が行われた際に、再起動前の装置の動作に係わる情報のうち障害に係わる動作の履歴を保護する。
【解決手段】制御部は、読み書き可能であって記憶している情報を保持することが電源を供給しなくても可能な不揮発性メモリに演算に用いる情報を記憶する不揮発性RAMと、不揮発性RAMに設けられる記入領域AF(初期)に動作に係わる情報の履歴である履歴情報を循環して記憶させ、障害が発生した場合に障害に係わる障害履歴情報に対してフラグ情報を付与し、再起動後にはフラグ情報が付与される障害履歴情報が記憶される記入領域AF(初期)とは異なる不揮発性RAMの新たな記入領域FA(2回目)に新たな履歴情報を循環して記憶させるCPUとを備える。
(もっと読む)
ネットワーク端末故障対応システム、端末装置、サーバ装置、ネットワーク端末故障対応方法及びプログラム

【課題】 ネットワーク端末の様々な故障に柔軟に対応し、誰でも手軽に使いこせるネットワーク端末の故障対応技術を提供する。
【解決手段】 端末装置102は、プログラム制御方式の制御手段103、制御手段の動作異常を検出する検出手段104、制御手段103の動作異常が検出されたときにその異常の内容を示す異常情報をサーバ装置101に宛てて送信する異常情報送信手段105、サーバ装置101から返送されるプログラムを受信するプログラム受信手段106、受信されたプログラムで制御手段103のプログラムを書き換える書き換え手段107を備え、サーバ装置101は、異常情報を分析する分析手段108、分析結果に基づいて異常の内容に応じた修正用のプログラムを読み出す読み出し手段110、読み出されたプログラムを端末装置102宛てに送信するプログラム送信手段111を備える。
(もっと読む)
IT障害検知・検索装置及びプログラム
【課題】監視イベントの属性値に変化が発生した場合でも、過去に発生した類似のIT障害イベントを精度よく検索可能にする。
【解決手段】IT障害を監視する監視サーバが生成した監視イベントを逐次取得し、一つの原因よって発生した単数又は複数のイベントから構成されるIT障害イベントブロックを作成する。次に、IT障害イベントブロックのイベントに頻出する属性値をもとに特徴情報を求め、その変化内容と発生時間を変化テーブルに記録する。その後、特徴情報に基づいてIT障害イベントブロックを検索する。この際、変化テーブルを参照し、検索対象とする時間範囲に応じて検索処理で使用する特徴情報の内容を補正する。
(もっと読む)
情報処理装置、処理システム、処理方法、及びプログラム
【課題】様々なノウハウの蓄積が可能となり、またより適切な対処方法をユーザに提供することが可能な情報処理装置等を提供する。
【解決手段】コンピュータ2Aは成膜装置20Aに関する情報を処理する。コンピュータ2Aは、成膜装置20Aに異常が発生した場合に、発生した異常に関する異常情報を表示する。コンピュータ2Aは、発生した異常に対処した際の対処情報を受け付ける。コンピュータ2Aは、受け付けた対処情報を、発生した異常を特定するための異常特定情報に対応付けて記憶する。コンピュータ2Aは記憶した異常特定情報及び対処情報を、サーバコンピュータ1へ出力する。成膜装置20Bに異常が発生した場合、コンピュータ2Bは異常特定情報に対応する対処情報をサーバコンピュータ1から受信し、表示する。
(もっと読む)
複合装置、保守情報提供方法、および、保守情報提供プログラム
【課題】保守作業にかかる時間を短縮する。
【解決手段】複合装置10は、保守対象装置(1)11〜保守対象装置(3)13と、保守対象装置(1)11〜保守対象装置(3)13のそれぞれに設けられた表示部14〜16と、保守対象装置(1)11〜保守対象装置(3)13において発生する事象を検出する検出部17と、検出部17が検出した発生事象のログに、この発生事象の影響を受ける可能性のある保守対象装置が関連装置として対応付けられた情報を格納するログ記憶部18と、ログ記憶部18から、検出部17が検出した発生事象の発生元の保守対象装置が関連装置として対応付けられているログを抽出する抽出部19と、検出部17が検出した発生事象の発生元の保守対象装置に設けられた表示部に、抽出部19が抽出したログを表示させる表示制御部20と、を有する。
(もっと読む)
ログ解析装置
【課題】 分散制御システムに対し、制御装置が出力するログを解析することにより、不具合の原因箇所の特定を効率的に行うことができるログ解析装置を得る。
【解決手段】 解析対象となる対象制御装置が制御対象とする制御対象装置の種類および数と一致するか否かにより類似度を算出し、類似度が最大となる制御装置を比較制御装置として特定するログ比較装置特定部34と、ログ保存部24から対象制御装置および比較制御装置が出力した時刻情報が一致するログをそれぞれ対象ログおよび比較ログとして抽出するログ抽出部35と、対象ログおよび比較ログのデータを比較して対象ログの重要度を演算するログ重要度演算部42と、ログ重要度演算部42が演算した重要度を対象ログに挿入するログ重要度挿入部37とを備える。
(もっと読む)
管理装置およびプログラム
【課題】情報処理装置において不具合を発生させる可能性が高いソフトウェアとハードウェアの組み合わせを特定する。
【解決手段】サーバ装置20は、画像形成装置10から取得した不具合情報に基づき、不具合が発生した画像形成装置10が有する設備及び制御プログラムの組み合わせを不具合の内容ごとに分け、各々の制御プログラムとの組み合わせに含まれる設備のうち、第1の閾値以上の数の組み合わせに含まれる設備を特定する。さらに、サーバ装置20は、特定された設備と各々の制御プログラムとの組み合わせのうち、画像形成装置10において不具合が発生した数が第2の閾値以上である組み合わせを、不具合の内容ごとに特定する。この組み合わせが、画像形成装置10において不具合を発生させる可能性が高いソフトウェアとハードウェアの組み合わせである。
(もっと読む)
エラー検出処理装置及びプログラム
【課題】どのようなことが原因でエラーになったのかをより具体的に知らせることができ、エラーに対する適切な対応を促進できるようにする。
【解決手段】CPU11は、処理中にエラーが発生された場合に、ログファイルM2を参照し、そのエラーの発生時点から遡った複数のログ情報の中から事象を取得して組み合わせ、その複数の事象に基づいてエラー解析データベースM3を検索することにより、該当する一連の事象に対応付けられているエラー原因メッセージを取得して表示部15から表示させる。
(もっと読む)
障害予測サーバ、障害予測システム、障害予測方法及び障害予測プログラム
【課題】簡単に適切な障害予測を行うことを目的としている。
【解決手段】稼働情報に含まれる情報の項目が設定された項目情報と、稼働情報が障害の予兆を示すか否かを判断するために用いる閾値とが格納された記憶手段と、稼働情報データベースに格納された最も新しい稼働情報を取得する最新稼働情報取得手段と、項目情報に基づき、最新稼働情報と項目情報に設定された項目の値が等しい稼働情報を稼働情報データベースから抽出する情報抽出手段と、最新稼働情報における所定項目の値と抽出された稼働情報における所定項目の値との差分と閾値とに基づき、障害予測に関する通知情報を作成する通知情報作成手段と、を有する。
(もっと読む)
ログ収集システム、装置、方法及びプログラム
【課題】端末装置の稼働状況を遠隔でリアルタイムに監視する際に、端末装置のログ情報の収集管理及び設定の手間を軽減する。
【解決手段】端末機器とサーバ装置とを備え、端末機器は、ログ情報を収集し蓄積するログ収集蓄積手段と、蓄積したログ情報を解析し、異常状態を検出する異常検出手段と、異常状態を検出すると、サーバ装置に異常状態を通知する異常通知手段とを含み、サーバ装置は、端末機器に蓄積されたログ情報を収集するログ収集手段と、通知された異常状態を解析する異常解析手段と、異常状態の内容に応じて、異常検出手段に対して異常状態の検出方法の設定を指示する異常検出指示手段と、ログ収集蓄積手段に対して収集し蓄積するログ情報の粒度及び内容と収集し蓄積する頻度との設定を指示する端末ログ収集蓄積指示手段と、ログ収集手段に対して端末機器から収集するログ情報の内容と収集頻度との設定を指示するログ収集指示手段とを含む。
(もっと読む)
情報処理システム及び情報処理方法
【課題】本発明は、情報処理システム及び情報処理方法に係り、統合装置内での異常時に外部装置が行う退避処理を必要最小限に抑えることにある。
【解決手段】統合装置内の各内部装置に、他の内部装置とは異なる条件で異常判定を行わせると共に、異常判定時に共通処理部に対してハードウェア資源(HW)のフェールセーフ(FS)要求を通知させる。共通処理部に、内部装置からのFS要求の通知を受けた場合に、他の内部装置に対してHWのFS動作を事前に通知させる。内部装置に、共通処理部からの事前通知を受けた場合に、共通処理部に対してHWのFS動作許可を通知させると共に、協調処理を行う外部装置に対して、HWのFS動作及び異常が自内部装置と他の内部装置との何れに起因するのかを通知させる。また、共通処理部に、内部装置からのFS要求の通知を受けかつFS動作許可の通知を受けた場合に、HWをFS動作させる。
(もっと読む)
障害解析情報収集装置
【課題】主記憶装置やHDD装置に一時的に不具合、誤動作が発生した場合においても、再起動後に障害情報を可能な限り収集することができる障害解析情報収集装置を得ることを目的とする。
【解決手段】障害解析情報収集装置100は、主記憶装置5と、バックアップメモリ2と、HDD6とを有し、
障害発生時に、主記憶装置5に記録されている主記憶情報を、ダンプファイル13としてHDD6に設けた主記憶情報記録領域に保存する主記憶情報記録手段9と、CPUレジスタ3やI/Oレジスタ4の値をバックアップメモリ2に設けたH/W情報記録領域12に保存するハードウェア情報管理手段8と、障害発生後に装置100を再起動した後で、保存されている主記憶情報及びハードウェア情報を結合して解析ファイル14としてHDD6に保存する障害情報管理手段11とを備える。
(もっと読む)
保守運営システム
【課題】障害発生以前に得られる情報を利用して、保守サービスの効率化を図る。
【解決手段】保守運営システム100は、ユーザシステム200に接続されている遠隔監視装置201からの情報に基づきユーザシステム200での障害発生確率を計算するユーザ状況管理システム101から障害発生確率情報を入力し、障害発生確率に基づき、サービス員を割当てるユーザシステム200を選択し、サービス員の派遣スケジュールを参照し、割当て対象として選択したユーザシステム200にサービス員を割当てて、サービス員の派遣スケジュールを生成する。
(もっと読む)
情報処理装置、プログラム不正検知方法、およびプログラム不正検知プログラム
【課題】アプリケーションプログラムを修正することなく、当該プログラムの不正検知および警告処理を適切に行なうことが可能な情報処理装置、プログラム不正検知方法、およびプログラム不正検知プログラムを提供する。
【解決手段】情報処理装置101は、アプリケーションにおいて呼び出された呼び出し関数が、不正コーディング検知ライブラリ10における所定の関数に対応するか否かを判定するための関数判定部21と、呼び出し関数が所定の関数に対応すると判定した場合には、不正コーディング検知ライブラリ10における所定の関数を実行することにより、呼び出し関数の呼び出し元が所定の条件を満たすか否かを判定し、呼び出し元が所定の条件を満たす場合に警告処理を行なうための警告処理部22とを備える。
(もっと読む)
障害調査情報資料採取システム、管理サーバ、障害調査情報資料採取方法およびそのプログラム
【課題】発生した障害の種類に応じて、その発生原因の特定に必要な資料の採取を適切に行うことを可能とする障害調査情報資料採取システム等を提供する。
【解決手段】管理サーバ10が、監視対象サーバ20から障害が発生した旨の障害情報を受信した際に、障害時採取情報データ113から障害名に対応して監視対象サーバから採取する障害資料の種類を取得して決定する障害診断部101と、障害資料の種類に対応する採取方法とこれによって監視対象サーバに発生する影響とを採取対象障害資料データ112から取得する採取資料判断部104と、障害資料の種類と採取方法および影響を監視対象サーバの現在の状態と比較してこの障害資料が取得可能であるか否かを判定する障害資料管理部105と、取得可能であると判定された障害資料を監視対象サーバから取得する障害資料要求部103とを有する。
(もっと読む)
デバイス監視サーバー、管理方法、およびプログラム
【課題】 従来、システム内で発生した障害に関して、その障害の放置が抑止されつつ、柔軟な情報管理が行われるような管理手法が提供されていなかった。
【解決手段】 そこで、本発明のデバイス監視サーバーは、障害が発生したネットワークデバイスのデバイス情報と該障害に関する情報とを含むメッセージを第1の宛先情報に基づき通知し、所定の監視期間を過ぎても前記ネットワークデバイスで同じ障害が検出された場合に、該障害が放置されたことを示すメッセージを第2の宛先情報に基づき通知し、第1の宛先情報への通知メッセージには、第2の宛先情報に基づく通知が行われる時間や、第2の宛先情報に対応する管理者に対してメッセージを通知するためのメッセージフォーム画面を提供するためのURL情報などが含まれることを特徴とする。
(もっと読む)
監視装置、監視システムおよび監視方法
【課題】異常を早期に回復させることを課題とする。
【解決手段】スイッチは、自装置またはストレージ装置で異常を検出した場合に、検出した異常の内容を含む異常情報を監視サーバに送信する。監視サーバは、スイッチまたはストレージ装置の異常情報を受信し、受信した異常情報に基づいて異常が生じたスイッチまたはストレージ装置を特定する。さらに、監視サーバは、異常が生じたスイッチまたはストレージ装置の動作情報と装置情報、および、異常が生じていないスイッチまたはストレージ装置の動作情報と装置情報を取得する。その後、監視サーバは、取得した動作情報と装置情報とに基づいて、異常原因を特定する。
(もっと読む)
共用リソース管理システム及びリソース管理サーバ装置
【課題】共用リソースを配備する情報処理センタの可用性を向上させる。
【解決手段】構成カタログ140には、リソースを構成要素とするシステムの構成が掲載されている。センタ管理者は適当な入力手段によりその内容を更新することができる。機能モジュール150は、サーバ(1000〜5000)を構成している各リソースの状態情報及び障害情報を機能モジュール120に通知する。機能モジュール150は、この状態情報及び障害情報を前記各サーバを構成している各リソースから得る。機能モジュール120は、機能モジュール150から通知された状態情報及び障害情報を収集し、データベース110に保存する。機能モジュール130は、前記状態情報及び障害情報を参照しながら前記リソースを組み替えて、構成カタログ140に要求されたシステムを構築するための計算を行うと共に結線も含めて該システムを構成するハードウェアの実装を行う。
(もっと読む)
ディスクアレイ制御装置及びそのダンプファイル採取方法
【課題】本発明は、信頼性を向上させ得るディスクアレイ装置を提案する。
【解決手段】ホスト計算機から送信されるデータを物理ディスクに読書きすると共に、ログデータを不揮発性メモリに格納する第1の制御部と、前記第1の制御部の動作内容が記憶されるメモリと、外部記憶媒体を接続するためのコネクタと、障害が発生したときに押下されるスイッチと、前記コネクタに前記外部記憶媒体が接続されていることを条件に、前記メモリに記憶されている前記第1の制御部の動作内容をダンプファイルとして直接前記メモリから採取して、前記コネクタを介して前記ダンプファイルを前記外部記憶媒体に格納する第2の制御部とを備えることを特徴とする。
(もっと読む)
相互監視システム
【課題】複数のサーバから構成される相互監視システムにおいて、障害発生時に、障害ログが失われてしまうという事態が発生しないようにする。
【解決手段】各サーバ10A,10B,20A,20Bは、他のサーバに対して定期的に状態確認要求を送信し、この状態確認要求に応答して上記他サーバから状態確認応答が返信されたか否かに基づいて、上記他サーバの死活を判定する死活監視部を備える。更に、各サーバ10A,10B,20A,20Bは、自サーバに発生した障害を検出して他サーバに対して障害発生通知を送信し、上記他サーバからの障害発生通知を受信することにより上記他サーバに対してログ要求を送信し、ログ要求を受信することにより要求元のサーバに対して自サーバのログを送信し、ログを受信することにより、このログを記憶部に記録するイベント監視部を備える。
(もっと読む)
21 - 40 / 501
[ Back to top ]